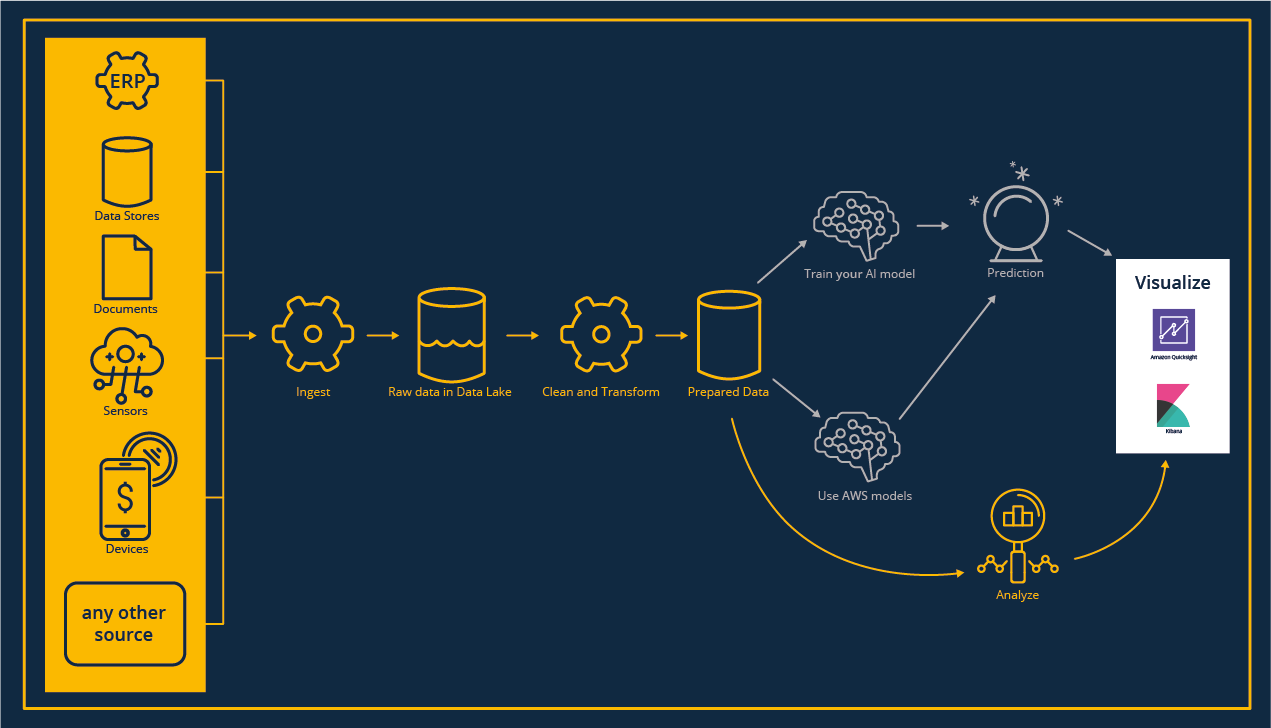
Data Analytics
„Data is a precious thing and will last longer than the systems themselves.“ – Tim Berners-Lee, inventor of the World Wide Web.


Wir leben in einer Welt, in der Daten allgegenwärtig sind und unsere Systeme von ihnen überflutet werden. Um sie nutzbar zu machen und ihr Potenzial zu entfalten, müssen wir sie zunächst erfassen, aufbewahren und zentral zugänglich machen.
Ganz gleich, ob du mit neuen Usecases loslegen willst und dabei vorhandene Daten in die Cloud migrieren musst, oder ob du automatisierte Pipelines einrichten willst, um einen kontinuierlichen Datenfluss in die Cloud-Umgebung herzustellen: der Prozess der Dateneinspeisung ist immer notwendig.
Für jeden Workload, egal ob Streaming, IoT oder Batch-Verarbeitungen gibt es den passenden Service.
