Implementing accurate counters in DynamoDB using Python
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Imagine you’re running a blog and want to display some statistics for articles, such as the number of views. DynamoDB can serve as the database for a system like that. I’m going to show you how and share some tips on improving the accuracy of these counters. I will assume some basic understanding about DynamoDB here, which you can get from my DynamoDB in 15 minutes post.
DynamoDB can be used to create counters for all kinds of things. Getting aggregates without computing them on the fly is often the motivation. Computing aggregates is expensive and an operation that doesn’t scale, so there is no native support for functions like sum() or avg() in DynamoDB that you may know from relational databases. Instead, we maintain the aggregates when writing to the table or asynchronously through DynamoDB streams and a Lambda function.
Let’s suppose we’re running our blog and want to create statistics about how many times each blog post is viewed. We send a view event from the browser to our webserver a few seconds after the page is loaded to avoid counting page impressions that aren’t very meaningful. The view event that our backend receives can look something like this.
{
"url": "myblog.com/article1",
"time": "2022-03-28T13:17:23+00:00",
"clientId": "adidOIkenODSksi92LHd6"
}
Now we can create a statistics item in a table to collect the views. Our table blog_data may look something like this in a single table design.
| PK | SK | views |
|---|---|---|
URL#myblog.com/article1 |
STATISTICS |
32 |
URL#myblog.com/post23 |
STATISTICS |
64 |
Here is a very naive and flawed implementation of a function that maintains the view counter.
def very_naive_view_counter(view_event: dict, table_name: str):
table = boto3.resource("dynamodb").Table(table_name)
blog_url = view_event["url"]
# Increment the view counter by 1
table.update_item(
Key={
"PK": f"URL#{blog_url}",
"SK": "STATISTICS"
},
UpdateExpression="SET #views = #views + :increment",
ExpressionAttributeNames={
"#views": "views"
},
ExpressionAttributeValues={
":increment": 1
}
)
At first glance, there is no issue, but we’re running into a problem when the blog is viewed for the first time. We can only use SET like this if the attribute exists already. That’s not the case on the first view, so we have to think of something else. One approach would be to use ADD in the update expression, which can increment the counter and assumes it starts at zero if the attribute doesn’t exist. The documentation discourages using ADD for some unknown reason and recommends we go with SET instead. Fortunately, there is some trick we can do to improve the situation. The built-in if_not_exists function allows us to set an initial value if the attribute doesn’t exist yet.
def less_naive_view_counter(view_event: dict, table_name: str):
table = boto3.resource("dynamodb").Table(table_name)
blog_url = view_event["url"]
# Increment the view counter by 1
table.update_item(
Key={
"PK": f"URL#{blog_url}",
"SK": "STATISTICS"
},
UpdateExpression="SET #views = if_not_exists(#views, :init) + :inc",
ExpressionAttributeNames={
"#views": "views"
},
ExpressionAttributeValues={
":inc": 1,
":init": 0
}
)
This implementation handles the initial view and is a superior implementation to the original one. The solution is acceptable as long as we can guarantee that each view event is processed exactly once. If we process the same event twice, our counter will be out of sync with reality because we have no deduplication of view events here. Can we assume that each view event will be processed exactly once? That depends on your architecture. In most standard serverless implementations, that’s not the case. Let’s see why.
