Climb the (bed)rock with Python, Javascript and GO
Bedrock is now available in eu-central-1. It’s time to get real and use it in applications. Reading all blog posts about Bedrock, you might get the impression that Python and LangChain is the only way to do it. Quite the opposite! As Bedrock makes calling the models available as AWS API, all AWS SDKs are supported! This post shows how to use Bedrock with Python, Javascript and GO.
A pragmatic view on Bedrock
Bedrock has two parts:
- The Amazon Bedrock Runtime to invoke the models which are available
- The Amazon Bedrock API
Most things from the bedrock API, like fine-tuning are still in preview (October 2023). Let’s wait after re:Invent to see what is GA.
So, we take what we have now and invoke models! In Frankfurt, we have 2 foundation models available, Titan embedding and Claude V1.2 / V2. We call the AWS API, and AWS calls the foundation model.
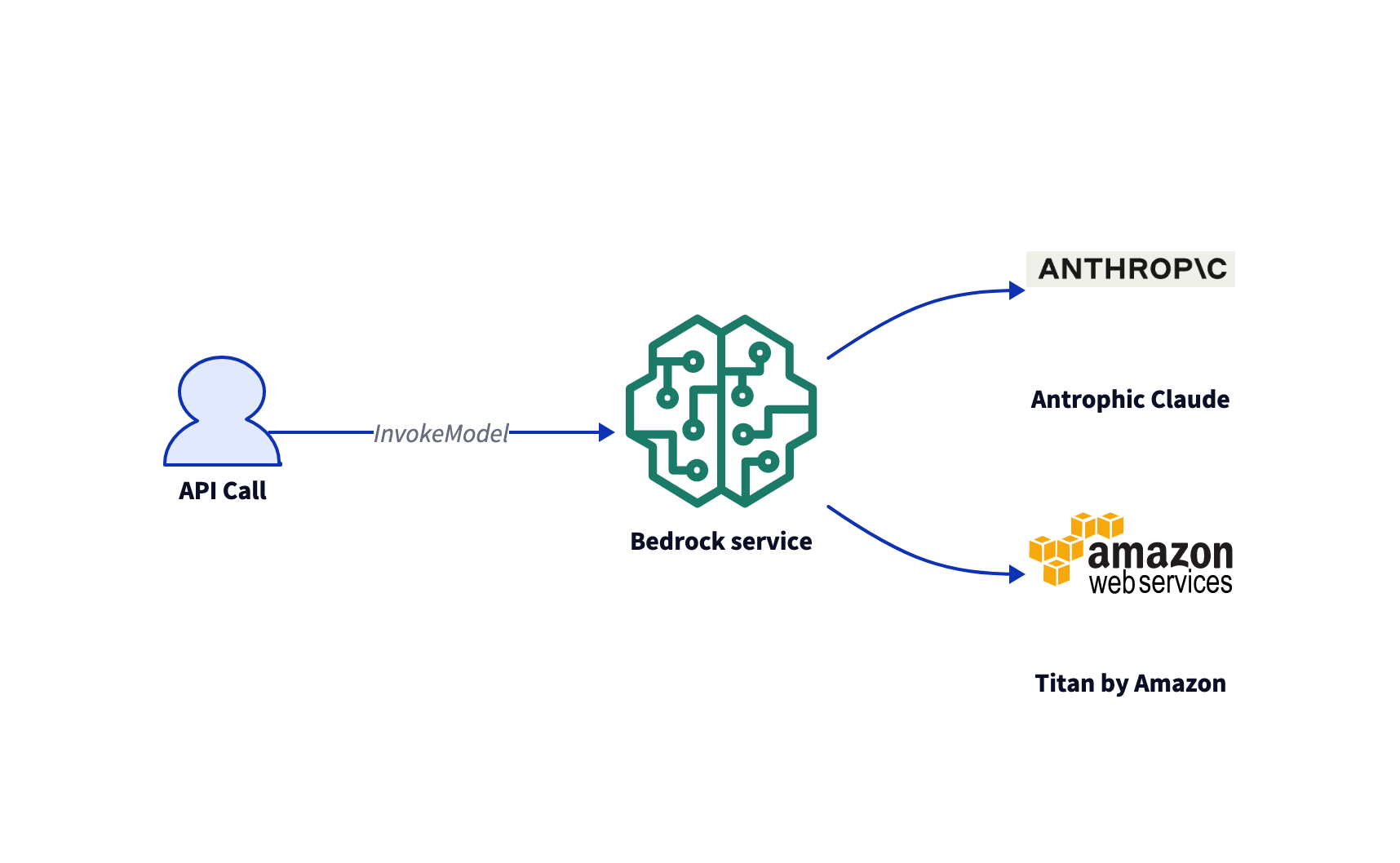 This is the AWS call.