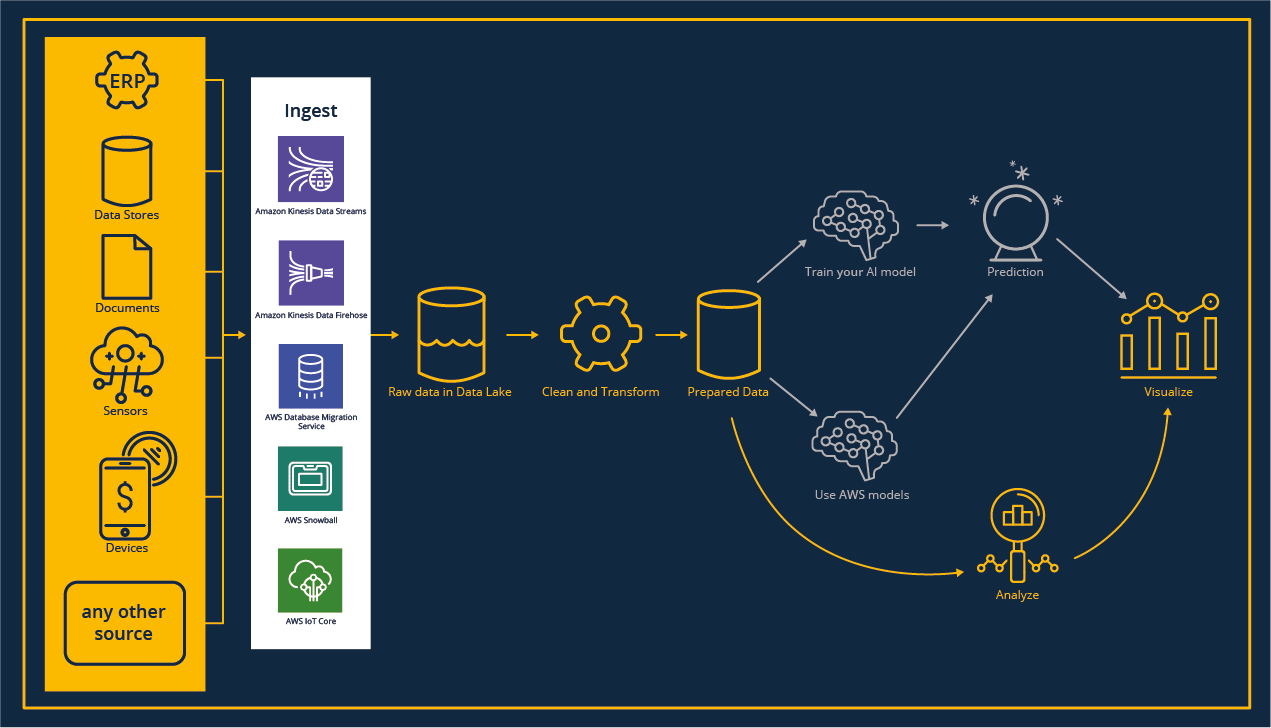
Projektreferenz „Ingest“

Die Einrichtung eines zentralen Repositorys für Rohdaten führt zu einer Vielzahl von Möglichkeiten für Data Analytics und Machine Learning Anwendungsfälle. Das Data Lake-Konzept bietet viel Flexibilität bei der Erstellung brandneuer Analysen, der Untersuchung von Daten, um Korrelationen zwischen Datensätzen zu finden und dient als Backup im Transformationsprozess, wenn Ausreißer in den Ergebnissen interpretiert werden müssen.
Wenn du an Informationen über Data Lakes interessiert bist, lies bitte unser Whitepaper. Die Nutzung eines Data Lake ist beides: Eine große Chance, aber auch ein Risiko für Dateneigentümer, insbesondere wenn es um GDPR-bezogene Daten geht. Wir, als tecRacer, haben viel Erfahrung mit dem Aufbau eines Data Lakes, der Strukturierung von Datenformaten und dem Zugriff der Daten auf Zeilenebene.