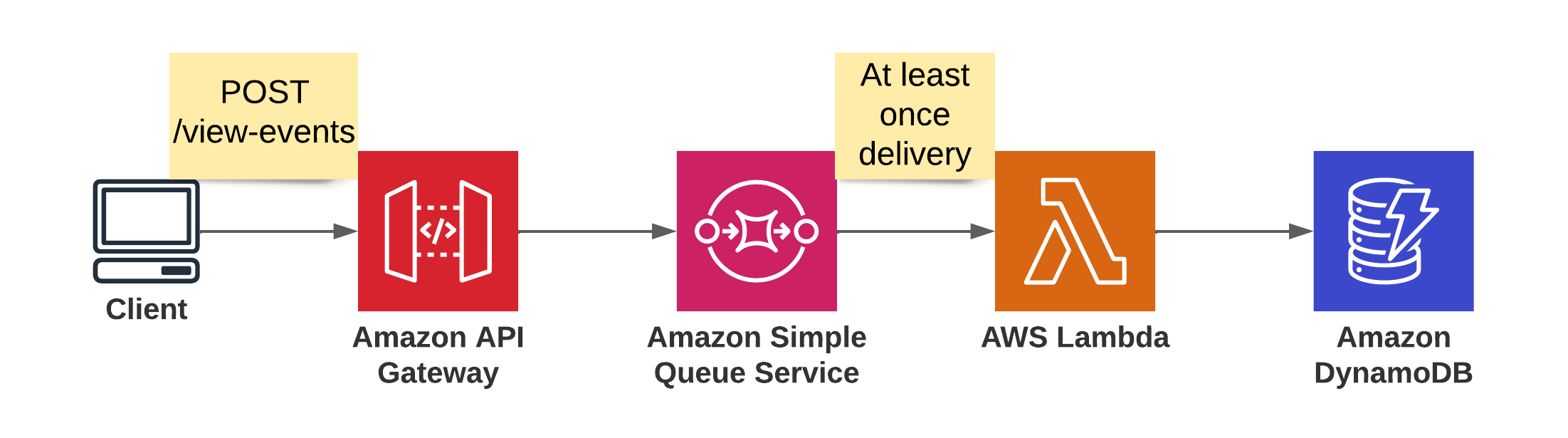
Above, you can see an example architecture for our view-statistics system. We have an API Gateway that accepts the view events the client sends to it. The API gateway delivers the event to an SQS queue and returns status code HTTP 201 (Accepted), so the client can continue doing its thing and doesn’t have to wait for the backend. A Lambda function in the backend processes the events from the Queue and maintains the counters in DynamoDB. The integration between SQS and Lambda is the problem here. We only get the guarantee that events are processed at least once. This means a view event can get processed two or more times. In this specific architecture, we could also opt for a first-in, first-out (FIFO) queue, but that limits the throughput of our system and may end up becoming a bottleneck.
Instead, we can solve the deduplication problem within our table by storing the view events we have processed successfully. This changes our original table design a bit. Here is the revised version that also includes the view event information.
| PK | SK | views |
|---|---|---|
URL#myblog.com/article1 |
STATISTICS |
3 |
URL#myblog.com/article1 |
T#2022-03-28T13:17:23+00:00#CID#adidOIkenODSksi92LHd6 |
|
URL#myblog.com/article1 |
T#2022-03-28T13:17:38+00:00#CID#kdajIkenODSksiasde36 |
|
URL#myblog.com/article1 |
T#2022-03-28T14:36:23+00:00#CID#adsdfgIkenODSkggd6 |
|
URL#myblog.com/post23 |
STATISTICS |
1 |
URL#myblog.com/post23 |
T#2022-03-28T14:36:23+00:00#CID#adsdfgIkenODSkggd6 |
What makes your event unique is a crucial design consideration here. You could compute a hash over the whole event and use that as the sort key in the schema, which can be a good approach. In my case, I decided to do something like that more implicitly. The combination of the values in url, time, and clientId uniquely identifies a view event. All of them are present in the item’s primary key, which is enough for deduplication. I didn’t opt for the hash calculation here because laying out the data in the table this way allows me to query all view events within a specific time frame, which I may want to do.
Another approach I could have used here is to choose only the clientId as the sort key. That means views by the same clientId will only be counted once. I specifically didn’t do that because if somebody decides to read the blog two or three times at different dates, I want to count those as separate views. I could have also chosen only the date part of the timestamp and the clientId to restrict the number of views per client to one per day in my statistics - lots of options. Which is the best for you depends on your use case.
