Using undocumented AWS APIs with Python
It’s probably not a surprise that (almost) everything Amazon Web Services offers is accessible through web services. AWS also provides a range of SDKs that make interfacing with and integrating them in your code base relatively painless. These SDKs are sometimes a bit limited, though. There are certain things that you can only do through the AWS console. Some services, like IAM Identity Center (formerly known as AWS SSO), had a reputation for being console-only for a long time, but that has improved over the last few years.
Console-only, in this case, means that there are still services under the surface, but they’re undocumented and not accessible through the official SDKs. Often, as is the case with the identity center, there are IAM actions to control access to APIs such as sso-directory:ListProvisioningTenants, but no official API documentation or SDK support (at the time of writing this). That API call is what we refer to as an undocumented API. The AWS console uses it, but it’s not exposed to customers via the SDK.
In this post, I’m going to show you how to discover these APIs and use them in your scripts. Later, we’ll also discuss whether that’s a good idea. In my case, I was looking for a way to get the SCIM configuration of our IAM Identity Center from a script. In the console, this information is exposed in the settings. Unfortunately, I wasn’t able to find any API in the documentation that gives me this information.
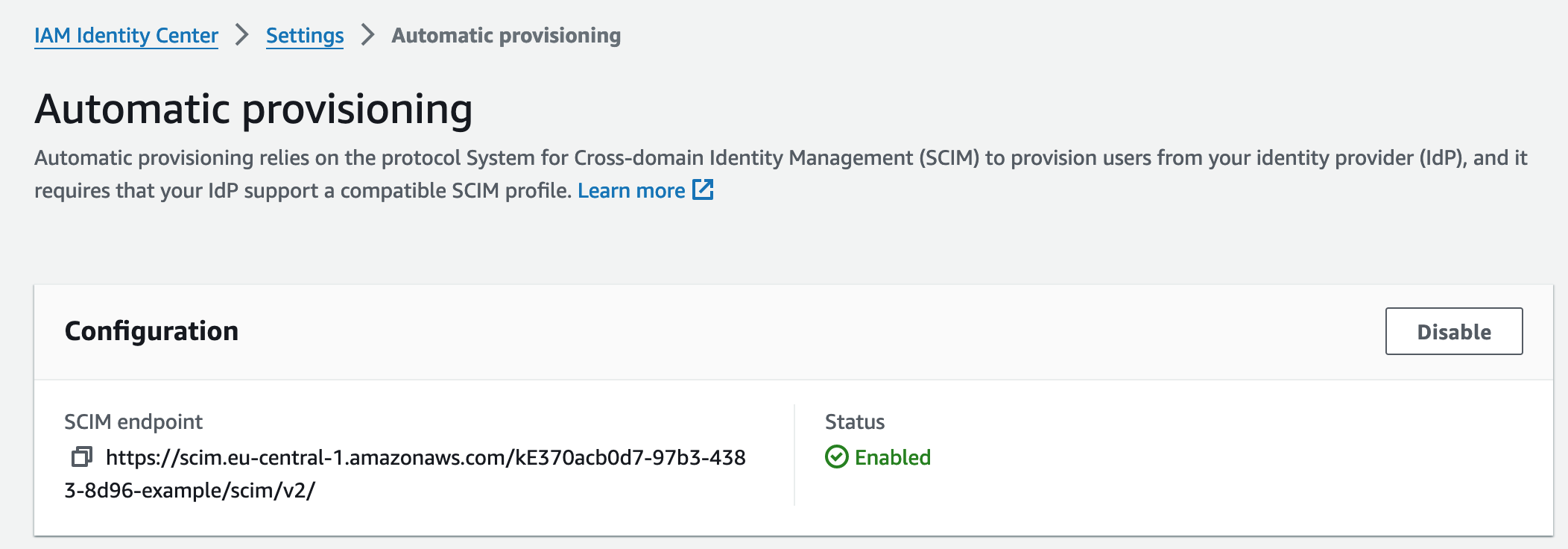
In these cases, it’s often a good idea to reverse engineer where the AWS console is getting that info. That’s not super difficult. We just hit F12 or right-click and Inspect to open the developer tools and navigate to the Network Tab. I’m using Firefox, it should look similar in other browsers. It should look something like this.
