AWS announces Terraform Support for Service Catalog - is it any good?
Yesterday, AWS announced support for Terraform Open Source in Service Catalog. For me, this sounds like a game changer! Which is why I had to test it out immediately.
In my opinion, Terraform’s biggest flaw is its Lifecycle Management, which usually requires some kind of CLI to create, change, and destroy resources. With the integration to Service Catalog, I am not only hoping it is bringing nice new features for Service Catalog’s original purpose (which is to allow controllable deployments of predefined infrastructure). Additionally, I am hoping that it can be used to handle some of the lifecycle management tasks that Terraform requires.
Now this might have changed. I will take you on my personal test ride of this new feature, and together we will discover what it’s really worth.
The announcement makes it sound easy: Just first do a one-time deployment of the “Service Catalog Engine for Terraform Open Source” from GitHub and then start deploying your stacks. Let’s see if that is true:
Initial Deployment
As mentioned, before the integration can be used, a one-time setup is required. I am following the instructions found on the GitHub page and am running the commands from my local machine (using CloudShell failed due to the amount of storage required by the commands).
Honestly, it wasn’t as easy as the documentation described it, but I made it work. To help other users, I opened a GitHub Issue to slightly adjust the documentation. Once all prerequisites (e.g., Go, SAM, etc.) are installed, running the commands is easy and doesn’t cause any issues:
git clone https://github.com/aws-samples/service-catalog-engine-for-terraform-os
cd service-catalog-engine-for-terraform-os/
./bin/bash/deploy-tre.sh -r eu-central-1
Example
In the next step, I will configure a service catalog product. For this, I am following the steps on the official AWS product documentation.
It will deploy the following very simple Terraform Configuration:
variable "bucket_name" {
type = string
}
provider "aws" {
}
resource "aws_s3_bucket" "bucket" {
bucket = var.bucket_name
}
output regional_domain_name {
value = aws_s3_bucket.bucket.bucket_regional_domain_name
}
Create a Service Catalog Product from the Terraform configuration
I like how prominently the new Terraform option in Service Catalog is positioned. The Terraform code can be loaded from URL, a Git Repository, or simply from a file. Out of simplicity, I chose the latter option.
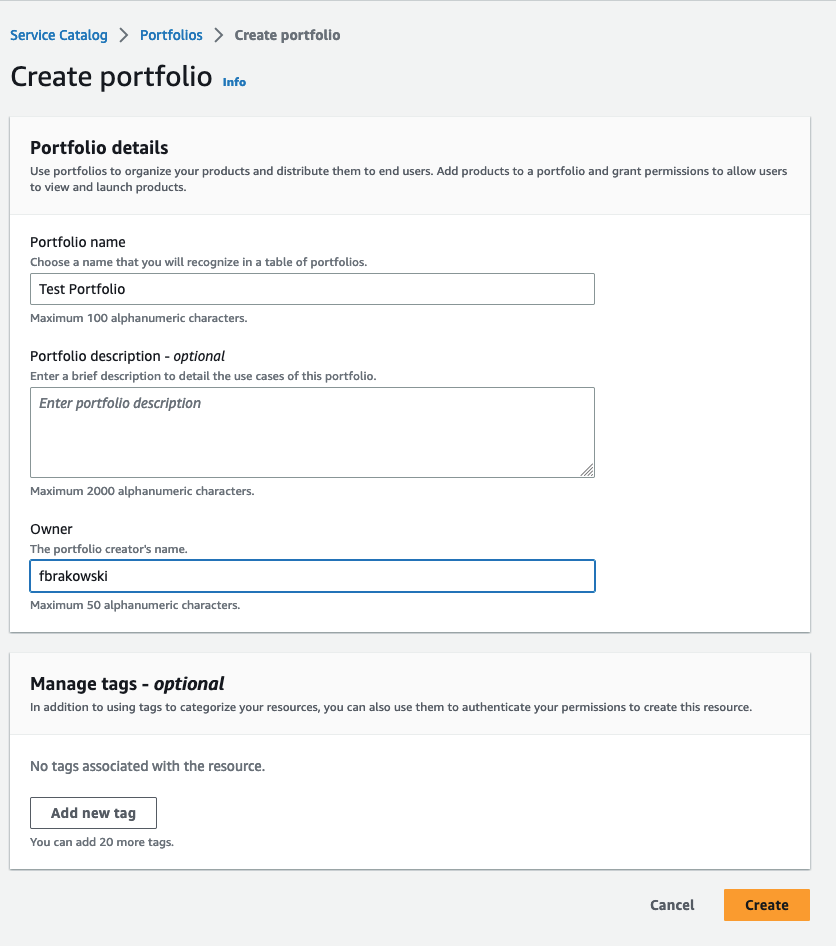
Create Portfolio
Next, to make the product usable, we need to assign it to a portfolio. In this context, an IAM role needs to be provided with sufficient rights to deploy the Terraform stack (details can be found in AWS’s documentation).
