Modelling a product catalog in DynamoDB
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Today we’ll talk about a topic I’ve been interested in for a few months now: data modelling in NoSQL databases, especially DynamoDB. This article assumes basic knowledge of DynamoDB, which you can get from reading DynamoDB in 15 minutes. I was inspired to write this by a question that I answered on stackoverflow a while ago. This finally gave me an excuse to write about the topic.
I’m going to introduce you to a user story first, then we’re going to discuss the process of data modelling in NoSQL environments. Afterwards we’ll move on to building the data model for the user story. Sprinkled throughout this, I’ll show you some code examples for your data access layer.
User Story
![]()
Fromatoz is a fictional online retailer that offers a platform, where products from different brands across various product categories are being sold. Customers can browse products by brand and have the option to filter the products from the brand by categories. Another way customers can use the product catalog is that they look at a specific category and see the products all brands offer in that category. Since the products have varying kinds of properties, Fromatoz wants to use a NoSQL database because of its flexible schema.
The customer also wants to track the stockpile for each product. This means that the available stock should be decreased upon purchases made by customers and increased upon arrival of new shipments. The inventory team needs to be able to quickly retrieve the current stock level for a given product.
Let’s talk about the process we can use to turn Fromatoz’ requirements into reality.
Data modelling in NoSQL environments
The process of data modelling in a non-relational world is somewhat different from traditional data modelling for relational databases. Fortunately there are some steps you can follow to create your data model.
Since I didn’t come up with these steps myself, I’m going to quote from the DynamoDB book by AWS Data Hero Alex DeBrie. The steps are:
- Understand your application
- Create an entity-relationship diagram (“ERD”)
- Write out all of your access patterns
- Model your primary key structure
- Satisfy additional access patterns with secondary indexes and streams
— Alex DeBrie, The DynamoDB Book - chapter 7.2
The first step should seem fairly obvious, we need to have an understanding of the domain we’re working in. In our case I’ve outlined the required information above and since you’ve most likely used a webshop in the past, you should be good to go.
Creating an entity-relationship-diagram may not seem obvious at first, since we’re talking about a non-relational database. Actually the term non-relational database is misleading, in my opinion, because data in it still has relationships. The way these relationships are handled and modelled is just different from relational databases. In order to have a common basis to discuss requirements, query patterns and all of these fancy constructs, an ERD is a good start.
Once we’ve gotten an understanding of which entities exist and how they’re related, we have to find out and define how these are queried. This step is critical - our access patterns will determine how we store and index our data.
The next two steps are what makes or breaks our data model: we create the primary key structure to satisfy our primary access patterns and use local and global secondary indexes as well as DynamoDB streams to enable additional access patterns.
Now that we’ve talked about the process and introduced the use case along with the challenges it presents, let’s move on to step two: the entity relationship diagram.
Entity Relationship Diagram
Here’s a simple ERD for our use case (I’m aware it’s not up to UML standards, but it’s good enough):
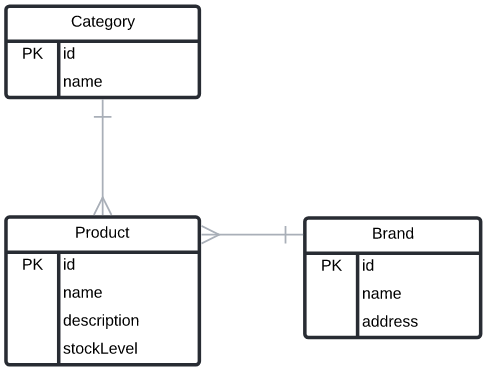
The diagram is fairly simple and consists only of three entities, product, brand and category. Categories can have multiple products and brands can have multiple products. Each product belongs to one brand and one category. This means we’re going to have to model two one-to-many relationships (I’ll talk about many to many relationships in a future post).
That takes care of the entity relationship diagram, let’s talk about access patterns.
Access Patterns
In order to understand how we’ll access the data in the product catalog, we need to take a closer look at the use case description again. From there we can come up with these access patterns:
- Get all brands
- Get all categories
- Get product by id (for the stock level query)
- Decrease stock level for product
- Increase stock level for product
- Get products by brand
- Get products by brand and category
- Get products by category
- (Get products by category and brand)
Access pattern 9 is optional, because the result of a query would be identical to that of access pattern 7. From the perspective of a user interface the difference between 7 and 9 matters, but the data layer would return the same results. We will still model access pattern 9, because, depending on the distribution of the data, it may be advantageous to choose one over the other.
Now it’s time to build a model for these access patterns.
