Why I had to update my mental model of DynamoDB streams
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
I really enjoy delivering trainings, because they inevitably make you challenge what you think you know. Students come from all sorts of different backgrounds and bring their own unique perspective, which causes them to ask interesting questions. In this case my existing mental model of DynamoDB streams was challenged during a class when we were doing an exercise with serverless technologies.
The exercise is pretty cool and below I’ve shown an excerpt from the architecture diagram. The goal is to build an application to track the inventory levels of items in different stores. In the beginning inventory files are uploaded to S3 and a Lambda function picks up the event, downloads and parses the files and updates the inventory status in DynamoDB. DynamoDB has the streams feature enabled to notify another Lambda function about changes in the database. An inventory check lambda function then processes these updates and sends an SNS notification in case the stock levels for an item hit zero.
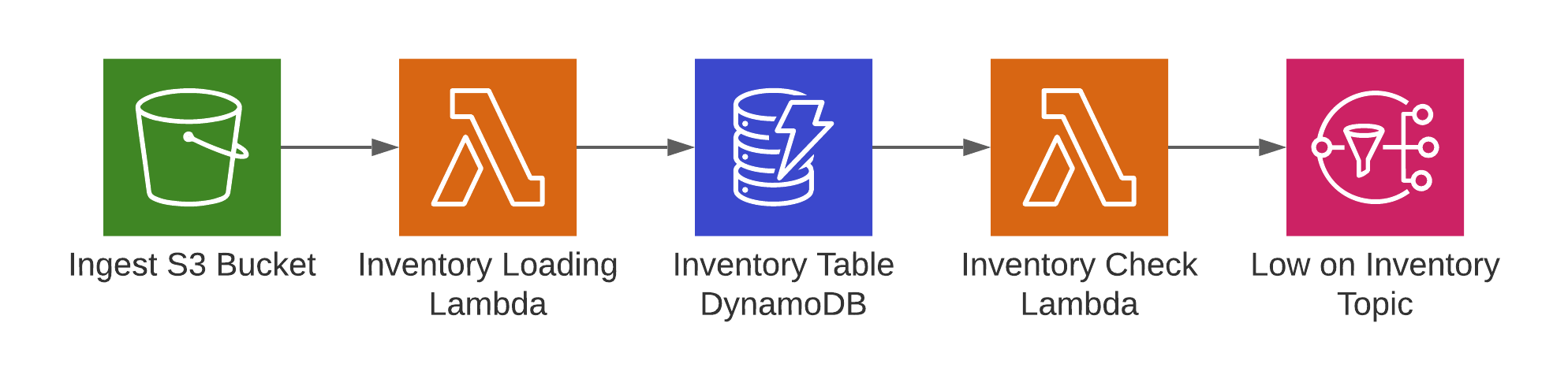
The students subscribe to the SNS topic with their phones and in an environment we were debugging while some SMS notifications took longer than expected.
I asked the student to upload the same inventory file again, so we’d trigger the process to send another SNS/SMS notification and they did, but nothing happened.
That surprised me, but I took it as an opportunity to teach the class about troubleshooting and debugging using the CloudWatch metrics and logs that had been created.
These metrics and logs proved that the inventory loading Lambda function was inserting the data into the table using the PutItem API call as expected.
For some reason this didn’t trigger the inventory check Lambda behind the stream.
Until that point my understanding of the implementation of DynamoDB streams had been roughly as follows.
- An API call is authenticated and hits the request router in DynamoDB
- The router then passes that request on to the appropriate partition (in case of writes, to the leader node)
- The partition performs the request
- If streams are enabled and it’s a
PutItem,UpdateItemorDeleteItemcall, it sends a record to the stream - It returns the result to the request router
Given that mental model of the operations below the hood, I had expected that even PutItem calls that didn’t actually change anything would result in another record in the stream.
This turned out to be incorrect, because only items that are created/deleted/updated cause a record to be added to the stream.
The documentation even has a nice info box describing this behavior, I had apparently missed that one.
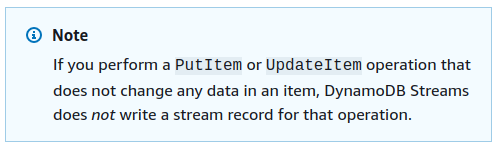
Reflecting on that, I don’t know why I had expected the API calls would cause updates to the stream regardless of their effects. The documentation is even titled “Change Data Capture for DynamoDB Streams” - so it makes sense only data that has actually been changed is recorded in the stream and not all attempted changes. I actually think this implementation is good, because otherwise you’d potentially see a lot of items that didn’t change in the stream. In case every update/put call is relevant to you, you still have the option to record these changes in the stream by actually changing the data.
The solution in the context of the exercise was actually very simple and just involved two additional lines of code.
It consists of an update to the inventory loading Lambda function.
I added another attribute to the inventory items called UpdatedAt, which holds the ISO8601 formatted timestamp of the update time.
Implementing something like this in python is trivial.
from datetime import datetime
# I added another attribute to the item
item = {
"UpdatedAt": datetime.now().isoformat()
}
This causes imports of the same inventory file at different times to have slightly different timestamps.
That results in real updates to the data and the items appearing in the stream.
In the context of the exercise, this solution is fine - in the real world you’d probably want to think about it a little longer.
Ideally the UpdatedAt value should be part of the inventory file and you should only update the value if the UpdatedAt timestamp of the existing item is older than the new one, which can be achieved using conditions.
Conclusion
In the context of DynamoDB streams not all PutItem and UpdateItem calls are created equal.
Only those that change the underlying data get recorded into the stream.
I hope you’ve enjoyed this article and if you liked it, you may want to check out this one, where my colleague David explains some of the hurdles trying to do secure cross-account Lambda invocations. If you want to get in touch, I’m available on the social media channels listed in my bio below.