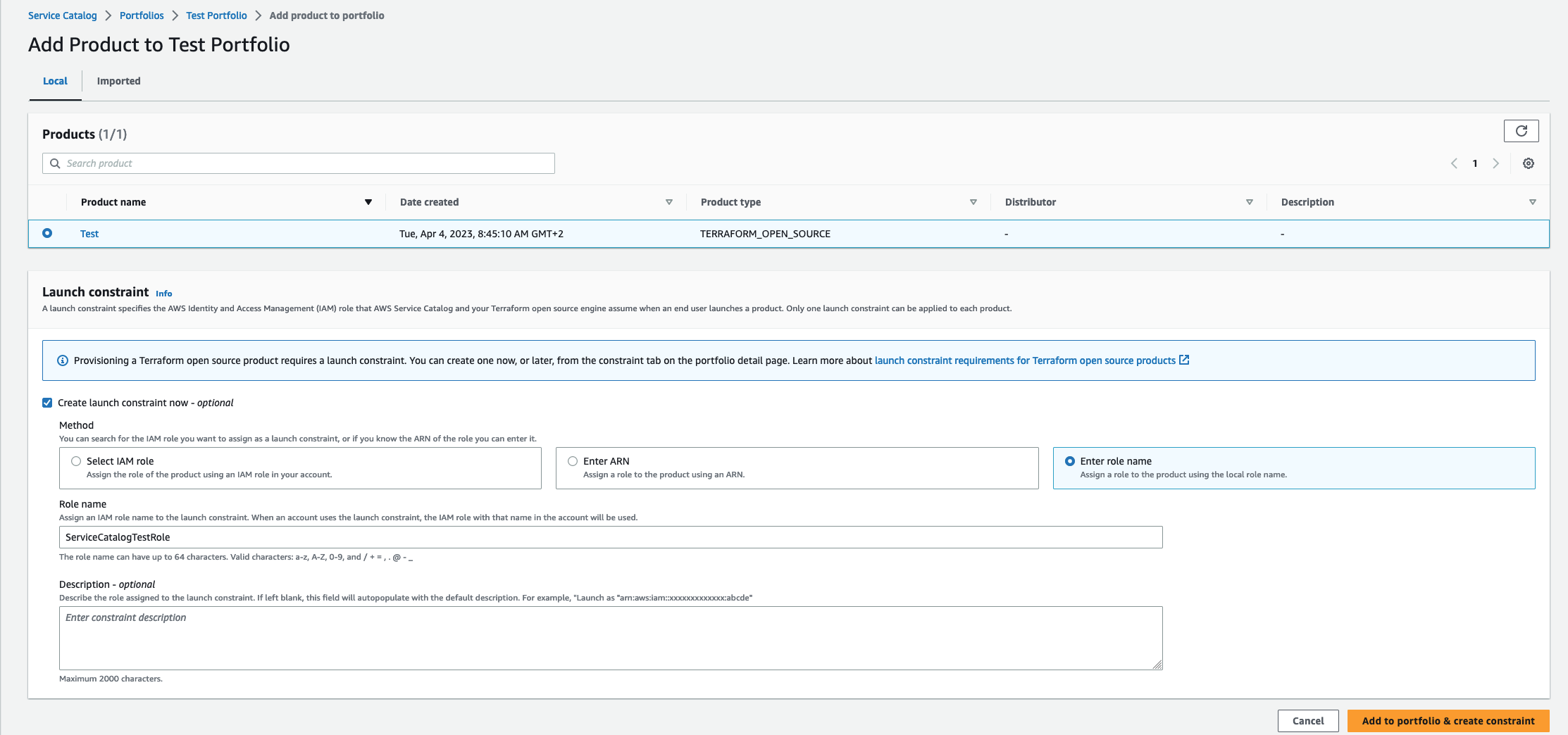
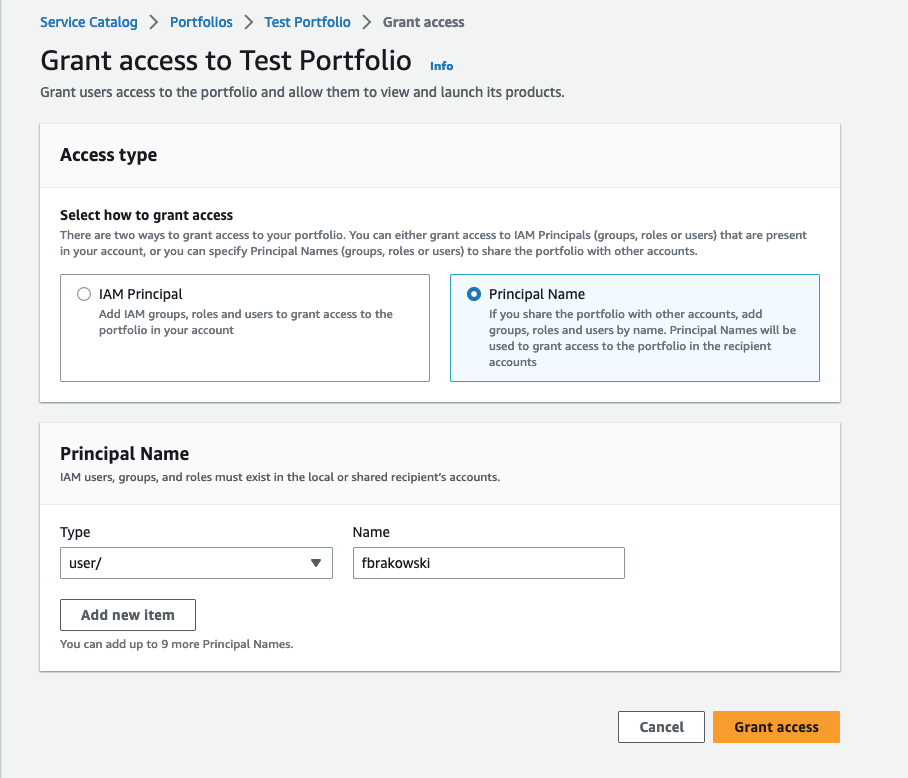
Afterwards, as a last step before deployment, grant access to the portfolio to the principals that should deploy the product. In my case, that is simply my own user.
Launch Product
Now that the product has been created and assigned to a portfolio, it’s time to launch it. Navigate to the “Products list” tab in the Service Catalog