How to accidentally create read-only DynamoDB items
In a recent Developing on AWS training, I taught my students the basics of DynamoDB. I usually do that by building up the concepts on a digital whiteboard. I think this helps students connect the many pieces of information to form a mental model of the service. Additionally, it’s more engaging for me as an instructor, invites conversations, and is a welcome break from the usual PowerPoint slides.
Having used DynamoDB for a couple of years and delivered that training many times, I rarely get questions about the service that I can’t answer off the top of my head. This time, there was a new one that intrigued me. A student asked me what happens if you add an item to a table with a global secondary index, where the attribute name is one of the index attributes, but the data type differs. I was under the impression that the datatypes are only enforced for the key attributes of the base table. Consequently, I thought the item would not appear in the global secondary index.
Turns out I was wrong. Let’s find out what actually happens.
First, we define a table with a simple primary key, PK, and the data type string. Later, we’ll add a global secondary index with the attribute GSI1PK of type string as its partition key.
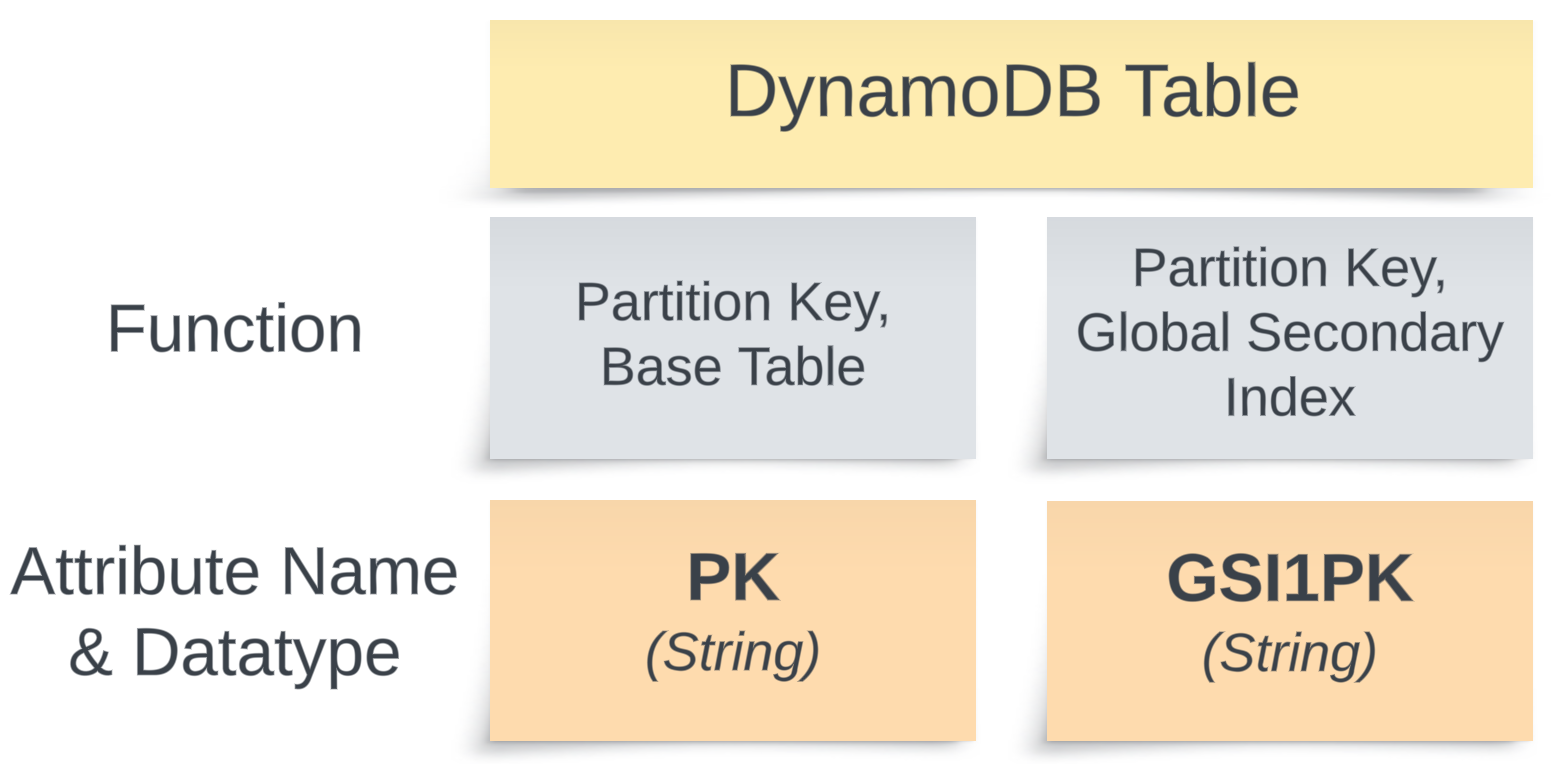
Before we create the global secondary index, we add a few items to the table:
// 1: Item with correct datatypes
{"PK": {"S": "ok"},"GSI1PK": {"S": "ok"}}
// 2: Item with incorrect datatype in the base table
{"PK": {"N": "123"},"GSI1PK": {"S": "ok"}}
// 3 & 4: Items with incorrect datatypes in the non-existent GSI
{"PK": {"S": "ok2"},"GSI1PK": {"N": "123"}}
{"PK": {"S": "ok3"},"GSI1PK": {"N": "123"}}
Writing all but the second item succeeds. When attempting to store the item with the Number data for the PK attribute, we receive a ValidationException with the message:
One or more parameter values were invalid: Type mismatch for key PK expected: S actual: N
This is what I expected—it enforces the data types for the base table’s index. At this point, it doesn’t care about the data type for the GSI1PK attribute as it doesn’t have any special meaning yet, so it accepts the PutItem calls for items 3 and 4.
Now, I add a global secondary index for the GSI1PK attribute. The nice thing about GSIs is that they can be added at any point in time, which is one of the things that makes them more flexible than their counterpart, the local secondary index. After waiting for it to backfill and become active, i.e., propagate the already existing data into the index, we can verify that only the item with the valid data types is available in this index by scanning it.
Items in GSI1: [{'PK': {'S': 'ok'}, 'GSI1PK': {'S': 'ok'}}]
Only the item with the correct datatypes ends up in GSI1