Building the model
First we take a closer look at the access patterns and structure them for ourselves. We identify the entities affected by each access pattern and the information that will be sent via the parameters to perform the read or write operations.
| # | Entity | Description | Parameters |
|---|---|---|---|
| 1 | Brand | Get all | |
| 2 | Category | Get all | |
| 3 | Product | Get by id | <pid> (Product ID) |
| 4 | Product | Decrease stock | <pid> + <stockDecrement> |
| 5 | Product | Increase stock | <pid> + <stockIncrement> |
| 6 | Product | List by brand | <bid> (Brand ID) |
| 7 | Product | List by brand and category | <bid> + <cid> (Category ID) |
| 8 | Product | List by category | <cid> |
| 9 | Product | List by category and brand | <cid> + <bid> |
From this table we can see, that the majority of access patterns affect the product entity, which shouldn’t come as a surprise, as this is a product catalog. Before we talk about the more complex entity, let’s begin modelling with the brand and category entities, which account for the access patterns 1 and 2.
Both of them require a list of all entities of that type. If we recall the APIs available to us, we know that there are three ways to get multiple items out of DynamoDB:
BatchGetItem, which batches multipleGetItemcalls together and requires us to know the partition and sort key for all items we want to select.Query, which allows us to work on collections of items (those that share the same partition key) and optionally do some filtering on the sort key in the partition.Scanis essentially a table scan and by far the slowest and most expensive operation.
Since we don’t know all primary keys for all brands or categories, we can rule out BatchGetItem.
We want to avoid Scan at all costs.
So let’s see how we can do this using Query.
With Query we can easily get a whole item collection by querying for a partition key and not filtering on the sort key.
This is what we’re going to use to enable the access patterns 1 and 2.
I have started modelling the table below:
| PK (Partition Key) | SK (Sort Key) | type | name | brandId | categoryId |
|---|---|---|---|---|---|
| BRANDS | B#1 | BRAND | Microsoft | 1 | |
| BRANDS | B#2 | BRAND | 2 | ||
| BRANDS | B#3 | BRAND | Tesla | 3 | |
| CATEGORIES | C#1 | CATEGORY | Cars | 1 | |
| CATEGORIES | C#2 | CATEGORY | Boats | 2 | |
| CATEGORIES | C#3 | CATEGORY | Phones | 3 |
Our table has a composite primary key, that’s made up of PK as the partition key and SK as the sort key.
I have decided to prefix the sort key values with B# for brand ids and C# for category ids.
You’ll see me doing this throughout the post.
This helps with namespacing items in the table, since we’re putting all entities in a single table.
Another thing you can observe is that the brand ids and category ids are both attributes as well as values for key-attributes.
This duplication is introduced on purpose to help distinguish between key-attributes and what I like to call payload-attributes.
It makes serialization and deserialization easier.
The type attribute also helps with deserialization.
To get a list of brands, we can now do a simple query like this one in python, which would return the first three rows of the table - the code for the CATEGORIES collection would look very similar:
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_all_brands() -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("data")
response = table.query(
KeyConditionExpression=conditions.Key("PK").eq("BRANDS")
)
return response["Items"]
Note: If there are lots of reads/writes to these partitions you can consider read/write sharding-techniques, but that’s beyond the scope of this article. They help avoid hot partitions at the cost of data access layer complexity.
Moving on to the product entity.
We have seven access patterns to eventually deal with, but we’ll tackle them in batches.
First we’ll model fetching of a product by its product id as well as incrementing and decrementing of stock values.
Since a product id is unique, this is an ideal use case for a GetItem operation, because we only want to fetch one item and know the key information for it.
We’ll use the same table we already used for the other entities, this is called single-table-design.
Because of space constraints the layout of the table is flipped here and only focuses on the product entity.
| Attribute | value |
|---|---|
| PK | P#1 |
| SK | METADATA |
| type | PRODUCT |
| name | Model 3 |
| productId | 1 |
| stockLevel | 70 |
| categoryId | 1 |
| brandId | 3 |
By setting it up this way we can easily request a product by it’s ID and also increment and decrement the stock level.
Below you can see an example implementation in python for get_product_by_id and increment_product_stock_level - the decrement would look very similar.
import boto3
def get_product_by_id(product_id: str) -> dict:
table = boto3.resource("dynamodb").Table("data")
response = table.get_item(
Key={
"PK": f"P#{product_id}",
"SK": "METADATA"
}
)
return response["Item"]
def increment_product_stock_level(product_id: str, stock_level_increment: int) -> None:
table = boto3.resource("dynamodb").Table("data")
table.update_item(
Key={
"PK": f"P#{product_id}",
"SK": f"METADATA",
},
UpdateExpression="SET #stock_level = #stock_level + :increment",
ExpressionAttributeNames={
"#stock_level": "stockLevel"
},
ExpressionAttributeValues={
":increment": stock_level_increment
}
)
Let’s take a look at the table we’ve created so far. The diagram below doesn’t contain exactly the same values as the tables above - it’s designed to show our key patterns. I suggest that you go through the five query patterns we’ve implemented so far in your head and try to visualize how they’re retrieved from the table.
