Setting a proxy in the AWS Application Discovery Service Agentless Collector
The new agentless collector for the Application Discovery Service can be used to collect data from VMware vCenter and thus is useful whenever the ADS agent cannot be installed on the servers.
However, AWS “forgot to mention” how to ensure connectivity over a proxy server in environments that do not allow direct internet access. Here`s how I fixed the issue.
Update (November 9, 2023)
Support for a proxy is now available: https://aws.amazon.com/about-aws/whats-new/2023/11/aws-application-discovery-service-communication-proxy
Update (November 2, 2022)
In the meantime I received some feedback from AWS’s development team. They say that official proxy support is planned for the future and that below solution “is a fairly good workaround”. However, with it the collector will not be able to auto-update. To get updates a new deployment using the latest image is required.
They say that at this point, if a customer requires an HTTPS proxy, they would recommend using the old Discovery Connector over the new ADS Agentless Collector.
Disclaimer
By the time I am writing this, AWS hasn’t yet provided an official way to configure a proxy that is to be used for internet access. Before proceeding, please check the official documentation to check if this has changed.
Technical background
The collector is deployed as a VM inside the on-premises VMware environment from an OVA image provided by AWS.
When booted, the VM launches a Docker environment that hosts the application inside 4 different containers. Those containers contain the collector that consists of different services, all developed in Java and deployed on top of an Amazon Corretto JVM.
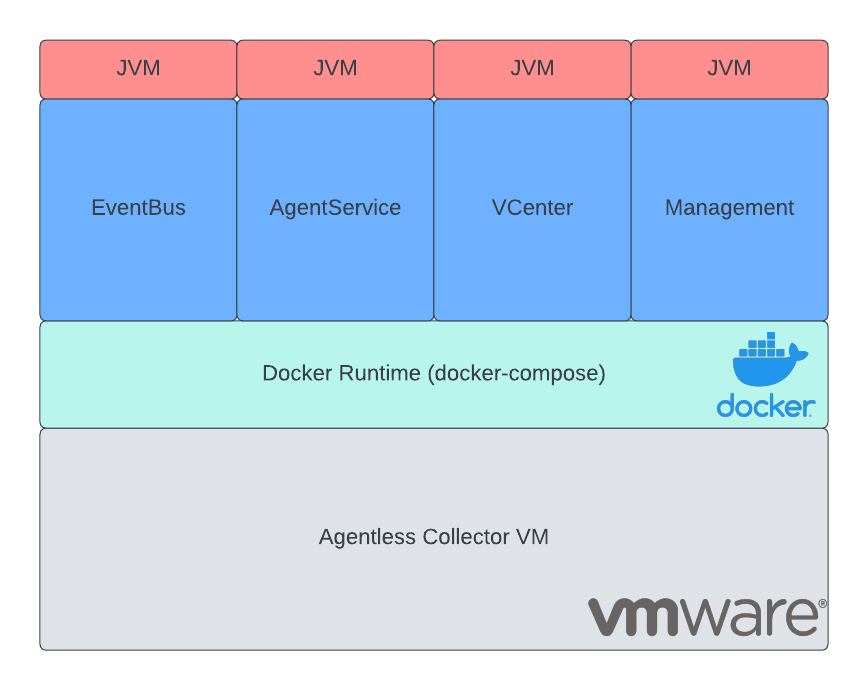
Solution (High-Level)
Two things are required to enable the proxy:
-
Set system-wide proxy on each container
This step is standard within Linux environments. The proxy is set by exporting the environment variables HTTP_PROXY and HTTPS_PROXY as described here.
-
Tell JVM to use the proxy
This is where it gets tricky. Unlike other tools like
curl, Java doesn’t use the system proxy by default. One way to enable this setting is by defining it during launch of the Java application.During launch, the following flag needs to be set in the command:
-Djava.net.useSystemProxies=trueFor our use case, the best option is to hack into the java startup script used by the Docker container and add the flag. Luckily, the developers thought of such a situation and enhanced the script with an empty placeholder variable
JVM_ARGSthat can be used to add the flag.The solution is therefore to set the environment variable accordingly:
export JVM_ARGS="-Djava.net.useSystemProxies=true"To make the setting effective, the Java process needs to be restarted.
Solution (Hands-On)
Above solution is best applied, by modifying the file /local/agentless_collector/docker-compose.yaml. That file is used to orchestrate and configure the different Docker containers.
Modify the file and add the following property block for each container:
environment:
- HTTP_PROXY=${HTTP_PROXY}
- http_proxy=${HTTP_PROXY}
- HTTPS_PROXY=${HTTPS_PROXY}
- https_proxy=${HTTPS_PROXY}
- JVM_ARGS=-Djava.net.useSystemProxies=true
Additionally, create a new file called .env and place it inside /local/agentless_collector/. Here, specify your proxy servers. Please remember to add authentification, if required.
HTTP_PROXY=http://internalproxy.com:8080
HTTPS_PROXY=https://internalproxy.com:8080
Afterwards, recreate the containers by running the below command inside the directory /local/agentless_collector/ . Please note, that this step probably deletes all settings that were previously made on the collector. However, usually, at this point, that shouldn’t be a problem.
docker-compose up --force-recreate -d