This is the AWS call.
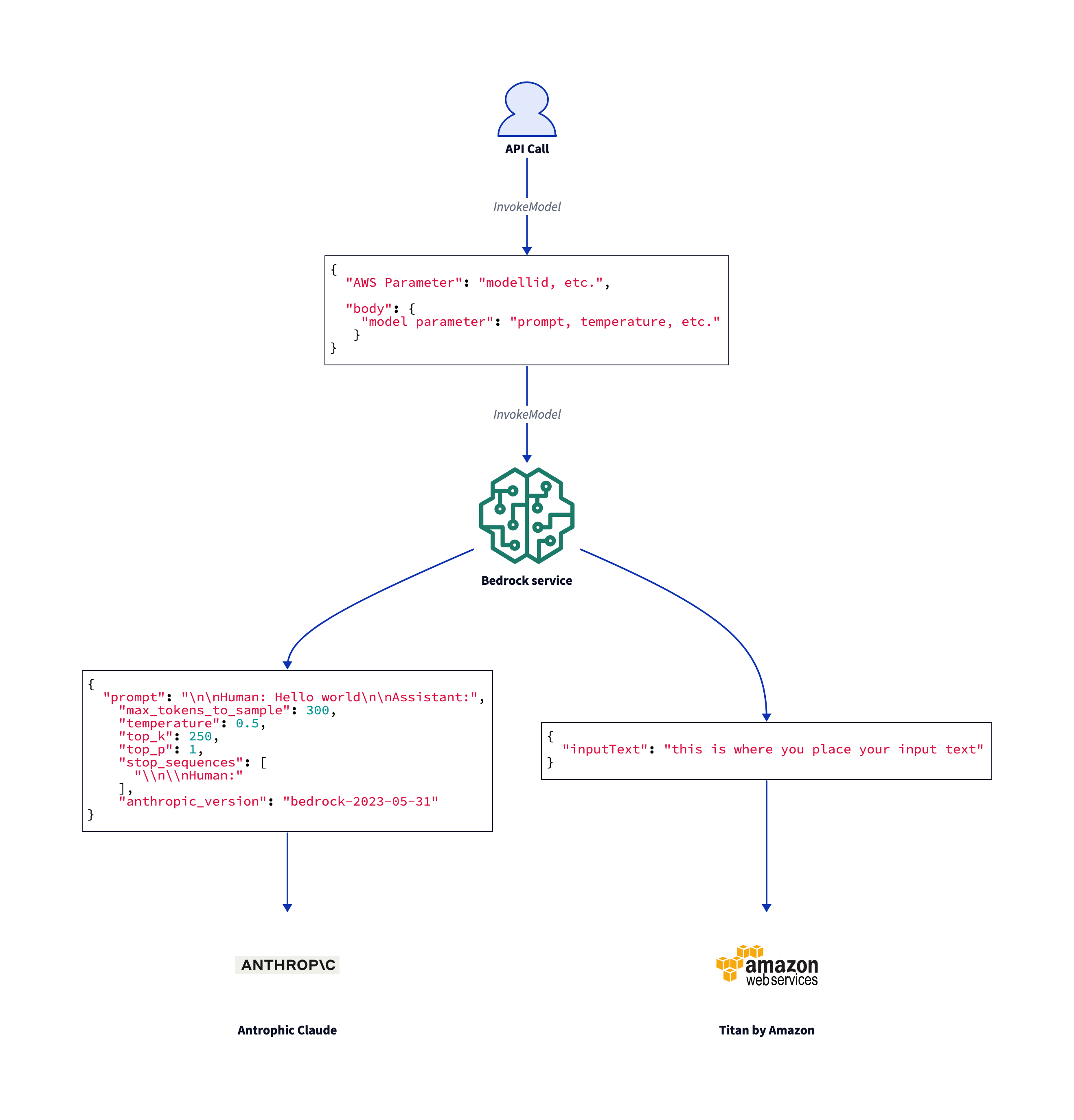 Then, AWS calls the foundation model. The models’ parameters are defined in the
Then, AWS calls the foundation model. The models’ parameters are defined in the body of the AWS call. The body is not typed in the AWS API. It is a JSON object as a string. In this example, we call a Claude model. The parameters are defined in the Claude API.
