Building a deduplication machine
How it started
A few months ago we supported a customer with a data migration project and one of the most important aspect of the migration was to make sure data duplicates were not reproduced in the new data layer but instead copied only once and to have duplicates of a file listed as references in the new data layer.
To solve the uniqueness challenge we built a deduplication machine mainly using Amazon S3 and DynamoDB.

Signatures for fast file comparison
An important part of the duplicate detection process is being able to determine if two given files are identical. One way to do this, an expensive one, would be to compare the files bit by bit, which can take an immense amount of time based on the file sizes and the amount of files. A more practical approach is to use file signatures, which provide sufficient confidence that two given files are identical if their signatures match, or different if their signatures differ. Signatures are shorter representations of files that are expected to be different given that the file contents are different. Additionally, the signature generation should not be computationally expensive and the collision rate, the amount of times two different files have the same signature, should be negligible or zero.
AWS provides us with support for file signature management with Amazon S3 and the AWS SDK. S3 supports different file signature algorithms: CRC-64/NVME, CRC-32, CRC-32C, MD5, SHA-1, SHA-256. These can be categorized into checksums (CRC-64/NVME, CRC-32, CRC-32C) and cryptographic hash functions (MD5, SHA-1, SHA-256). From these supported algorithms, the checksums are up to 100 times faster than the cryptographic hash functions. There is therefore a computational advantage in using them, as long as collision rates remain as low as needed for the use case.
Matt Dillon experimented with CRC and showed how low the collision rate is with growing signature size. CRC16 - CRC64 tests For our solution we used CRC-64/NVME as it is robust enough for a few millions items, our use case was within a safe environment, without potential malicious tampering of files. Otherwise CRC would not be a sound choice. You should consider cryptographic hash functions, mainly SHA-256, unless you are sure about what you are doing.
When storing files in S3, we have to make sure to pass the parameter ChecksumAlgorithm with the value CRC64NVME.
import boto3
s3_client = boto3.client("s3")
s3_client.upload_file(
Filename="path/to/file",
Bucket="my-bucket",
Key="my-object-key",
ExtraArgs={"ChecksumAlgorithm":"CRC64NVME"}
)
import boto3
s3_client = boto3.client("s3")
# Read the file content
with open("path/to/file", "rb") as file:
file_content = file.read()
# Upload using put_object
s3_client.put_object(
Bucket="my-bucket",
Key="my-object-key",
Body=file_content,
ChecksumAlgorithm="CRC64NVME"
)
To gather the file signature for a given file, we can set the ChecksumMode to enabled.
import boto3
s3_client = boto3.client("s3")
response = s3_client.head_object(Bucket="my-bucket", Key="my-object-key", ChecksumMode="ENABLED")
checksum = response['ChecksumCRC64NVME']
Note that the ChecksumCRC64NVME is available because we selected CRC64NVME as checksum algorithm while uploading the file.
We now have a way to gather file signatures without explicitly computing them ourselves.
DynamoDB table for duplicates identification
The second part of the solutions uses DynamoDB for duplicates identification.
The principle is as follows: We use the file location in S3 (e.g. s3://my-s3-bucket/my-sample-file) as partition key in the main table.
This allows us to quickly insert and update items. All items contain their corresponding signature as file_hash.
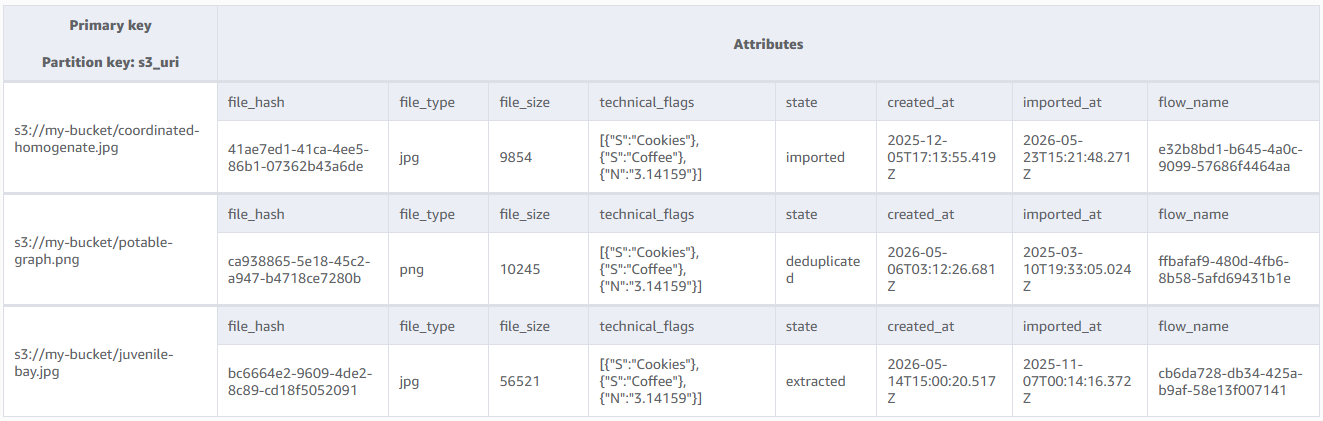
We use a global secondary index that has file signatures as partition key. A sort key can optionally be added using the created_at attribute.
 This way, given a file signature, we can easily find if there is at least another file existing with the same file hash.
This way, given a file signature, we can easily find if there is at least another file existing with the same file hash.
 The design allows for concurrent writes. However, it is important that no writes are done concurrently to querying for duplicates as this could lead to missed duplicates. The singleton process/worker responsible for the duplicates identification can then proceed to update any external related system.
The query process looks as follows:
The design allows for concurrent writes. However, it is important that no writes are done concurrently to querying for duplicates as this could lead to missed duplicates. The singleton process/worker responsible for the duplicates identification can then proceed to update any external related system.
The query process looks as follows:
from typing import Iterator, Dict, Any
import boto3
from boto3.dynamodb.types import TypeDeserializer
dynamodb_client = boto3.client("dynamodb")
def get_duplicates_by_hash(
table_name: str,
gsi_name: str,
file_hash: str
) -> Iterator[Dict[str, Any]]:
"""
Query a DynamoDB Global Secondary Index by file_hash.
:param table_name: DynamoDB table name
:param gsi_name: Global Secondary Index name
:param file_hash: Hash value to query
:return: Iterator of deserialized items
"""
deserializer = TypeDeserializer()
# Create paginator
paginator = dynamodb_client.get_paginator("query")
# Query parameters
query_params = {
"TableName": table_name,
"IndexName": gsi_name,
"KeyConditionExpression": "#file_hash = :file_hash",
"ExpressionAttributeNames": {"#file_hash": "file_hash"},
"ExpressionAttributeValues": {":file_hash": {"S": file_hash}},
}
# Paginate through results
page_iterator = paginator.paginate(**query_params)
for page in page_iterator:
items = page.get("Items", [])
for item in items:
# Deserialize DynamoDB item
deserialized_item = {k: deserializer.deserialize(v) for k, v in item.items()}
yield deserialized_item
Should you need to store data that is not supported by the default serializer and deserializer of dynamodb, you should have a look at how to store custom types in DynamoDB.
That’s it. We have all components for our file deduplication machine at scale.
Summary
Building an effective deduplication system can be done by leveraging AWS services such as S3 and DynamoDB. For that you simply have to make use of AWS provided features such as Checksum computation with S3 and proper table design with DynamoDB. Depending on your use case you may be required to only use cryptographic hashes instead of checksum functions for signature generation.
If you need developers and consulting to support you on your next AWS project, don’t hesitate to contact us, tecRacer.
— Franck
See also