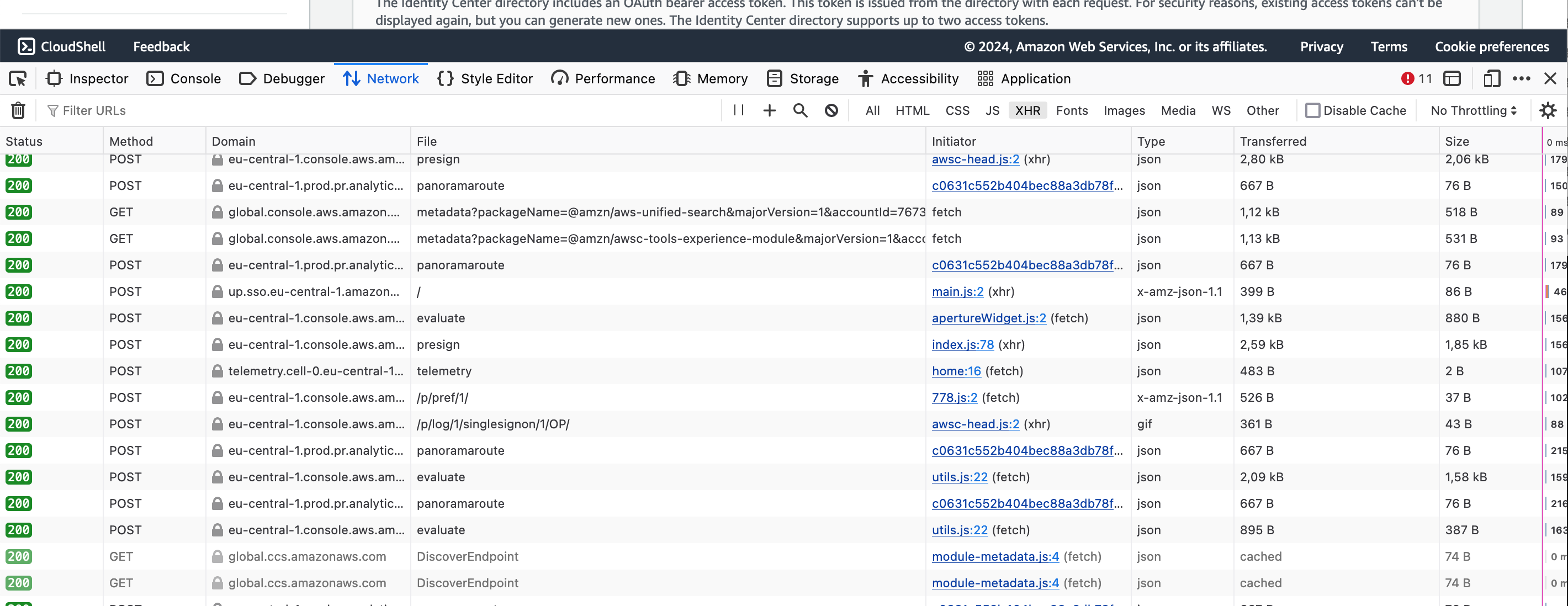
At first glance, it’s overwhelming, but we’ll narrow it down soon. In fact, this is already filtered to XHR requests (top-right), which means asynchronous requests for additional information to the AWS backend. There are a whole bunch of tracking requests here (e.g., everything with file: panoramaroute), which we can ignore. The interesting requests usually go to endpoints that are similar or identical to the service API namespace. In the case of the IAM Identity Center, there are multiple namespaces, e.g., sso-admin or identitystore. In my case, I filtered to domain:sso, which limited the requests to these.