Steps to invoke completion
- Decide model
- Design prompt
- Prepare model body
- Call API
- Decode response
Decide model
Soon, we will have more models available. For now, we have Claude and Titan in Frankfurt. Claude is an all-purpose text model, and Titan is an embedding model. With more choices, you must look at the model scorecards to get information about the model.
Then check:
- Is the task you want to achieve supported? Like text completion, summarization, translation, question answering, etc.
- Is the language you want to use supported? Like English, German, French, etc.
Here, we decide anthropic.claude-instant-v1. It supports completion and English/German. In the Bedrock console, you see the “Supported use cases” for each model.
Design the prompt
Prompt engineering is a knowledge domain which is constantly growing. Look for new patterns and best practices.
In the prompt we will use an instruction: “Write the top 3 differences in markdown.” and a document part to create the prompt. The text is: “Compare JSON to XML.”
Prepare model body
See Claude API
type ClaudeV1 struct {
Prompt string `json:"prompt"`
MaxTokensToSample int `json:"max_tokens_to_sample"`
Temperature float64 `json:"temperature"`
TopK int `json:"top_k"`
TopP float64 `json:"top_p"`
StopSequences []string `json:"stop_sequences"`
AnthropicVersion ModelId `json:"anthropic_version"`
}
As Python and JavaScript are not typed by default, I use this go struct to show the types. The parameter are descriped in the Claude completion API.
The Bedrock service uses InvokeModel to call the Claude `completion API.
See go-bedrock/claude/claude.go on github.
Call Parameters GO
With the prepared structure we can create the body for the AWS call:
completePrompt := fmt.Sprintf("Human: \n\n%s\n\n\nAssistant:", prompt)
body := &claude.ClaudeV1{
Prompt: completePrompt,
MaxTokensToSample: 1024,
Temperature: 0,
TopK: 250,
TopP: 0.999,
StopSequences: []string{"\n\nHuman:"},
AnthropicVersion: "bedrock-2023-05-31",
}
See go-bedrock/claude/claude.go on github.
With GO we do byteSlice, err := json.Marshal(body) to create the body as JSON string.
Call Parameters Python
First, we define the prompt and the body:
prompt = f"Human: \n\n{instruction}\n\n\nAssistant:"
body = {
"prompt": prompt,
"max_tokens_to_sample": 1024,
"temperature": 0,
"top_p": 250,
"top_k": 0.999,
"stop_sequences": ["\n\nHuman:"],
"anthropic_version": "bedrock-2023-05-31",
}
Then we do a json.dumps(body) to create the body.
Call Parameters JavaScript
First, create the body:
let instruction = "Compare JSON to XML. Write the top 3 differences in markdown."
let complete_prompt = `Human: \n\n${instruction}\n\n\nAssistant:`;
const body = {
"prompt": complete_prompt,
"max_tokens_to_sample": 1024,
"temperature": 0,
"top_k": 250,
"top_p": 0.999,
"stop_sequences": ["\n\nHuman:"],
"anthropic_version": "bedrock-2023-05-31",
}
Then we do a JSON.stringify(body) to create the body:
const buffer = Buffer.from(JSON.stringify(body));
Call api
See Bedrock Runtime API.
Calling the API is quite similar in all languages.
GO:
response, err := client.InvokeModel(context.TODO(), &bedrockruntime.InvokeModelInput{
ModelId: aws.String(string(claude.ModelIdClaudeInstantV1)),
ContentType: aws.String("application/json"),
Accept: aws.String("*/*"),
Body: byteSlice,
})
Python:
response = client.invoke_model(body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
JavaScript:
const command = new InvokeModelCommand(input);
try {
const response = await client.send(command);
}
Decode response
Each model will give a different JSON structure as an answer. Here, we use Claude, so the answer is:
type Response struct {
Completion string `json:"completion"`
StopReason string `json:"stop_reason"`
Model string `json:"model"`
}
If there is an error, a different JSON structure is returned:
type ResponseError struct {
Error struct {
Type string `json:"type"`
Message string `json:"message"`
} `json:"error"`
}
Climb
I have prepared a taskfile, so you can call task run` in each subdirectory to run the code.
