Implementing optimistic locking in DynamoDB with Python
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Concurrent write-access to the same data in databases can lead to consistency problems. This is also the case for data in DynamoDB. There are some patterns to resolve this and in this post we’re going to take a look at implementing optimistic locking in Python. Let’s not get ahead of ourselves though, first we’ll explore the problem, then discuss the solution and afterwards check out the implementation.
Problem
DynamoDB can be the single source of truth about data in an application. Different parts of the application will want to write to and read from it, at different times. With this being a central solution, with multiple clients doing multiple things simultaneously, conflicts may arise.
Let’s look at an example. Here, we have a banking table that keeps track of the current balance on a customer’s account and how much overdraft is allowed. Our account 123 has a current balance of 100 and is allowed to go down to -500 until further transactions are blocked.
| AccountId | Balance | OverdraftLimit |
|---|---|---|
| 123 | 100 | -500 |
| … | … | … |
Now suppose there are two parallel transactions that would like to decrease the balance in this account. The first tries to take out 400 and the second 300. If these are processed sequentially, we would arrive at a balance of 100 - 400 = -300, after the first transaction. Then the second transaction is processed and tries to subtract another 300. This would reduce it under the overdraft limit (-300 - 300 = -600 < -500). As a result the second transaction fails.
Having a single process that works on all transactions sequentially is inherently limiting, so we try to have multiple processes to work on transactions in parallel. Each worker process does the following:
- Read the current record from the table
- Apply the transaction to the record if we don’t cross the overdraft limit
- Write the updated record to the database
The problem here is that there is a delay between the steps 1) and 3). The following diagram illustrates how this can become a problem.
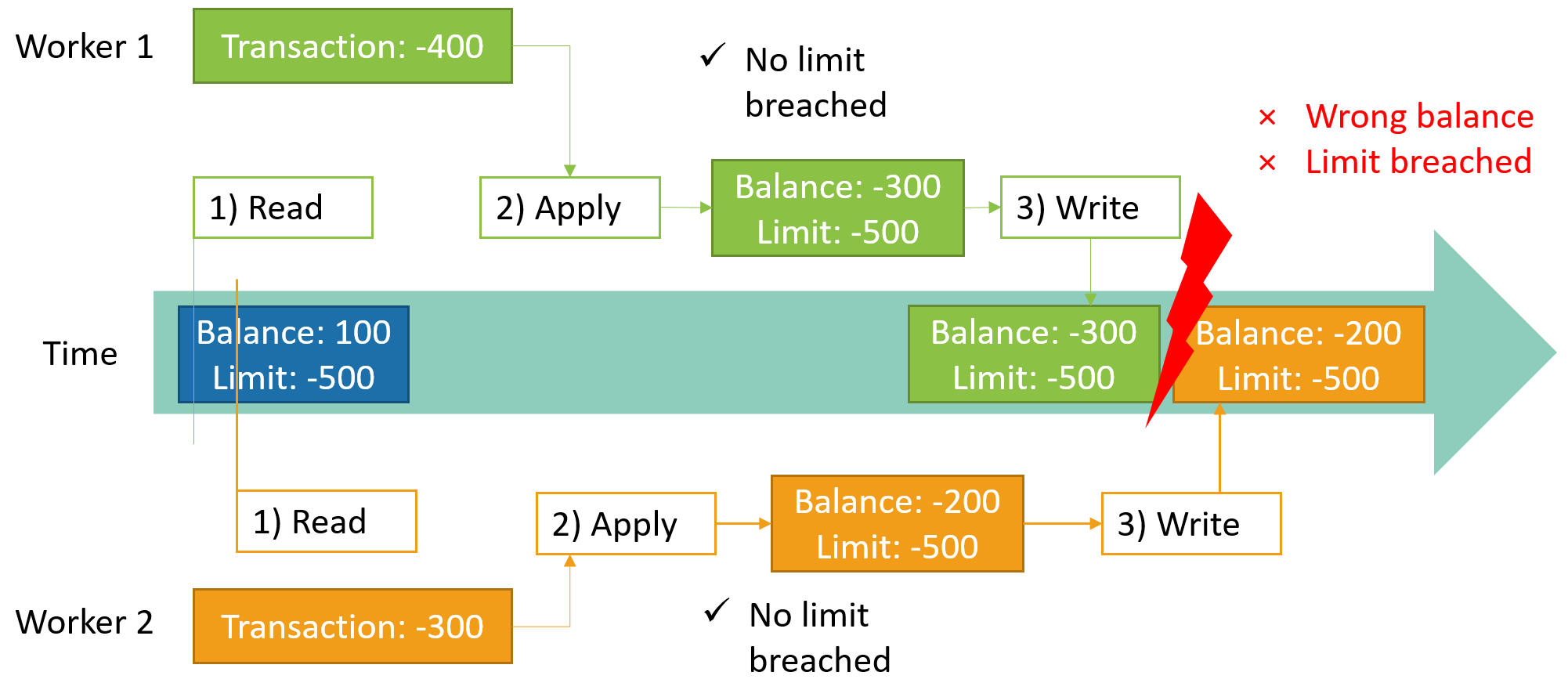
Each of our -400 and -300 transactions is handled by an individual worker process. Worker 1 has a tiny headstart and reads the current balance first. Shortly after that worker 2 also starts and reads the current balance. Now each of the workers applies the transaction to what they think is the current balance. In both individual cases the spending limit wouldn’t be breached. Since worker 1 started a little earlier it also finishes earlier and writes the updated balance back to the database. Worker 2 is closely behind, but unaware of this, and also writes its updated balance to the database - inadvertantly overwriting what worker 1 did.