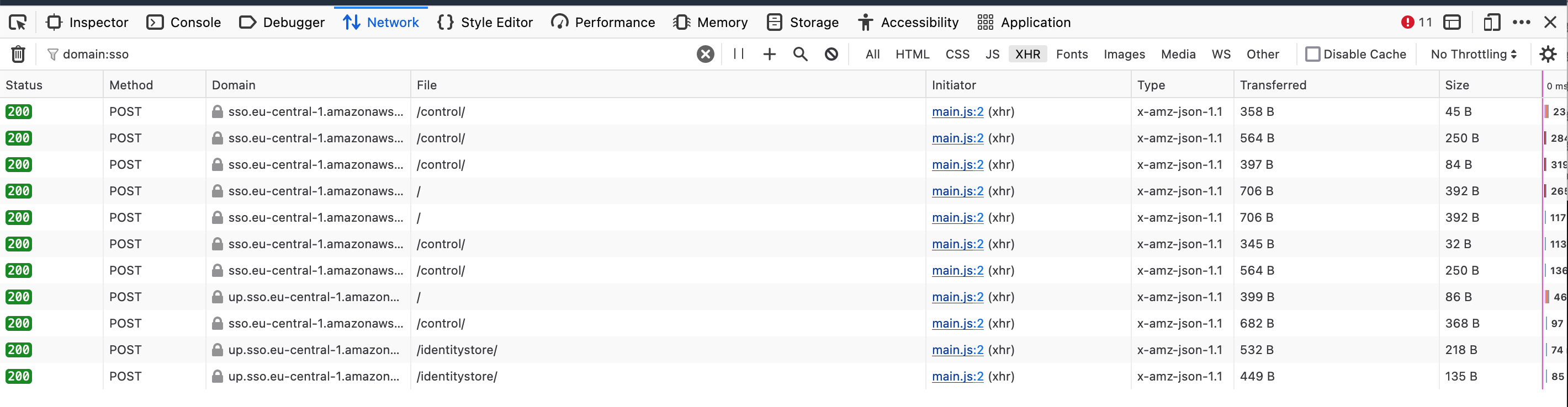
Next, we have to go through these requests and see which one returns the desired information, so click on them and check out the response. In my case, the data I was looking for looks like this. The TenantID is precisely what I need.
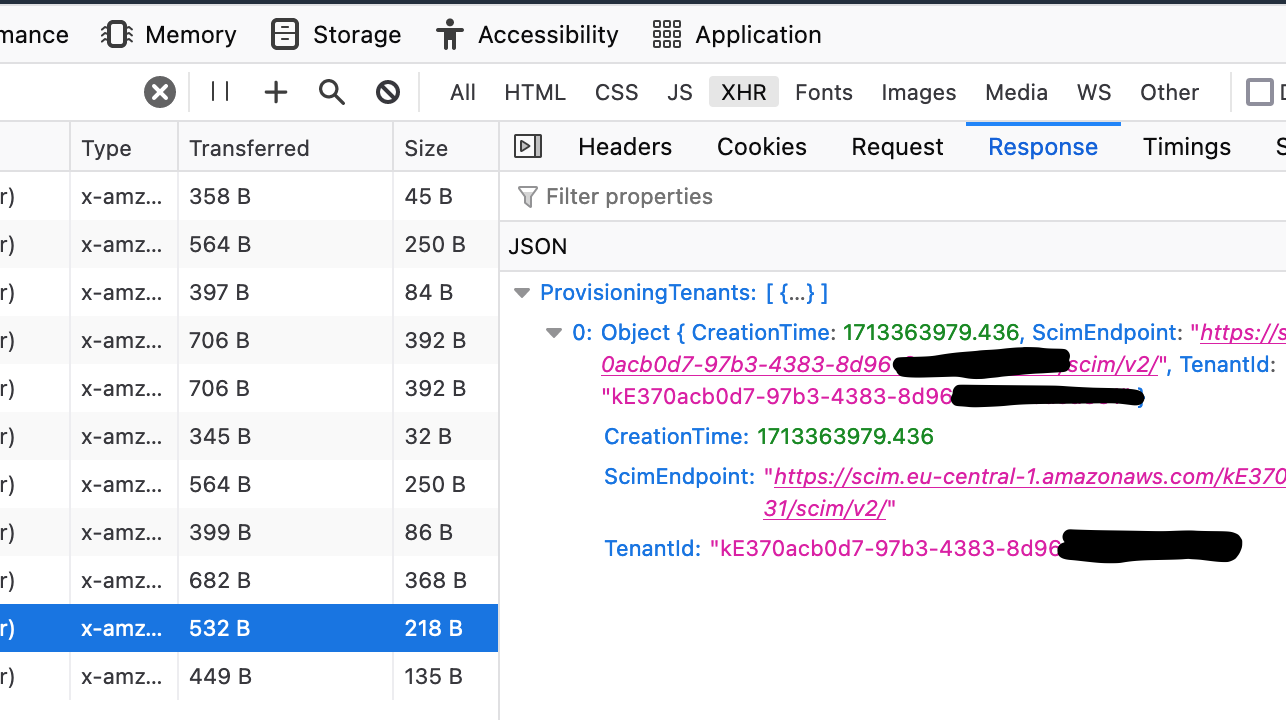
To use this API in a script, we need to collect a bit more information from the Request tab, which shows us how the payload is structured, i.e., the input to the API call. Sometimes, this is empty; in my case, it sensibly needs to know the directory ID to return the provisioning tenants.
