SAP HANA High Availability on AWS - How tecRacer helped secure cash register operations for Germany’s leading department store chain
Galeria Karstadt Kaufhof and tecRacer have been collaborating on developing Galeria’s Cloud Platform for many years with tecRacer as their Go-To Partner for everything related to AWS. The work we have been doing ranges from designing, setting up and operating their landing zone and network infrastructure, managing platform security and cost optimizations all the way to deploying complex system architectures such as Kubernetes. Most notably, we have been one of their trusted partners when it comes to their SAP infrastructure on AWS and have supported in many successful SAP system deployments. Furthermore, tecRacer provides managed services for Galeria Karstadt Kaufhof’s SAP environment, aimed at maintaining system stability and efficiency. These services include routine monitoring, volume backup management, and operating system patching, which are essential for the smooth operation and security of their SAP systems. Additionally, tecRacer provides antivirus protection and AWS cost optimization, focusing on safeguarding the system from threats and managing cloud-related expenses.
Today, I’d like to give you some insights into one of our most impactful projects that we did for Galeria. One of their most important SAP systems is responsible for handling all cash register transactions in their department stores. With increasing usage and business demand, that system became more and more critical for their business operations, which had an impact on Recovery Point Objective (RPO) and Recovery Time Objective (RTO), that define how much data can be lost in case of an outage and how long it should take to recover from the failure. With an RPO close to 0 and an RTO of only several minutes, a new High-Availability Strategy was developed that involved implementing a standby host for the most critical component, which is the SAP HANA Database.
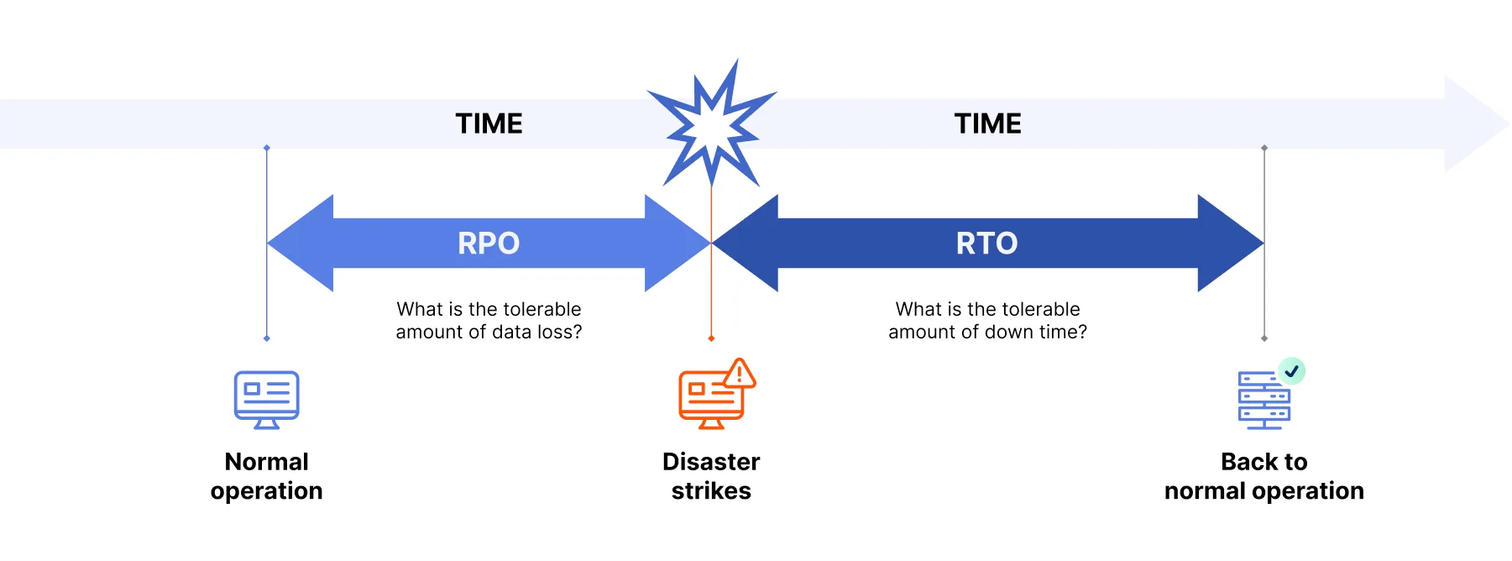
tecRacer was hired to set up the components on AWS and coordinate with another vendor that was supporting in SAP system operation tasks. In this blog post, I will give you a broad overview of the solution - focusing both on the AWS components as well as the SAP HANA and operating system configuration. The project was mainly focused around the SAP HANA Database with the goal to minimizing system downtimes and removing any risk for data loss in case of an instance or availability zone failure.