Now we need to make sure that we only increment our views counter if the view event with the timestamp and clientId is not yet present in the table. We could do that through a conditional put for the view event and only update the counter if the conditional put worked, but that would be subject to race conditions. The transactions API is a much better solution here. Transactions allow us to perform changes in an all-or-nothing manner (ACID). That means either all changes in the group are successfully applied, or all of them will be rolled back. In the following implementation, we’ll use this to combine our conditional put request for the event with the counter increment. This means our counter won’t be updated if we have already processed the view event.
def accurate_view_counter(view_event: dict, table_name: str):
# transactions are only supported using the client API
client = boto3.client("dynamodb")
partition_key = f"URL#{view_event['url']}"
sort_key_stats = "STATISTICS"
sort_key_event = f"T#{view_event['time']}#CID#{view_event['clientId']}"
try:
client.transact_write_items(
TransactItems=[
{
"Put": {
"TableName": table_name,
"Item": {
"PK": {"S": partition_key},
"SK": {"S": sort_key_event}
},
"ConditionExpression": "attribute_not_exists(PK) and attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": table_name,
"Key": {
"PK": {"S": partition_key},
"SK": {"S": sort_key_stats}
},
"UpdateExpression": "SET #views = if_not_exists(#views, :init) + :inc",
"ExpressionAttributeNames": {
"#views": "views"
},
"ExpressionAttributeValues": {
":init": {"N": "0"},
":inc": {"N": "1"}
}
}
}
]
)
except ClientError as err:
if err.response["Error"]["Code"] == 'TransactionCanceledException':
# Already processed
print("View event was already processed")
else:
raise err
This approach will only update the views counter once per view event, which is a nice feature. It comes at a cost, though. We’re storing the view events in the table (albeit only in summarized form), which incurs storage costs, and using the transactions API, which consumes more read- and write-capacity units per operation than our naive implementations.
We can’t do much about the cost of the transactions API. This is just the cost of having an accurate counter. If you don’t need that level of accuracy, one of the earlier implementations may suffice. Fortunately, we can optimize the storage component of our costs a little bit. Typically duplicate events will arrive within a relatively short period, e.g., a few hours. Afterward, it’s improbable to see a specific event again. That means we can expire our view events from the table after some time, e.g., a week, and reduce our overall storage costs.
Below is an implementation that uses the time-to-live feature that’s built into DynamoDB to expire view events after some time. Note that they don’t expire precisely at this point but within about 24 hours of that point in time.
def accurate_view_counter_with_ttl(view_event: dict, table_name: str):
# transactions are only supported using the client API
client = boto3.client("dynamodb")
expire_after_seconds = 60 * 60 * 24 * 7 # a week
current_time_as_epoch = int(time.time())
expiry_time = current_time_as_epoch + expire_after_seconds
partition_key = f"URL#{view_event['url']}"
sort_key_stats = "STATISTICS"
sort_key_event = f"T#{view_event['time']}#CID#{view_event['clientId']}"
try:
client.transact_write_items(
TransactItems=[
{
"Put": {
"TableName": table_name,
"Item": {
"PK": {"S": partition_key},
"SK": {"S": sort_key_event},
"ttl": {"N": str(expiry_time)}
},
"ConditionExpression": "attribute_not_exists(PK) and attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": table_name,
"Key": {
"PK": {"S": partition_key},
"SK": {"S": sort_key_stats}
},
"UpdateExpression": "SET #views = if_not_exists(#views, :init) + :inc",
"ExpressionAttributeNames": {
"#views": "views"
},
"ExpressionAttributeValues": {
":init": {"N": "0"},
":inc": {"N": "1"}
}
}
}
]
)
except ClientError as err:
if err.response["Error"]["Code"] == 'TransactionCanceledException':
# Already processed
print("View event was already processed")
else:
raise err
Summary
In this post, we’ve done a deep dive into implementing counters in DynamoDB, learned about the transactions API, and design considerations concerning uniqueness in events. You can find the complete code I referred to here in this Github repository.
Hopefully, you gained something from this blog, and I’m looking forward to your questions, feedback, and concerns.
— Maurice