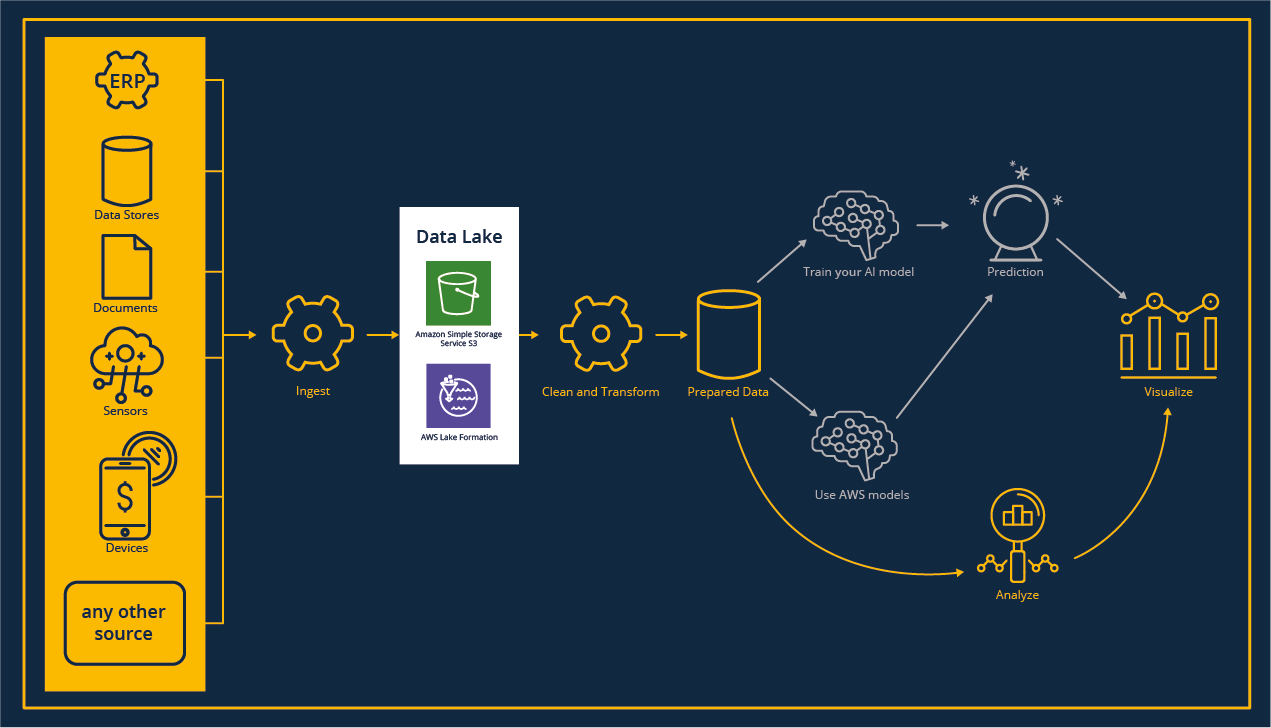
Projektreferenz „Data Lake“
Jetzt beginnt der spannende, wenn auch aufwändigste Teil des Analyseprozesses: Die Aufbereitung der Daten für die Visualisierung oder das Modelltraining.
Neben den klassischen Apache Hadoop-bezogenen Workloads mit Jupyter Notebooks, z.B. mit Apache Spark oder serverlosen Funktionen, stehen grafische Werkzeuge wie Drittanbieter-Tools z.B. Matillion ETL zur Verfügung.
Die Datentransformation ist nicht nur hinsichtlich der Erstellung eines geeigneten Data-Warehouse-Modells, der Datenbereinigung und -transformation eine Herausforderung. Sie erfordert auch die Orchestrierung unterschiedlicher Arbeitslasten in Bezug auf Zeitpläne, Reihenfolge der Ausführung und Infrastruktur.
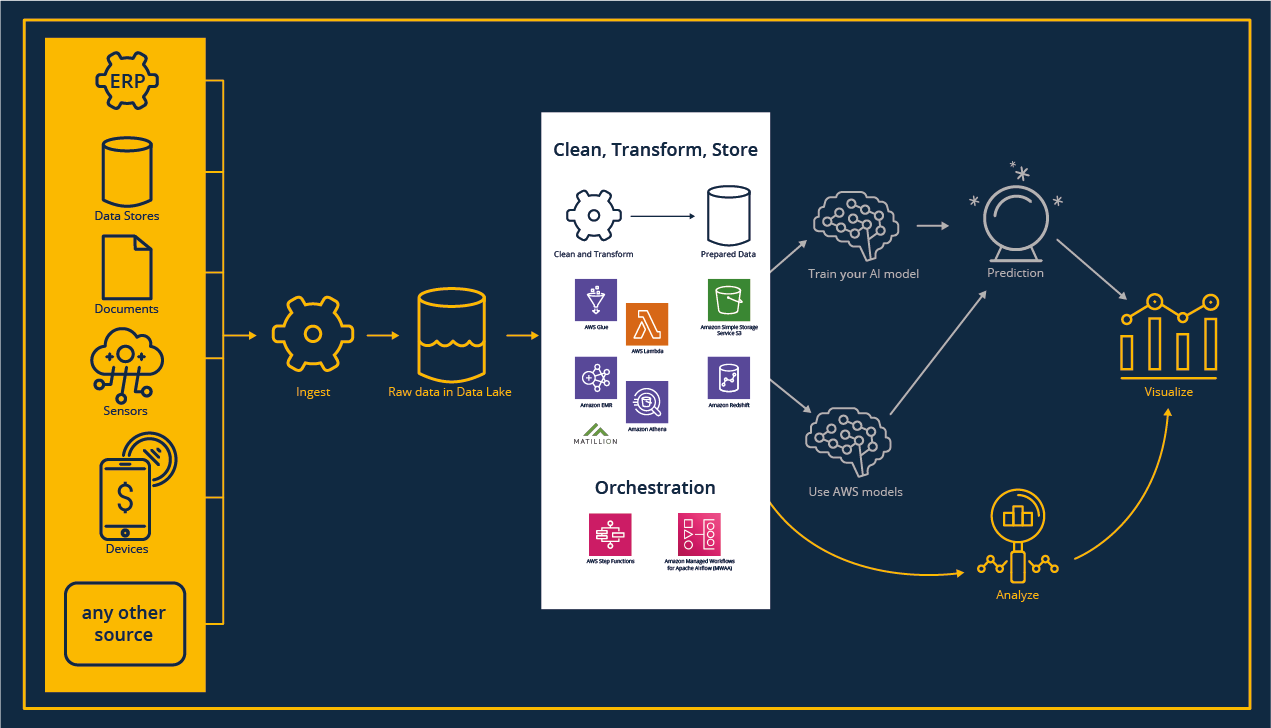
Für Analysen ist eine konsistente und geschäftsorientierte Sicht absolut notwendig.