AWS Infrastructure
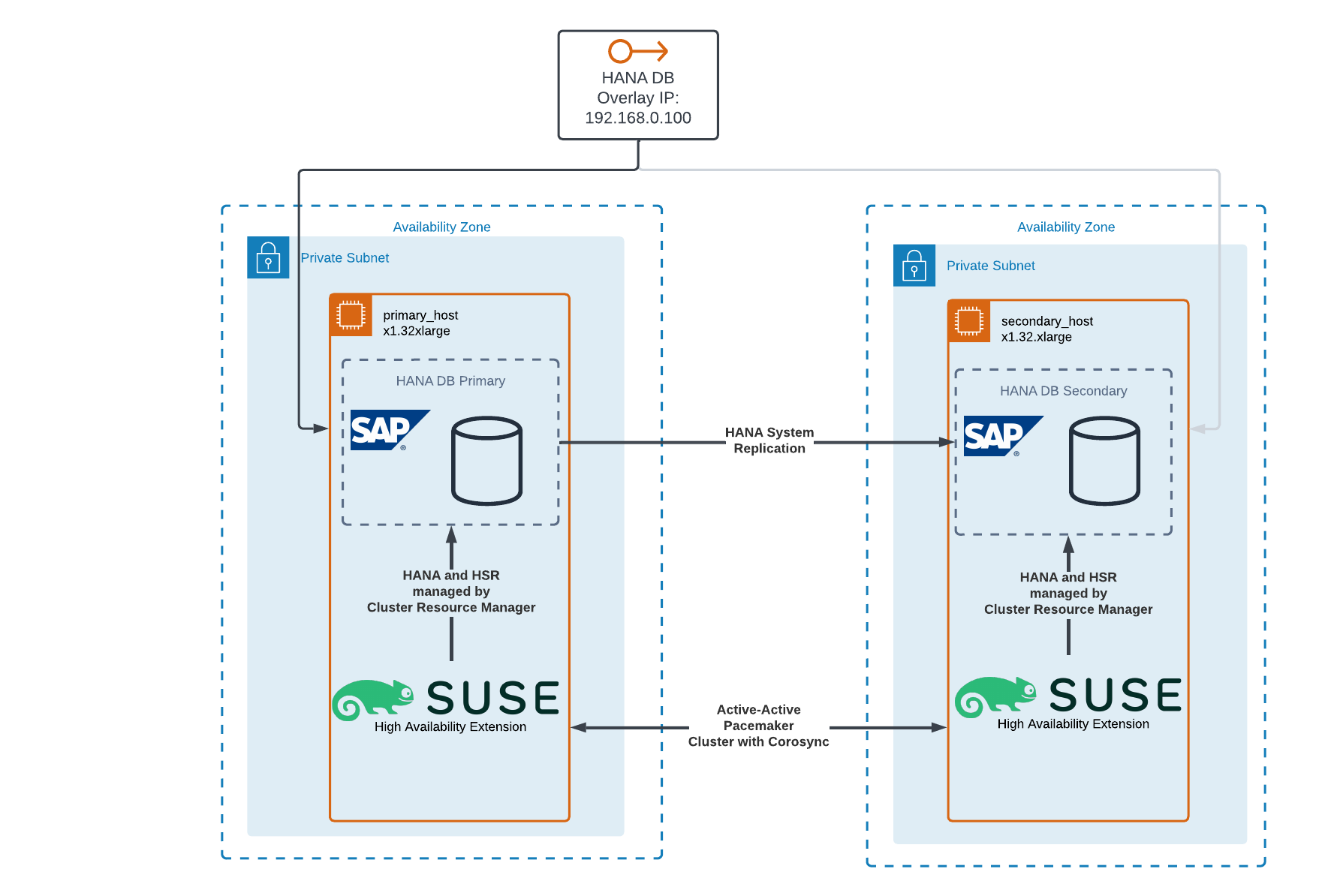
The solution makes use of multiple components that interact with each other. First of, let’s recap some of the basic design components in AWS. The fundamental service for private infrastructure in AWS is VPC which stands for Virtual Private Cloud. Essentially it provides an isolated network segment in the cloud that is dedicated to your organization and can be connected to your organization’s intranet. HANA database systems are deployed on virtual machines (EC2 instances) inside such a VPC.