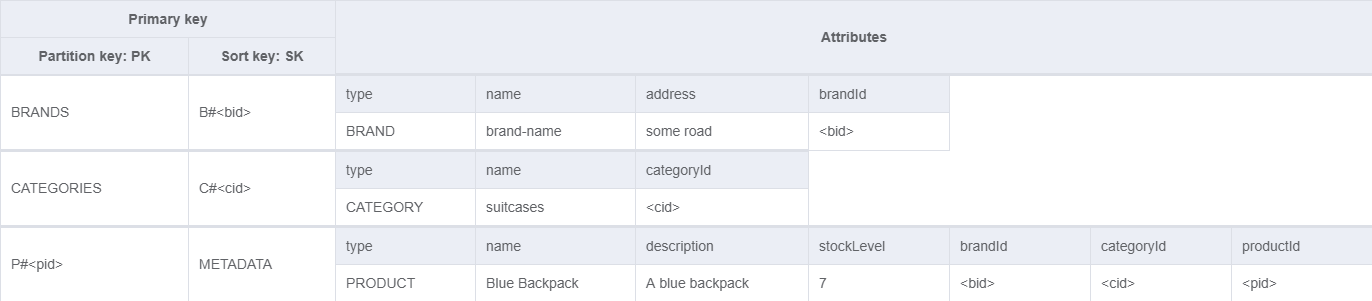
Now it’s time to talk about the remaining four access patterns.
| # | Entity | Description | Parameters |
|---|---|---|---|
| 6 | Product | List by brand | <bid> (Brand ID) |
| 7 | Product | List by brand and category | <bid> + <cid> (Category ID) |
| 8 | Product | List by category | <cid> |
| 9 | Product | List by category and brand | <cid> + <bid> |
After taking a closer look at them, we can see that these four access patterns can be divided into two groups that are very similar. Patterns 6 and 7 both start with the brand id as a first filter and 7 adds the category as an additional filter to the result from 6. Patterns 8 and 9 are similar - 8 filters based on a category and 9 is an additional filter on the result from 8. That means if we solve either of the combinations, we have a pattern that we can re-use for the other.
I usually start at the top of the list and work my way downwards, but it doesn’t really matter. So let’s consider 6 and 7 first. Access pattern 6 essentially requires us to model the one-to-many relationship between a brand and its products. We’ve already seen a pattern that allows us to do this. Use the partition key for the parent and the sort key for the children, which allows us to query for them. We can use this here as well, but there is a problem. The primary index for our table and the product index is already being used to satisfy the access patterns 3 to 5.
Since our primary index is already in use, we should take a look at the secondary indexes.
A local secondary index would require us to use the same partition key, but we could choose a different sort key.
This doesn’t help us here, because the product’s partition key is its ID and we would need that to be the brand it belongs to.
That leaves us with a global secondary index (GSI), which allows us to choose both a different partition and sort key.
Let’s add a GSI, which we’re going to call GSI1 with GSI1PK as its partition- and GSI1SK as its sort key.
Generic names again, because we could use them to fulfill multiple access patterns.
The simplified table looks like this.
| PK | SK | type | GSI1PK | GSI1SK |
|---|---|---|---|---|
P#<pid> |
METADATA |
PRODUCT |
B#<bid> |
P#<pid> |
This design allows us to deliver on access pattern 6.
If we take a look at access pattern 7, we have already observed that it’s essentially another filter on the result of 6.
There are multiple ways to implement this, but there is a particular one that I prefer.
When using Query to fetch items from a table, we can do some filtering on the sort key - among others there is a begins_with operator - which we can use to utilize GSI1 for query pattern 7 as well.
To achieve that, we slightly modify our key-schema from above to look like this:
| PK | SK | type | GSI1PK | GSI1SK |
|---|---|---|---|---|
P#<pid> |
METADATA |
PRODUCT |
B#<bid> |
C#<cid>#P#<pid> |
We prepend the category ID to GSI1SK, which allows us to use begins_with on it, while at the same time retaining the ability to do the query for 6.
The product ID still needs to be kept as part of the sort key, because we need each product to show up and that only happens, if the products are distinct in the GSI.
An implementation in Python for these two might look something like this:
import typing
import boto3
import boto3.dynamodb.conditions as conditions
def get_products_by_brand(brand_id: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("data")
response = table.query(
IndexName="GSI1",
KeyConditionExpression=conditions.Key("GSI1PK").eq(f"B#{brand_id}")
)
return response["Items"]
def get_products_by_brand_and_category(brand_id: str, category_id: str) -> typing.List[dict]:
table = boto3.resource("dynamodb").Table("data")
response = table.query(
IndexName="GSI1",
KeyConditionExpression=conditions.Key("GSI1PK").eq(f"B#{brand_id}") \
& conditions.Key("GSI1SK").begins_with(f"C#{category_id}#")
)
return response["Items"]
This takes care of access patterns 6 and 7.
