Using AI to generate Terraform Code from actual AWS resources
The world is changing, with new AI tools emerging every day. One such tool that has been making waves recently is ChatGPT. It is only the first of many such tools hitting the market, and it urges us to think about the future of our work. I recently used it to help with a standard task that I often perform and was amazed by how well it helped me to automate it.
There has been countless talk about AI, ChatGPT, and LLMs in general since OpenAI released the first public version of their tool. I have never been a friend of pushing any hype, but this one really hasn’t left my attention. I have been following the developments in AI for quite some time and actually wrote my master thesis about practical applications that AI could have “in the future” and how that would impact the world we live and work in. This was in 2019, and I couldn’t have imagined how fast the future became reality.
This blog post is about my most efficient use of an AI tool to date. It does already change my day to day job as an AWS consultant and should get all of us thinking about our role in the future.
The Task: Migrating AWS VPCs, Subnets, and Routes into Terraform Code
The task at hand was straightforward and mundane. I know from experience that GPT-4 was surely capable of it. Still, I was surprised by how well it followed my proposal of how to approach the task step by step.
The task was as follows: Some AWS resources were created manually in the past, and we now want to continue managing those in Terraform via Infrastructure as Code. Specifically, it was about VPCs, their subnets, and related route tables. So far, not a big deal, but I knew it would require tedious yet very simple work to accomplish it. First, I would need to extract the current configuration details via the AWS console or CLI; then write the corresponding Terraform code and, in the end, execute terraform import for each resource. If done correctly, a terraform planwould state that the state matches the configuration.

Breaking Down the Task: Utilizing ChatGPT for Step-by-Step Execution
I knew I could speed it up with ChatGPT and figured that I needed to break it down into simple steps. I learned in prior experiments that trying to accomplish complex tasks in one step would often lead to errors and frustration.
Here’s my approach: I first asked it to provide me a list of steps that need to be done. Then I should go through the steps one by one and use the results of previous steps as input for the next step. I hoped to only have to double-check and then copy/paste the respective text, and it worked. I knew that ChatGPT is designed to consider the chat thread as context during text generation, but seeing its application amazed me as it really followed through with my instructions.
Here’s the full first prompt:
I want to migrate an existing AWS VPC, subnets, and route into Terraform code. Please provide the steps for this in an ordered list.
skip the tf basics. i am a pro.
provide the aws cli commands to gather the intel and then provide the tf code + tf commands for import.
However, please start with the ordered list of the steps. Later we will go through each step and I will provide the output of each. Based on that output you can then provide the input for the next step
please keep it short
What followed was a correct list of all the steps I would have done manually:

From AWS CLI Commands to Terraform Code: ChatGPT Generates the Solution
After double checking it, I started the process:
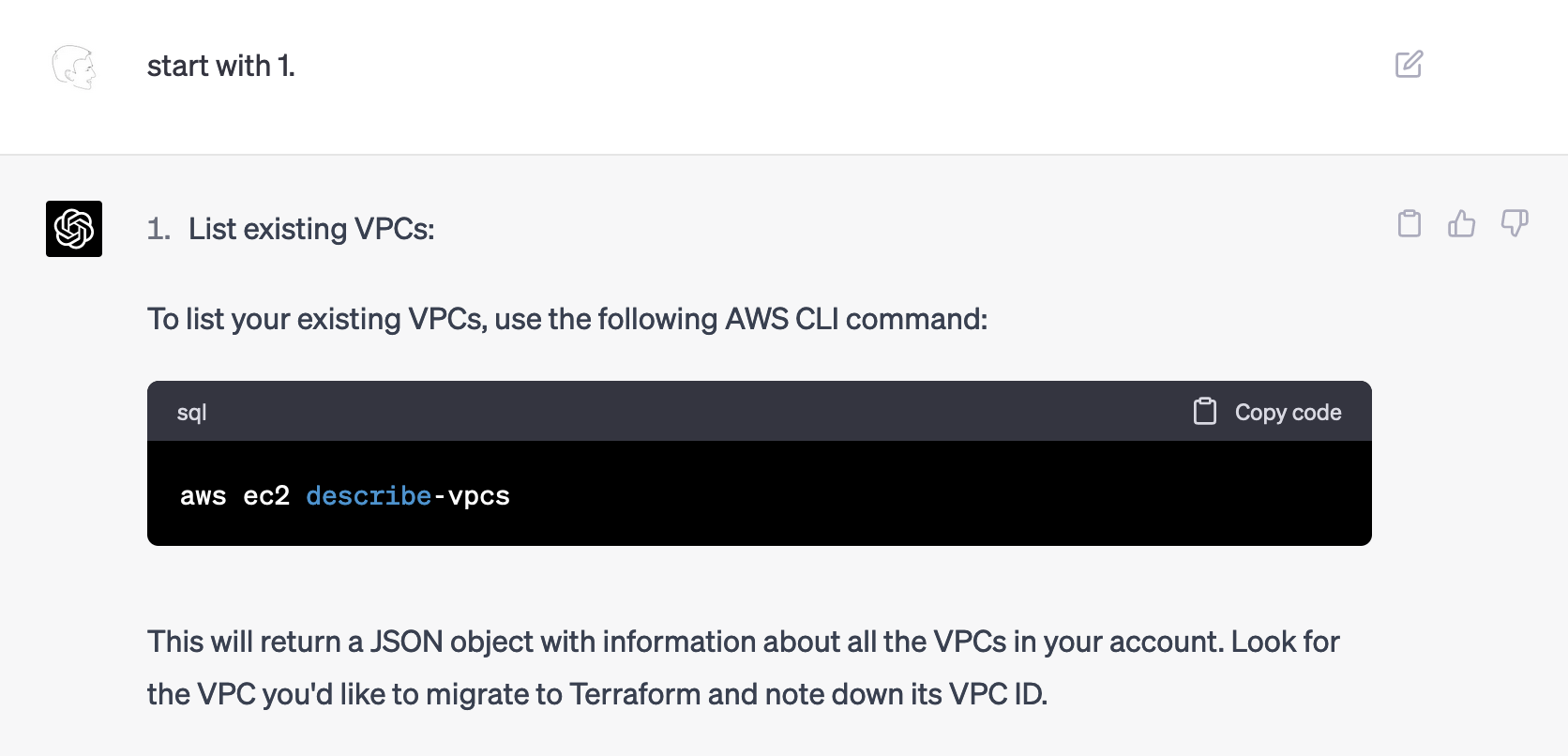
The command was correct, and it provided a JSON document that I then posted without comment as the next prompt. ChatGPT knew that it had to proceed with the second step and immediately jumped into it. I found that combination of results impressive.