GO
With the first time call, the app is built:
[init] go build -o dist/claude main/main.go
Calling run the second time:
cd go-bedrock
time task run ─╯
task: Task "init" is up to date
Calling Claude...
Response:
### Top 3 Differences Between JSON and XML
1. **Structure** - JSON has a simpler structure than XML. JSON uses key/value pairs and does not require closing tags. XML requires opening and closing tags.
2. **Readability** - JSON is generally considered more human-readable than XML due to its simpler structure. XML tags can sometimes obscure the meaning.
3. **Size** - JSON tends to be more compact than XML since it does not require as much formatting. This makes JSON preferable for data transmission, especially on mobile networks.
task run 0,02s user 0,02s system 1% cpu 2,393 total
Python
With the first time call, the app is built:
cd python-bedrock
task run
This takes some time, because the virtual environment is created and the dependencies are installed:
Requirement already satisfied: pip in ./.venv/lib/python3.11/site-packages (23.0.1)
Collecting pip
Downloading pip-23.3.1-py3-none-any.whl (2.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.1/2.1 MB 15.2 MB/s eta 0:00:00
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 23.0.1
Uninstalling pip-23.0.1:
Successfully uninstalled pip-23.0.1
...Many more lines
Calling run the second time:
time task run ─╯
JSON: {"prompt": "Human: \n\nCompare JSON to XML. Write the top 3 differences in markdown.\n\n\nAssistant:", "max_tokens_to_sample": 1024, "temperature": 0, "top_p": 250, "top_k": 0.999, "stop_sequences": ["\n\nHuman:"], "anthropic_version": "bedrock-2023-05-31"}
Response: {"completion":" ### Top 3 Differences Between JSON and XML\n\n1. **Structure** - JSON has a simpler structure than XML. JSON uses key/value pairs and does not require closing tags. XML requires opening and closing tags.\n\n2. **Readability** - JSON is generally considered more human-readable than XML due to its simpler structure. XML tags can sometimes obscure the meaning. \n\n3. **Size** - JSON tends to be more compact than XML since it does not require as much markup. This makes JSON lighter and faster to parse. XML documents can become very large with all the required tags.","stop_reason":"stop_sequence"}
task run 0,28s user 0,11s system 14% cpu 2,642 total
Here the full JSON objects are printed.
JavaScript
With the first time call, the app is built:
cd js-bedrock
task run
(#########⠂⠂⠂⠂⠂⠂⠂⠂⠂) ⠋ idealTree:@aws-crypto/sha256-js: timing idealTree:node_modules/@aws-crypto/sha256-js Completed in 1ms
JavaScript has the nicest animation while downloading the depedencies :) .
Calling run the second time:
time task run ─╯
Response:
### Top 3 Differences Between JSON and XML
1. **Structure** - JSON has a simpler structure than XML. JSON uses key/value pairs and does not require closing tags. XML requires opening and closing tags.
2. **Readability** - JSON is generally considered more human-readable than XML due to its simpler structure. XML tags can sometimes obscure the meaning.
3. **Size** - JSON tends to be more compact than XML since it does not require as much formatting. This makes JSON preferable for data transmission, especially on mobile networks.
Done
task run 0,16s user 0,05s system 9% cpu 2,132 total
As the app itself has not much work to to, javascript is even faster than GO here. This could be the Marshal part. It would be interesting to see how TypeScipt performs here. Anyone want to try out?!
Conclusion
Before Bedrock, I tried to get an Antrophic key for several weeks without success. With Bedrock, this became much easier. Calling the models via Bedrock is more secure than calling them directly. The AWS security methods help us here.
The rest is easy if you understand how to create the body and decode the response. So start in your development language of choice.
Enjoy building!
If you need developers and consulting for your next GenAI project, don’t hesitate to contact the sponsor of this blog, tecRacer.
For more AWS development stuff, follow me on dev https://dev.to/megaproaktiv. Want to learn GO on AWS? GO here