GO-ing to production with Bedrock RAG Part 2: Develop, Deploy and Test the RAG Backend with SAM&Postman
In part one, we took the journey from a POC monolith to a scaleable two-tier architecture. The focus is on the DevOps KPI deployment time and the testability. With the right tools - AWS SAM and Postman - the dirty work becomes a nice walk in the garden again. See what a KEBEG stack can achieve!
Infrastructure
Infrastructure and Code Deployment framework
Most of our AWS projects use AWS CDK or terraform as an IaC platform. For this small project I decided to give AWS SAM a chance. For a small project like this it has several properties which fit:
- Easy creation of API Gateway is supported
- Development cycles are fast
- Creation of provided runtime is supported
For larger projects I tend to use CDK, if possible.
Compare CDK vs SAM
Let´s compare CDK Typescript vs SAM.
| Property | CDK | SAM |
|---|---|---|
| Number of files (1) | 1956 directories, 10589 files | 7 directories, 14 files |
| Sync supported (2) | yes | yes |
| Paradigm | imperative | declarative |
(1) output of tree
(2) CDK supports sync usually with docker and GO, which takes longer.
SAMs sync is nearly as fast as manual optimization
Directory structure
├── Taskfile.yml
├── lambda
│ └── query
├── readme.md
├── samconfig.toml
└── template.yaml
Taskfile.yml is a taskfile which is used to build and deploy the project.
Deploy infrastructure
SAM has a guided deployment. That creates the samconfig.toml file.
After that first deployment you can use sam deploy to deploy the infrastructure. This is configured in the Taskfile.yml.
task deploy
Deployment Kendra
COST WARNING
Kendra developer edition costs 800$ per month! So don´t forget to delete the Kendra index after testing.
Create a Kendra index and put the index ID into Systems Manager Parameter Store.
In the template.yaml the parameter is used to create the environment variable KENDRA_INDEX_ID.
Environment:
Variables:
KENDRA_INDEX_ID: "{{resolve:ssm:/rag/KENDRA_INDEX_ID:1}}"
In your app code you can access the values:
languageCode = os.Getenv("KENDRA_LANGUAGE_CODE")
region = os.Getenv("KENDRA_REGION")
See lambda/query/kendra/kendra.go.
In this implementation, the Taskfile.yml is the main source of configuration. That “centralized configuration” is a good practice if you have several components which are created with different tools.
So take these steps:
- Create a Kendra index
- Put the Language Code and the region into the Taskfile:
KENDRA_LANGUAGE_CODE: de
KENDRA_REGION: eu-west-1
- Store values in SSM Parameter Store
task parameter
The Index ID is automatically determined by the task:
KENDRA_INDEX_ID:
sh: aws kendra list-indices --query "IndexConfigurationSummaryItems[0].Id" --output text --region eu-west-1
(Region has to be set here also)
APP
Create Prompt
Prompt Engineering is a vital part of a LLM App.
The lambda function reads the prompt from prompt.tmpl.
To get started with an default prompt, run:
cd lambda/query
./create-prompt.sh
In the cloned repository.
The main parts are the question and the documents.
Based on this text, give a detailed answer to the following question:
{{.Question}}
Answers with "I can't say anything about that",
if the data in the document is not sufficient.
<documents>
{{.Document}}
</documents>
The app will fill the question into the questions placeholder and the documents into the documents placeholder. The documents are all excerpts from the Kendra query results.
Deploy app
With the task deploy the infrastructure and the app is deployed.
While you develop the app, you can use task sync to update only the Lambda function code in seconds.
This is done with sam sync --code --stack-name {{.STACK}} --watch.
For GO Lambda functions the lambda/query/Makefile is called.
You dont need to start a docker container as with (most) CDK lambda function constructs.
The Makefile itself is simple:
build-RagFunction:
env GOOS=linux GOARCH=arm64 CGO_ENABLED=0 go build -tags lambda.norpc -ldflags="-s -w" -o bootstrap
cp ./bootstrap $(ARTIFACTS_DIR)/.
cp ./prompt.tmpl $(ARTIFACTS_DIR)/.
build-RagFunction has to match with the name of the Lambda resource of
the template.yaml:
RagFunction:
Type: AWS::Serverless::Function
The ARTIFACTS_DIR is the main directory of the Lambda function.
The ARTIFACTS_DIR is set automatically by SAM.
As shown in part one of this series, this sync is nearly as fast as the manual optimization. The main actions are:
RagFunction: Running CustomMakeBuilder:CopySource
RagFunction: Running CustomMakeBuilder:MakeBuild
The code and the template file are copied to the ARTIFACTS_DIR, which is .aws-sam/auto-dependency-layer/RagFunction/.