console and click on the “Launch Product” button for the desired product.
During the launch process, you’ll be asked to provide input parameters for the Terraform configuration. In this case, I need to provide a value for the bucket_name variable. I like that this was auto-generated from the variables in the Terraform module.

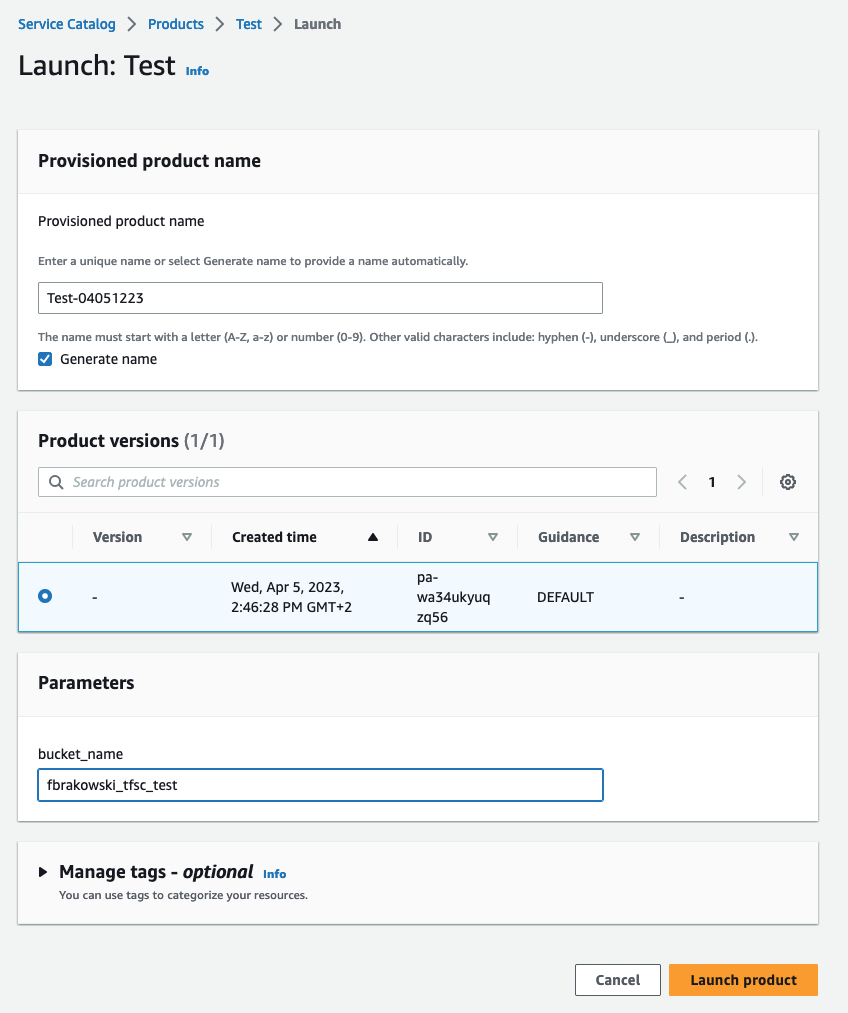
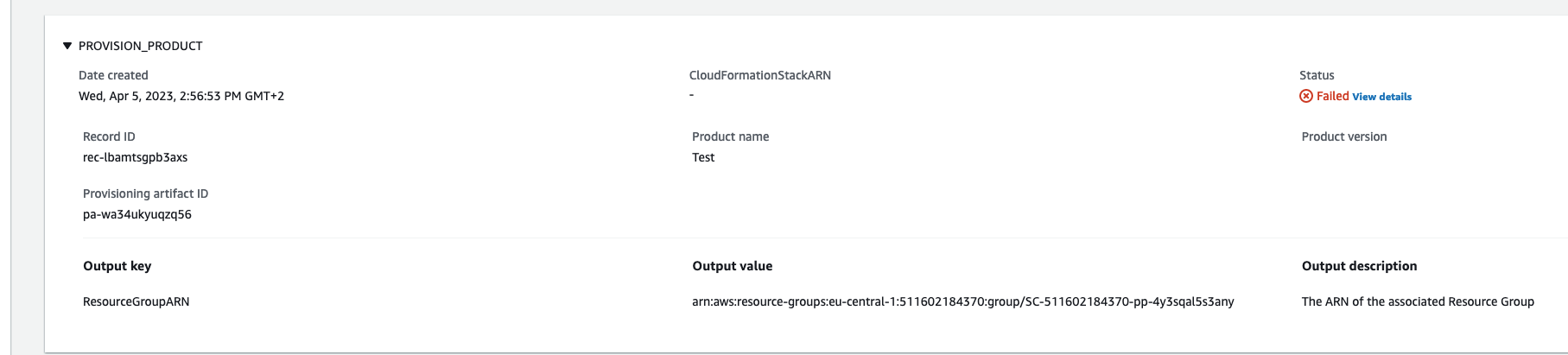
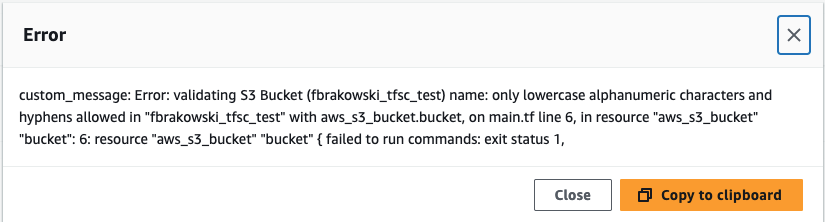
Initially, I created the product with an invalid bucket name, but I didn’t realize it at that time, as there was no warning. I later found out about this issue in the events section of the provisioned product (in View Details). Ideally, there should be a warning for such errors, but with Terraform, that’s not possible as these errors only come up during runtime.