A VPC can and should span multiple availability zones. Availability Zones are physically separated locations within an AWS Region. Each AZ is designed to be isolated from failures in other AZs, and they are connected with low-latency, high-throughput, and highly redundant networking. This design ensures that even if there is an unforeseen event or infrastructure failure in one AZ, it won’t impact applications running in another AZ. For applications spanning two availability zones, AWS provides an infrastructure availability-SLA on EC2 instances of 99,99 % compared to 99,5 % for individual instances in a single AZ.
HANA System Replication
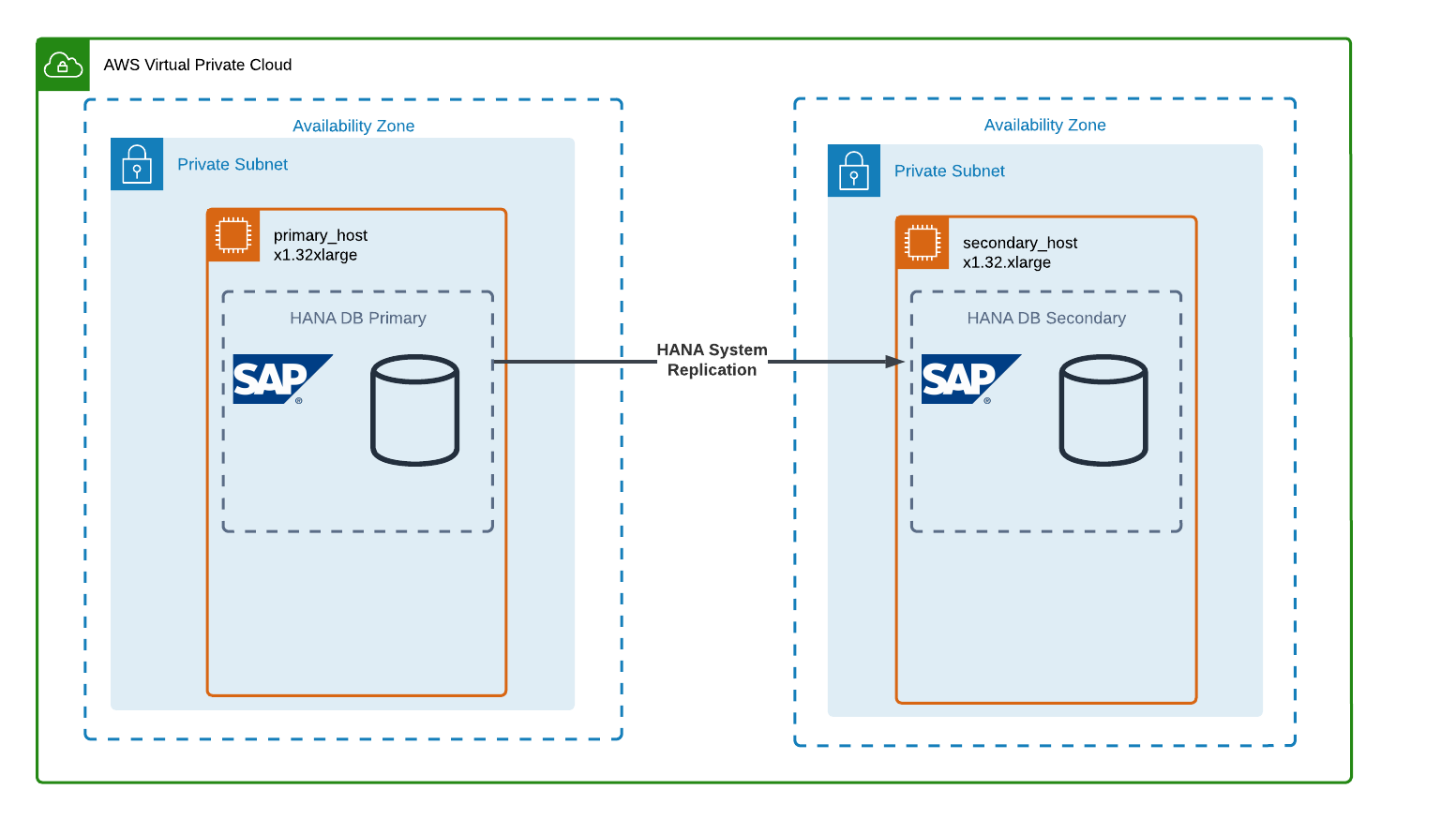
At the core of the solution is SAP’s own data replication method called HANA System Replication (HSR). HSR is used to continuously keep the data inside two SAP HANA database systems identical. There are no further licensing requirements and it works out of the box with all currently supported HANA versions. It is very important to note that data loss can only be avoided when using the replication modes SYNC or SYNCMEM which place very high requirements on the network between the instances. The network between AWS Availability Zones fulfill those requirements, which makes HSR the ideal solution for HANA High Availability with an RPO of 0 and an RTO of only a few minutes, as requested by Galeria.
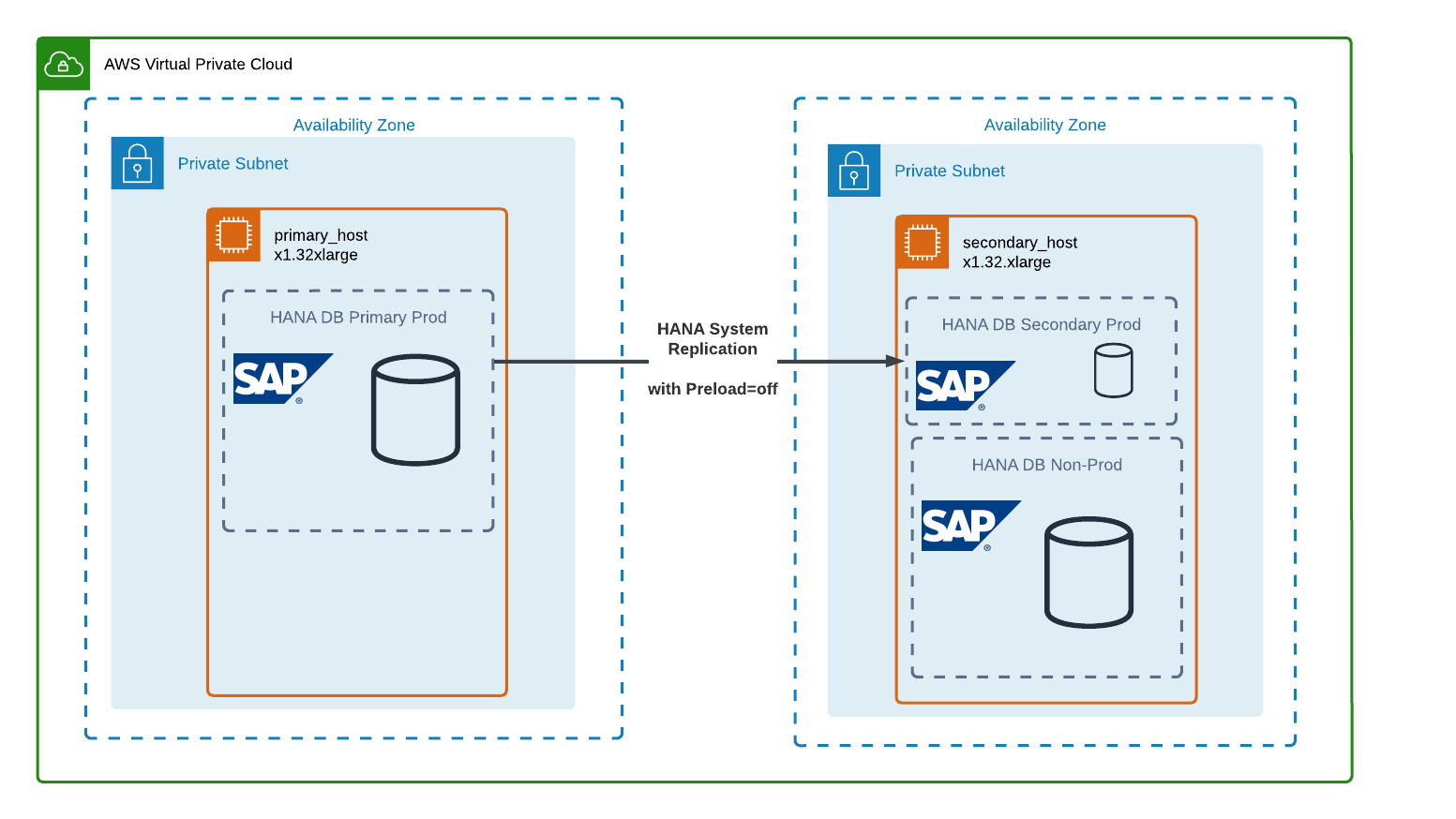