With the zipped package a Lambda Update Function Code is called. Because only the function code is updated, the update is fast.
Testing
Prepare Data
To get some data which is licensed to me I did an import to kendra with all slides from my Udemy GO ON aws course.
For a documente like L1-Intro.pdf the S3 connector import needs a file L1-Intro.pdf.metadata.json` with the following content:
{
"DocumentId": "data/L1-Intro",
"Attributes": {
"_category": "go-on-aws",
"_created_at": "2023-12-09T12:56:13+01:00",
"_last_updated_at": "2023-12-09T12:56:13+01:00",
"_version": "1.0"
},
"Title": "L1-Intro.pdf",
"ContentType": "PDF"
}
I imported all slides into kendra.
Test API Calls with postman
Now I can query the api with postman.
Configure Postman:
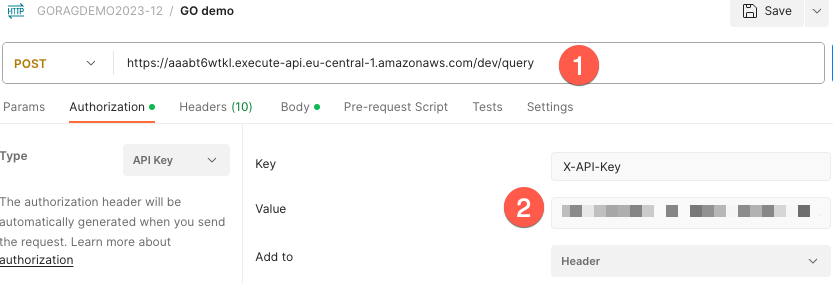
- Use API Gateway URL as request URL
- Set the API Key as header. AWS uses
X-API-Keyas header name.
Call query
This is the input body:
{
"question": "What is a array?",
"category" : "go-on-aws",
"version" : "1.0"
}
The category and the version refer to the imported attribute:
"Attributes": {
"_category": "go-on-aws",
"_version": "1.0"
},
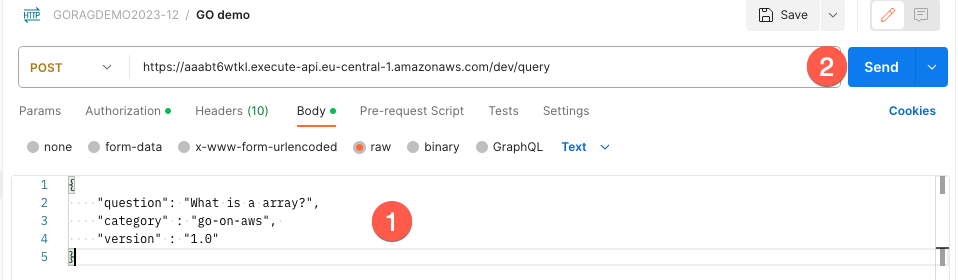
- Put query parameter in the body section
- Send request
Answer
{
"answer": " Based on the excerpts from the document, an array in Go contains other types in a fixed position. The position is given by an int. Unlike some scripting languages, you must \"make room\" for an array in Go and define its size. Some key points about arrays in Go:\n\n- Arrays have a fixed size that needs to be defined on creation. For example:\n\n```\nvar names [4]string\n```\n\n- The elements are accessed via an int index, starting at 0. So names[0] would access the first element.\n\n- Arrays must be initialized before use, otherwise you will get an index out of range error.\n\n- Slices are more flexible than arrays. Slices are like arrays but their length can change during execution. \n\n- Slices are backed by an underlying array. When a slice grows with append, a bigger underlying array may be allocated.\n\nSo in summary, a Go array is a fixed size collection of elements accessible by an integer index. Unlike slices, arrays have a set capacity that needs to be defined on creation.",
"documents": [
{
"excerpt": "Array 11 What is an Array An a r ray conta ins o ther t ypes in a f i xed pos i t ion . The pos i t ion i s g iven by an in t . Other than in some scr ip t ing languages , you must \"make room\" fo r an a r ray and def ine i t s s i ze . 22 Do not use before creation So th is i s not va l id : Output : 33 Do not use before creation St range , bu t t rue . array \"names\" in l ine 4 has counting starts with \"0\", the names[0] is out of range. no entr ies no capacity for entr ies. 44 What to do: initialize with full length Va l id :",
"title": "L10-array.pdf",
"page": 1,
"link": null
},
{
"excerpt": "AWS SDK: Software development kits AWS service: any other AWS service 33 SDK is the base All apps use SDKs: Console uses node SDK CLI uses python SDK 44 API: S3 Simple Storage Services Storage for objects up to 5 Terrabyte per object Object is a f i le and any metadata A bucket is a container for objects. ListBuckets cal l l ists al l exist ing buckets in an account 55 GO SDK API Call ListBuckets aws-go-sdk-v2/listbucketsaws-go-sdk-v2/listbuckets 66 SDK Rest call 77 API Response Usual ly JSON Some older services use XML: S3 EC2 88 SDK Response SDK translates al l k ind of responses to JSON 99 Response struct Type : ListBucketsOutput 1 01 0 WrapUp SDK has functions for al l API cal ls Retr ies, t imeout etc. bui ld-in 1 11 1",
"title": "L27-the-go-sdk.pdf",
"page": 5,
"link": null
},
You see that pdf is not the ideal way to retrieve the data from. But in most companies, all knowledge is just stored in pdfs. And the results are not bad!