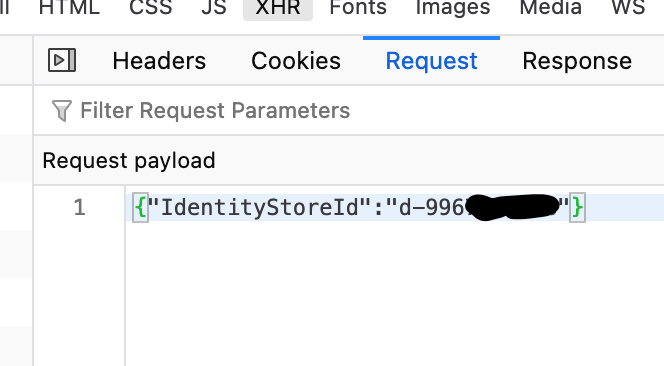
The other important info is the request metadata in the Headers tab. Here, we can see the service endpoint URL and which HTTP method is being used. Additionally, we find the Content-Type that has to be used when we send the payload, often application/x-amz-json-1.1, and how the need to calculate our authorization header value later (region + IAM namespace).
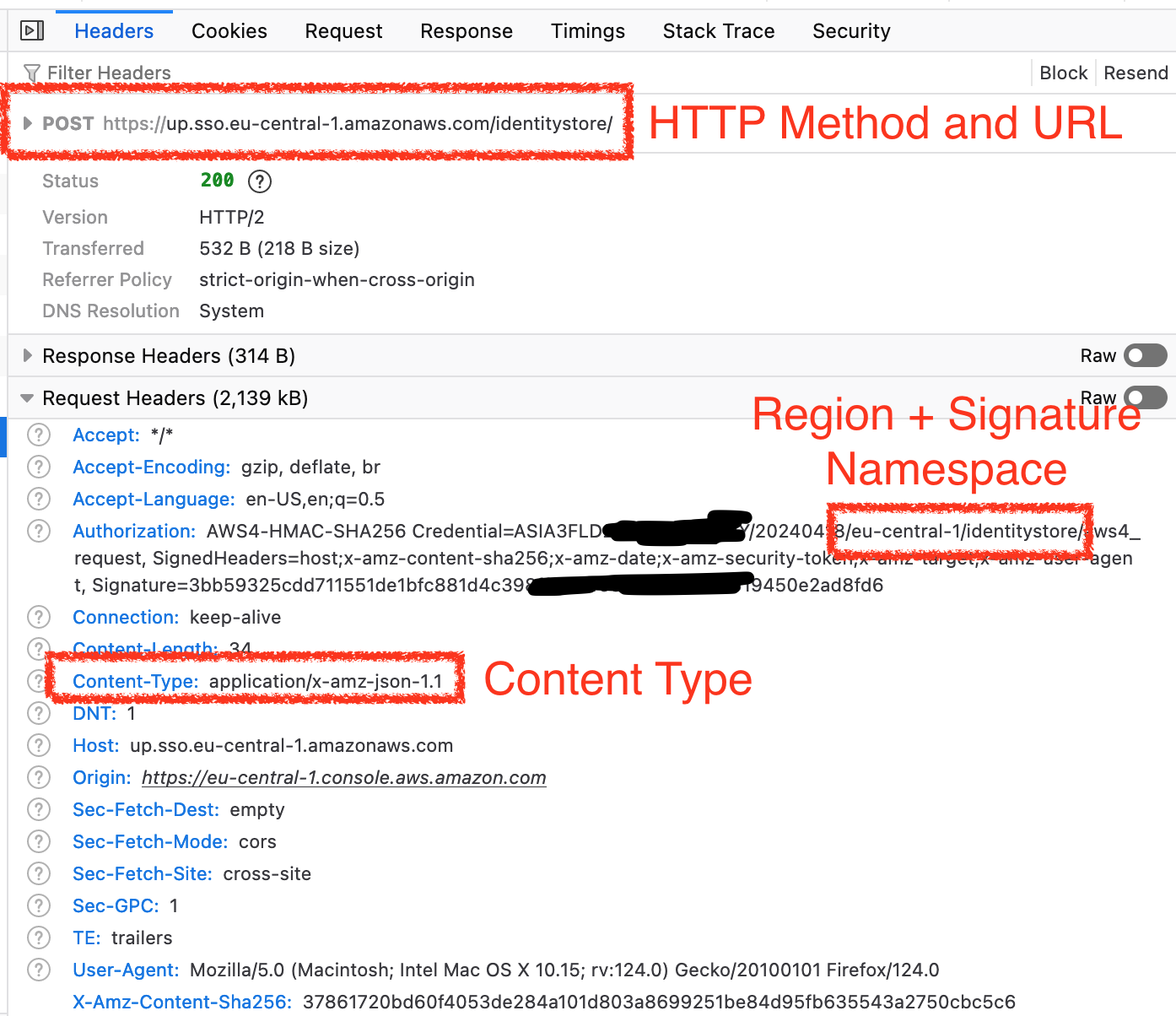
When we scroll down a bit more, we can see the last information that matters, which API method is being called (X-Amz-Target). You may notice that the service namespace doesn’t necessarily match what you’d expect from the IAM namespace - it is what it is.