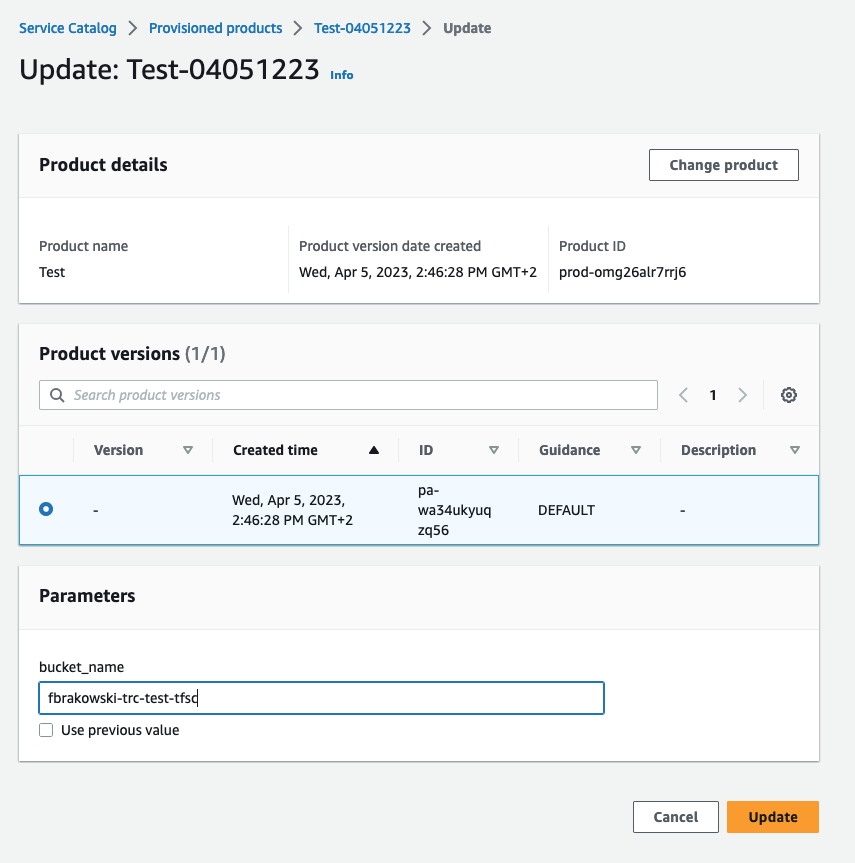
To fix this issue, I updated the product with a valid bucket name.
After providing the input parameters, click “Launch” and wait for the stack to be created. You can monitor the progress in the “Provisioned products” section of the Service Catalog console.
Once the product is successfully launched, you can verify that the S3 bucket has been created by checking the AWS S3 console.
Honestly: This worked really well!
Technical Implementation
Under the hood, the Terraform integration for Service Catalog leverages a variety of AWS components. AWS Service Catalog publishes a message to an SQS queue for each provisioning operation, such as provisioning, updating, or terminating resources. Lambda functions process these messages, and Step Functions state machines oversee the overall logic of provisioning workflows. Finally, the actual Terraform deployment is done by EC2 instances within an autoscaling group that are triggered by SSM Run Commands.
The integration handles state management by utilizing a dedicated and secured S3 bucket for storing Terraform state files. This approach eliminates the need for users to manage state files manually, resulting in a more streamlined experience.
Each workflow within the integration follows a sequence of steps, such as selecting an EC2 instance, executing Terraform work via SSM Run Command, and monitoring the results. Once the Run Command is complete, the system collates the workflow results and reports them back to the Service Catalog.
However, there’s a drawback in the current implementation: EC2 instances are always running. In my view, a more cost-effective and resource-efficient solution would be to adopt a dynamic approach, like booting instances only when required or, even better, using AWS CodeBuild for deployments, like I did in my own blog post. This change could help optimize resource usage while maintaining the same level of functionality and efficiency.
Importance of Thorough Testing
Something I realized is the importance of proper testing before releasing a product to a user. Users may not be fully aware of the impact of changing certain parameters, there is a risk of inadvertently breaking the system or losing valuable data. To mitigate this risk, it is essential to establish a robust testing process for Terraform templates and establish proper variable validation and other safety measures.
My Opinion
After testing out the new Terraform support for AWS Service Catalog, I have mixed feelings about it. On one hand, it does bring some benefits to managing Terraform stacks and makes it easier for non-technical users to deploy and manage infrastructure. It also addresses some of the lifecycle management tasks that Terraform requires. On the other hand, I’m not entirely certain how it operates at scale and whether it covers a wide range of use cases. Moreover, what AWS did here is to recycle an old architecture they published in 2018 and integrate it a little more into the console. It is a first step, but no complete integration yet. I do not understand why AWS doesn’t go the full way and make it a fully managed service instead of needing customer-owned resources.
However, I do have a specific use case in mind where we are working on building some automation to replicate an environment multiple times in a standardized manner. The Terraform integration with Service Catalog could prove useful for that purpose, as it streamlines the process and enforces consistency across deployments.
Overall, I think this new feature is a step in the right direction for AWS and Terraform users, but there’s still room for improvement. If AWS can continue to enhance this integration and make it more seamless, it could become a powerful tool for managing infrastructure as code within the AWS ecosystem.
In the meantime, I recommend giving it a try and seeing if it fits your use case. The benefits of easier lifecycle management and the ability to leverage Service Catalog features may outweigh the limitations for some users.