Running two HANA database systems in parallel provides the highest failover performance, but has an obvious downside which is doubled infrastructure cost for the database. HSR addresses this issue with the option to replicate to another HANA system such as the environment’s test system. It then saves the replicated data only to storage and wouldn’t load it into memory. In case of a failover, the test system would be shut down and the replicated data in storage is loaded into memory, which would complete the failover. While this potentially only has a small impact on cost, it has a lot of impact on RTO, depending on the database size. This approach is also called “Warm Standby”.
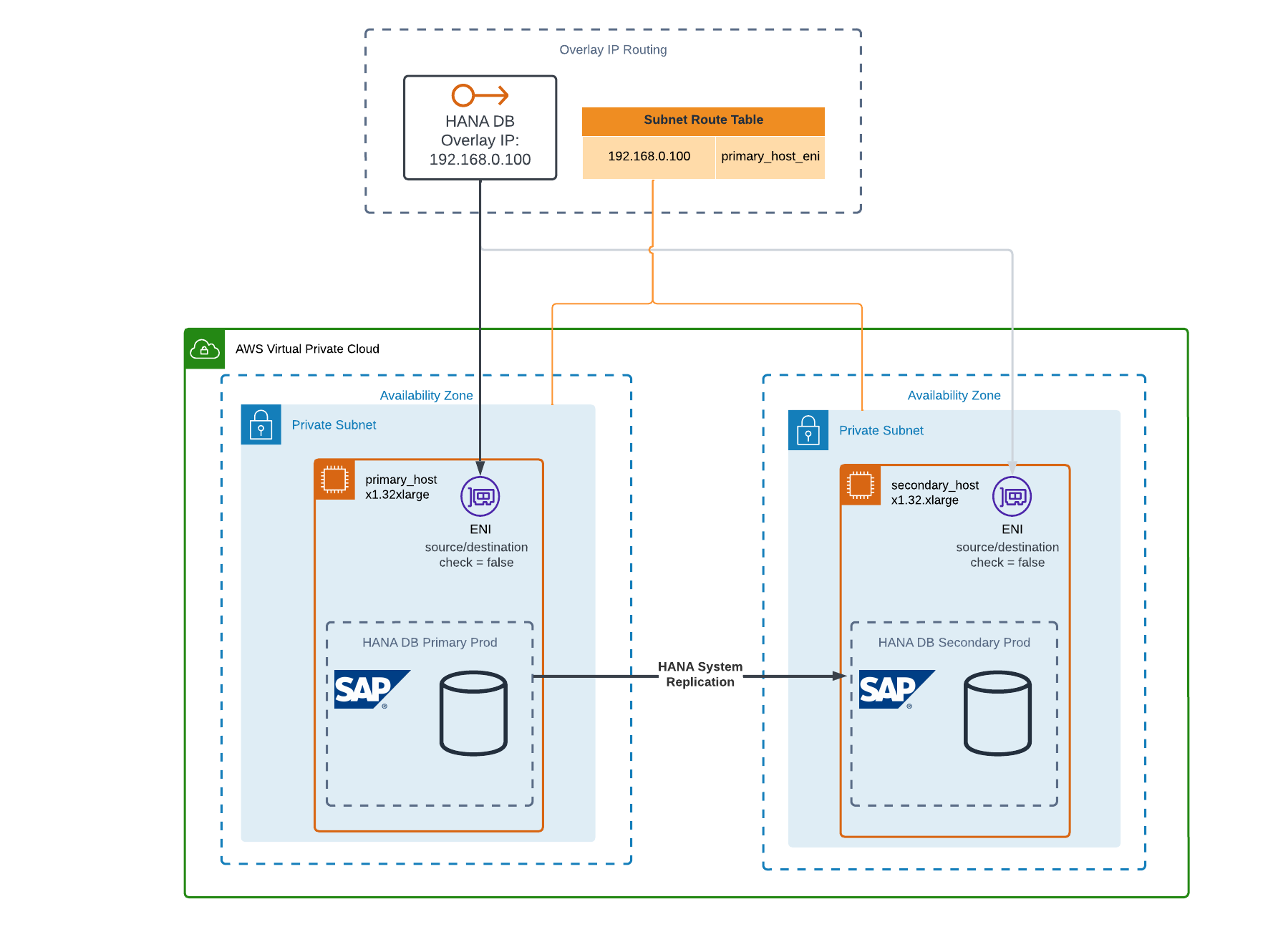
Overlay IP Routing via AWS Route Tables
While HSR takes over the replication of the database, the question remains how to ensure that traffic to the primary database gets rerouted to the secondary database after a failover. In AWS, one option is to configure a so-called overlay IP address, also known as a floating IP address.
With overlay IP address routing, the IP routing target can be defined in the subnet route tables by explicitly specifying an EC2 instance network interface. That way, the target can very quickly be changed to the secondary instance without any impact on clients.
High Availability Extension in SUSE Linux Enterprise Server for SAP Applications
Last step: Bringing it all together in automation!