Having collected all this information, we can start writing our script to fetch the info programmatically. I’m going to use Python for that. First, we’ll install the following libraries:
boto3to read our local credentialsrequestsfor easy HTTP requestsrequests-aws4authto calculate our signatures/authorization header value
pip install boto3 requests requests-aws4auth
Next, we’ll write a script to make the API call. First, we import the necessary dependencies and configure the region our IAM identity center is deployed in as well as its identity store ID, which can be obtained by sso-admin:ListInstances. Afterward, we define which credentials to use for this request. The way it’s written, it will use whatever is currently active in your environment when you run the script, but you can also make it use a specific profile by setting the profile_name parameter in the boto3.Session call.
import json
import boto3
import requests
from requests_aws4auth import AWS4Auth
# Where we plan to get the info from
region = "eu-central-1"
identity_store_id = "d-99677XXXXX"
# Customize this to select the right credentials
boto_session = boto3.Session()
credentials = boto_session.get_credentials()
The next step is to create the authorizer for our API calls. We need to sign our AWS API calls with the Signature v4 algorithm, which can be a bit annoying to compute. That’s why we’re using a library for it. Boto3 would create that signature for us if this were an official API.
# Provide SignatureV4 request signing
auth = AWS4Auth(
region=region,
service="identitystore",
refreshable_credentials=credentials
)
Finally, we can make our API call and print out the response. This requests.post call is fairly basic and you should recognize all the information from the screenshots above. By passing the dictionary with the data to the json parameter, the library will automatically encode it properly. It would usually also set the content type to JSON, but AWS requires a specific one, so we have to overwrite that in the header.
# Make the API call based on the collected information
response = requests.post(
f"https://up.sso.{region}.amazonaws.com/identitystore/",
headers={
"Content-Type": "application/x-amz-json-1.1",
"X-Amz-Target": "AWSIdentityStoreService.ListProvisioningTenants",
},
auth=auth,
json={"IdentityStoreId": identity_store_id},
)
# Output the response
print(json.dumps(response.json(), indent=2))
The output of our script looks something like this.
{
"ProvisioningTenants": [
{
"CreationTime": 1713363979.436,
"ScimEndpoint": "https://scim.eu-central-1.amazonaws.com/kE370acb0d7-97b3-4383-8d96-example/scim/v2/",
"TenantId": "kE370acb0d7-97b3-4383-8d96-example"
}
]
}
Congrats, you’ve used an undocumented AWS API to get information that previously required logging in to the console. You can now go ahead and continue working with that data. Stop! Not now - before you leave, we have to talk about some caveats.
Using undocumented APIs comes with some risks. For official APIs, AWS usually sticks to the mantra an API is a promise and you can rely on them always being available and not changing. Official APIs are very unlikely to break your code down the line. The same can’t be said for these undocumented APIs. They may change or be decommissioned at any point. You get no guarantees, so I highly recommend you don’t build anything mission-critical on top of them.
Relying on undocumented APIs should, at best, be a temporary solution until AWS releases an official API. A decent way to stay up to date on the release of new APIs is awsapichanges.info, which allows you to filter to individual services such as IAM Identity Center.
This method doesn’t necessarily work for all undocumented APIs. Some of them are a bit nasty and require you to have a front-end session. If you’re dealing with one of those beasts, I highly recommend you check out Jacco Kulman’s post about the same topic. I was lucky that “my” API is one of those that seems to be built to make its way to an official API eventually, which can’t be said for all of them.
I hope you enjoyed reading this post and learned something new.
— Maurice
Title Photo by Stefan Steinbauer on Unsplash