Unterschiedliche Anwendungsfälle erfordern unterschiedliche Zugriffsmuster:
Von der Abfrage eines klassischen Data Warehouse über den Zugriff auf Daten in einem Apache Hadoop-Cluster bis hin zu neuen und spannenden Speicheroptionen wie der Verwendung eines Objektspeichers, oder der Kombination von Daten zwischen diesen – alles ist möglich!
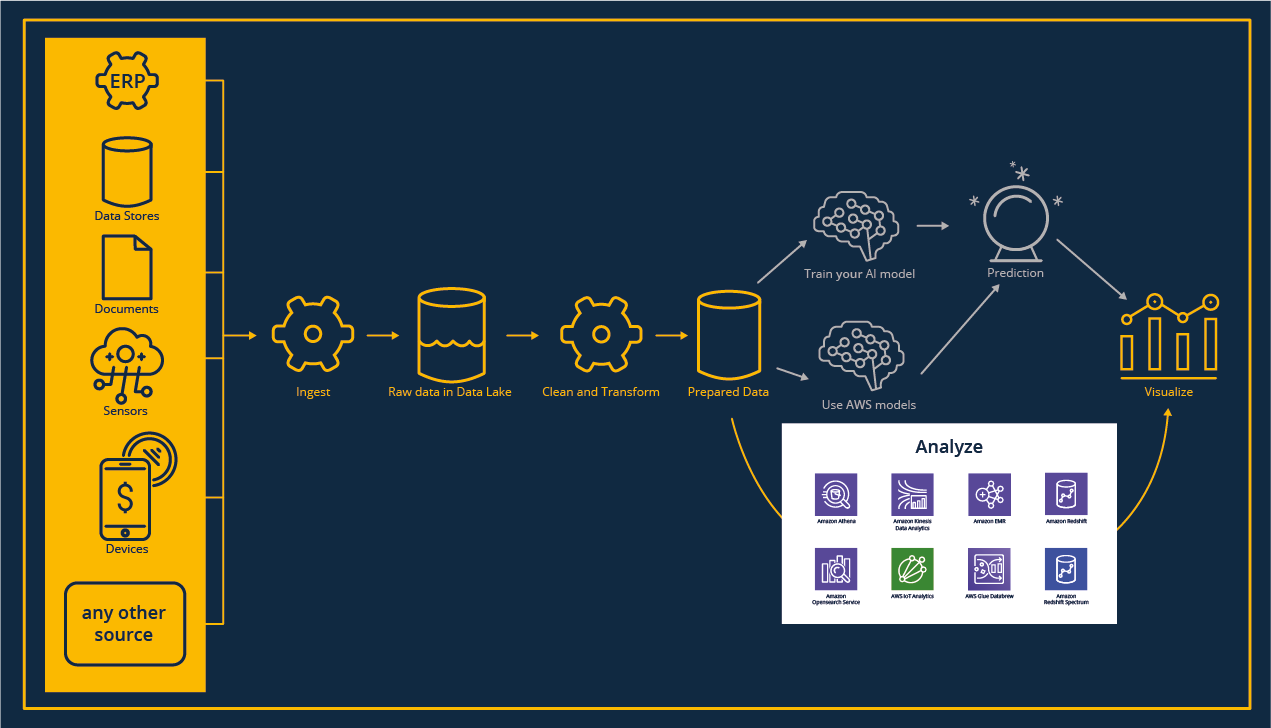
Die extrahierten Informationen aus unseren Daten sollen verständlich, zugänglich und lesbar sein.
In diesem letzten Schritt geht es darum, das Wesentliche unserer Daten darzustellen und zu verstehen.
Auch die Verfolgung in Echtzeit über Dashboards ist eine wichtige Funktion.