This has two serious problems: The balance is wrong and one of the transactions shouldn’t have been possible, because the overdraft limit was breached. This is sometimes refered to as the lost update problem.
A system with these problems can be considered broken and in practice no bank operates that way. Let’s now take a look at how we can deal with conflicting access to a resource.
Solution
Handling concurrent conflicting access to a resource is typically handled through a process called Locking. There are countless different varieties and nuances to this but as the title suggests we’ll focus on a specific form. There are two basic approaches: optimistic and pessimistic locking.
Pessimistic locking means that you place a lock on a resource before you work on it. This lock is enforced by the resource itself and grants you exclusive access to the resource until you release the lock (or it expires). If others want to access the resource they may be locked out or restricted to read-only access depending on the implementation. Pessimistic locking is used when its costly to retry an operation or you expect lots of concurrent access.
Optimistic locking on the other hand favors a different approach. The underlying assumption is that most of the time there won’t be conflicting access to a resource, so there are no exclusive locks with the associated performance overhead. Instead this technique aims at detecting conflicts when they occur and allow you to handle them gracefully.
The idea is that each item in the table gets a version attribute that is just a number which is incremented on each update/put to that item. When you first read the item, you take note of which version it had, when you read it (current_version). You can then locally process the item and make any changes to it. Before you persist your changes, you should increase the version number on the item.
The important part comes when you write the item back to DynamoDB. You can use a regular PutItem or UpdateItem call, but you have to add a ConditionExpression that checks that the value of the version attribute is still equal to current_version. This ensures you only update the item if it’s in the same state it was in when you first read it. If the condition doesn’t hold true, the update/put is cancelled and an exception is raised. You can then read the item again, redo your processing and try writing it to the table.
This is an effective way to handle scenarios, where collisions are rare and re-processing is cheap. Let’s now look at an example how the worker process from our banking use case could be implemented.
Implementation
Below you find an annotated python script. The original read, apply and write steps have been slightly adjusted. In the read step we also store the current_version of the item. Before writing it back, we increment the version number by 1 and then add the condition expression to the put_item call. The exception handling for the condition check looks a bit clunky, but unfortunately boto3 doesn’t expose a “pretty” exception.
import boto3
from boto3.dynamodb.conditions import Attr
# Step 0 Init
table = boto3.resource("dynamodb").Table("accounts")
transaction_value = -400 # This would come from somewhere else
# Step 1 Read the current item
item = table.get_item(Key={"AccountId": "123"})['Item']
# This is how item looks like:
# {
# "AccountId": "123",
# "Balance": 100,
# "OverdraftLimit": -500,
# "Version": 0,
# }
current_version = item["Version"]
# Step 2 Apply transaction
if item["Balance"] + transaction_value >= item["OverdraftLimit"]:
item["Balance"] += transaction_value
else:
raise ValueError("Overdraft limit breached!")
# Step 3 Write
# 3.1 Increase the version number so other workers know something changed
item["Version"] += 1
# 3.2 Try to write the item, but only if it hasn't been updated in the mean time
try:
table.put_item(
Item=item,
ConditionExpression=Attr("Version").eq(current_version)
)
except ClientError as err:
if err.response["Error"]["Code"] == 'ConditionalCheckFailedException':
# Somebody changed the item in the db while we were changing it!
raise ValueError("Balance updated since read, retry!") from err
else:
raise err
Summary
In this post we looked at the problems that can arise when you access the same item in DynamoDB from multiple resources at the same time. Optimistic locking is one technique to detect and handle these concurrent accesses. We also saw what a simple implementation of the concept can look like in Python.
Thank you for reading this blog post. If you have any questions, concerns or feedback, don’t hesitate to reach out.
— Maurice