I have added a further optimization, which isn’t visible in the code, because it relates to GSI1.
When you define a GSI in DynamoDB you can select which attributes should be projected into that index.
There are three possible configuration parameters:
KEYS_ONLY- only the keys for the GSI are projected into the GSI (least expensive)INCLUDE- you get to specify which attributes are projected into the GSIALL- projects all attributes into the GSI (most expensive)
Since we only really care about the type, name, description, stockLevel and productId when we query for products, I chose INCLUDE as the projection type and only projected these onto the index.
This results in GSI1 looking like this:

To implement the remaining two access patterns, we essentially do the same.
We can’t reuse GSI1 here, because, in this case, our partition key will have to be the category id.
That’s why we set up GSI2 with the partition and sort keys GSI2PK and GSI2SK with the same projection as GSI1.
The data in GSI2 looks very similar to GSI1 as a result of that (except for the primary key).

Earlier I mentioned that access patterns 7 and 9 are essentially identical in the items they return, but that it’s advantageous to use one over the other depending on the data distribution.
For this we have to consider how data is layed out in DynamoDB internally.
Item collections are assigned to a storage partition depending on their partition key, i.e. all items with the same partition key live on the same storage partition.
To improve scalability we try to spread out the load across these partitions evenly.
One way to do that is by querying the item collections with many distinct values.
If we have many brands but few categories, that means we’ll have many brand partitions and using GSI1 for that spreads out the load more evenly.
Should we have many more categories than brands, GSI2 will be better suited for this.
The data model allows us this flexibility at the cost of a few more bytes in storage space.
Now we’ve created a table structure that supports all of your nine access patterns! Let’s check out the final table. First we start with our key structure. The table below shows the attributes each entity needs for the access patterns to work. By now you should be able to see how we can use each of them to fulfill the access patterns.
| Entity | PK | SK | GSI1PK | GSI1SK | GSI2PK | GSI2SK |
|---|---|---|---|---|---|---|
| Brand | BRANDS |
B#<bid> |
||||
| Category | CATEGORIES |
C#<cid> |
||||
| Product | P#<pid> |
METADATA |
B#<bid> |
C#<cid>#P#<pid> |
C#<cid> |
B#<bid>#P#<pid> |
If we now look at the whole table, we can see that it’s starting to get fairly complex. That’s part of the reason, why browsing a DynamoDB table based on single-table-design from the console isn’t that convenient. I prefer to build a CLI tool, that uses my data access layer, to browse through the table; but that’s application specific and a topic for another day.
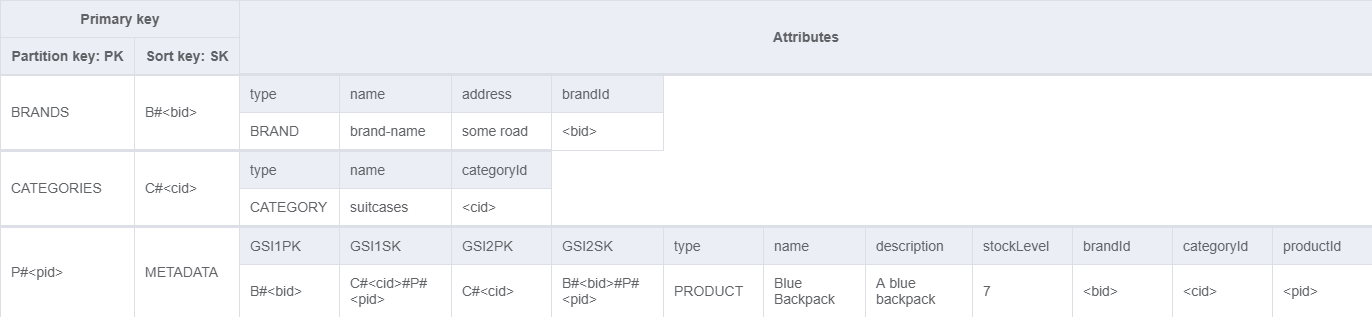
Wrap up
Let’s wrap this up for today. In this post we have gone through the process of modelling a product catalog in DynamoDB. We started with the use case description, then built an entity relationship diagram, identified our access patterns and then designed our primary key structure as well as secondary indexes to implement the access patterns. We also looked at some code examples of how a data access layer could fetch the data and perform update operations.
This article has been focused on one-to-many relationships and the different ways they can be modelled as well as the process of turning a use case description into a data model. If you have feedback, questions or want to get in touch to discuss projects, feel free to reach out to me through the social media channels in my bio.
— Maurice