Another question:
“What are advantages of go over python?”
Answer from the system:
" Based on the excerpts provided, here are some of the key advantages of Go over Python for AWS Lambda functions:\n\n- Faster build time and deployment: Go compiles to a single binary that can be easily deployed, while Python requires packaging up dependencies. \n\n- Better performance: Go is a compiled language and is generally faster for computations than interpreted languages like Python.\n\n- Easier cross-platform builds: Go can easily cross-compile for different operating systems like Linux that Lambda runs on. Python needs extra tools to build for non-native platforms.\n\n- Simpler packaging: Go has a standard module system (go mod) while Python has competing tools like pip, virtualenv, poetry, etc. \n\n- Backward compatibility promise: Go commits to compatibility so old code still works on new versions. Python has frequent breaking changes between versions.\n\n- Security: Go binaries don’t include source code so you can control code visibility. Python includes source so anyone can see your code.\n\nIn summary, Go provides faster builds, better performance, simpler packaging, and more control compared to Python for Lambda development. The excerpts highlight these advantages like fast cross-platform builds, go mod for packaging, and compiled vs interpreted language performance.",
Development Cycle time
With SAM a fast development cycle is possible. During development this is a main performance indicator. Unit test are good and vital. But with serverless the AWS resources play a large role. So integration tests become more important.
That means you have to deploy multiple times during development.
Lets assume with changes you want to test 10 times an hour. With a CI/CD pipeline, a normal wait time would be 5 minutes for each deployment. That means 50 minutes of waiting time per day.
With SAM sync - or similar tools - you can reduce the wait time to 1 seconds. That means 1 minute of waiting time per day.
You may ask: BUT during the waiting time you can do other things, so it is not wasted!
That is the main misconception! With a deployment which you do not notice, your train of thought is undisturbed. You can focus on the task at hand.
With a deployment which takes 5 minutes, you have to switch your focus to something else. And then you have to switch back to the task at hand. That is a huge waste of time and energy. (This sentence has been completely written by copilot :) )
As a developer you understand that switching context can take several minutes. So minimizing the development cycle time saves a lot of money! Its worth investing some time in optimizing it!
Conclusion
Functionality
I imported PDF slides about a complete course in a certain topic, here GO into kendra. On the slides, the information is very condensed. For the course the slides were not meants to be an stand alone source of knowledge. What you see here is that with the KEBEG (Kendra, Bedrock, Go) stack, you can build a knowledge base from existing documents which are not meant to be a knowledge base.
Development performance and testability
The development cycle with SAM is fast. The creation of simple API Gatways with SAM is simpler than with CDK or terraform in my experience.
With Postman you can also automate test. And in almost any lamnguage you can write automated test which calls a REST API. So the testability is good.
Framework or code is the new “build or buy”
Splitting the monolith StreamLit/LangChain code into frontend and backend gives a more flexible solution. As an argument for langchain the flexibility to chain different parts together. In this solution the parts are so small, that we gain speed and reduced complexity by coding the parts in GO.
A generalized solution as LangChain or Llamaindex is a good fit, if all of your requirements can be configured. If your UseCase is not standard and you have to update the generalized solution, usually its a lot of more work than coding a solution from scratch. Compare the time you have to invest to learn a whole framework or to read some lines of code.
In the end, it depends. What I recommend is taking some time to think about your solution before you start coding.
If you need developers and consulting for your next GenAI project, don’t hesitate to contact us, tecRacer.
For more AWS development stuff, follow me on dev https://dev.to/megaproaktiv. Want to learn GO on AWS? GO here
Enjoy building!