While both HSR and the Overlay IP Routing could be managed manually, Galeria was seeking for a fully automated solution that monitors host and database health and autonomously performs the failover with as little impact on the users as possible. The High Availability Extension that is part of SUSE Linux Enterprise Server for SAP Applications provides those features, which is why the respective servers where migrated to that OS as part of the project.
The underlying technology that is used by both SLES4SAP and RHEL4SAP (Red Hat Enterprise Linux) is a framework called Pacemaker in conjunction with Corosync as the cluster engine. Corosync is responsible for establishing communication between the cluster nodes and ensuring that they are all in sync. It provides the base layer of the High Availability cluster, managing cluster membership and delivering messages between the nodes. This ensures that each node is aware of the status of the others and can react accordingly in case of failures. It also provides quorum functionality to avoid Split Brain conditions.
However, most magic is happening inside Pacemaker which sits on top of Corosync and adds resource management functionalities. It controls the services or applications that are running on the cluster, decides where they should run, and supervises them to ensure they are operating as intended. When there’s a need to perform a failover, it is Pacemaker that decides how and when to move resources from one node to another. Pacemaker works with so-called Resource Agents which are dedicated to their specific use case. For instance, SUSE built ocf:suse:SAPHana and ocf:suse:SAPHanaTopology to allow Pacemaker to manage the state of HANA Database systems and HANA System Replication. It can automatically promote the secondary to primary and vice versa based on the current cluster health. Furthermore, SUSE partnered with AWS to build ocf:suse:aws-vpc-move-ip which builds on AWS APIs to automatically move the Overlay IP to the currently active cluster node. Lastly, it provides the AWS-native STONITH method stonith:external/ec2 to shut down nodes when necessary to keep the cluster resources healthy.
Summary
Together AWS, SAP and SUSE provide a complete and proven solution for SAP System High Availability. It does have some downsides such as its cost and the general complexity of the setup. Still, for companies that depend on those systems for their business and that are trying to keep operations running in any situation, this investment proves to be worth it. Customers that are shopping at one of Galeria’s many department stores can be sure that their transactions will be processed smoothly and without interruption. In conclusion, while setting up a high-availability solution may come with its challenges, the peace of mind it provides to businesses and their customers is invaluable.