So far, this matches what I expected. The index skips items that have the key attributes but incorrect data types. My expectations weren’t met when I tried to store another item, like the ones in 3 and 4 in the index. This time, I got a familiar error:
(ValidationException) One or more parameter values were invalid: Type mismatch for Index Key GSI1PK Expected: S Actual: N IndexName: GSI1
This means as soon as a secondary index is created, DynamoDB starts enforcing the data type for all items written after it has been created. We could stop here, but this isn’t the full story. I was wondering what happens to the items 3 & 4, those with the incorrect data types in what has now become an index attribute.
I tried updating one of the items using the UpdateItem API to add another index-unrelated attribute to it and was met with the following error:
(ValidationException) The update expression attempted to update the secondary index key to unsupported type
Interesting. It effectively prevents us from changing the item. So, are we now stuck with a read-only item? Not quite. It seems DeleteItem is unaffected, and we’re able to clean up the mess. But what if you care about the data and prefer to try to fix it? You’re in luck - there’s one UpdateItem operation that DynamoDB will allow you to do:
client.update_item(
Key={"PK": {"S": "ok2"}},
UpdateExpression="SET GSI1PK = :val",
ExpressionAttributeValues={":val": {"S": "123"}},
TableName=TABLE_NAME,
)
You can replace the existing numeric value of GSI1PK with a string attribute, and that will make it writable once again and also add it to the GSI. If you want to try this yourself, I put the script and output on Github.
Having done my experiments, I researched the documentation, and unsurprisingly, I’m not the first to discover this. In detecting and correcting Index Key Violations, AWS outlines what my experiments also show:
“If an index key violation occurs, the backfill phase continues without interruption. However, any violating items are not included in the index. After the backfill phase completes, all writes to items that violate the new index’s key schema will be rejected.”
They even built a tool to detect and correct these cases, the DynamoDB Online Index Violation Detector tool, which is available on Github. Although it was last updated ten years ago and archived in 2020, it may no longer function as expected, but I haven’t tried it.
One of the reasons why I enjoy delivering courses is such questions. Explaining concepts forces you to challenge your own understanding, and doing it in front of others allows you to have them do the same based on their understanding. Everyone benefits, which I find a rewarding experience.
If you think these kinds of courses are right for you, check out our course catalog and get in touch. I’m sure we have a training that will intrigue you.
— Maurice