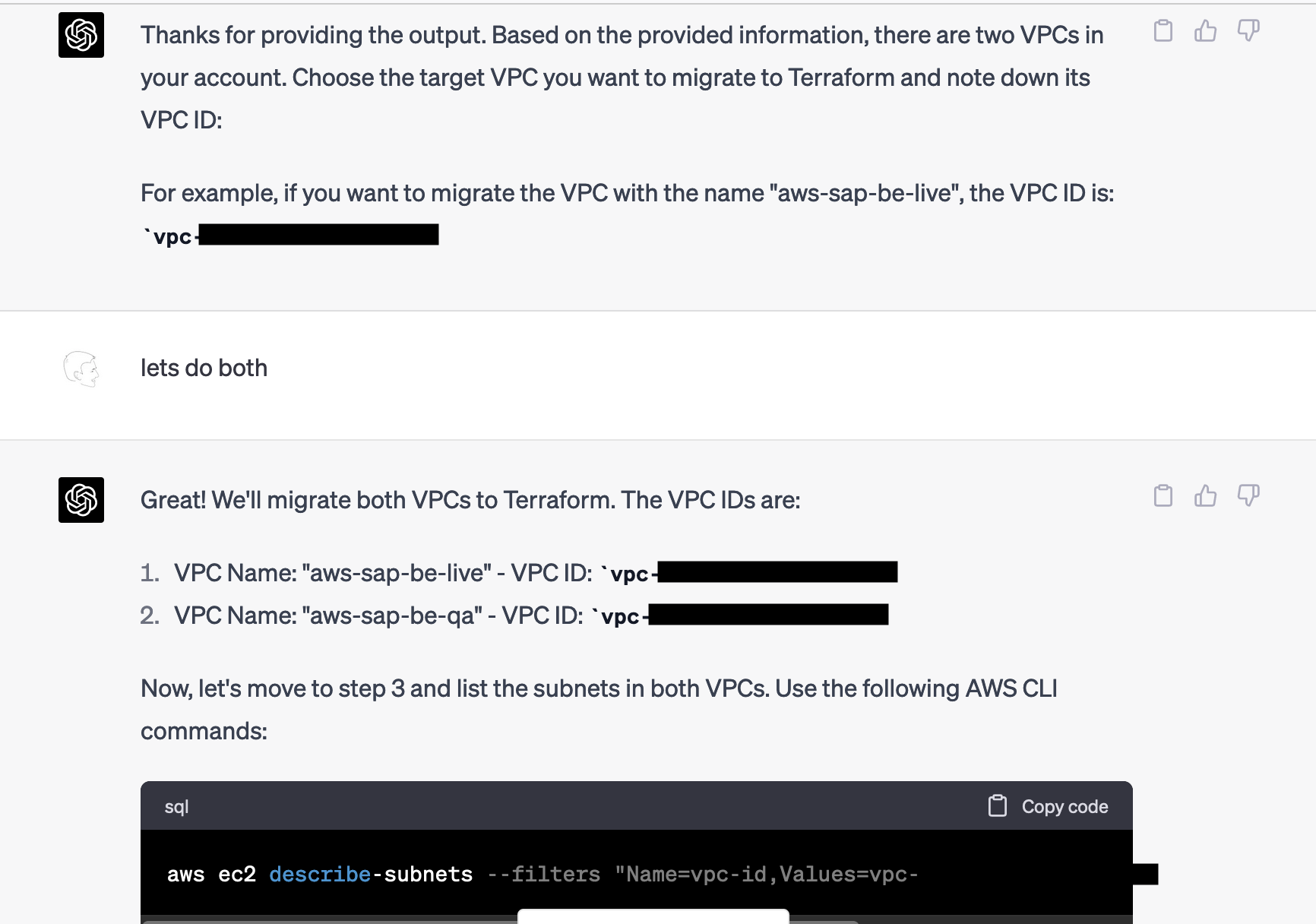
Again I posted the results without comment and lastly got asked about the route tables.
Next, without further ado (remember, I didn’t tell it to do the next steps. It simply “remembered”), it gave me some perfectly fine Terraform Code that included all required information and sensible naming.
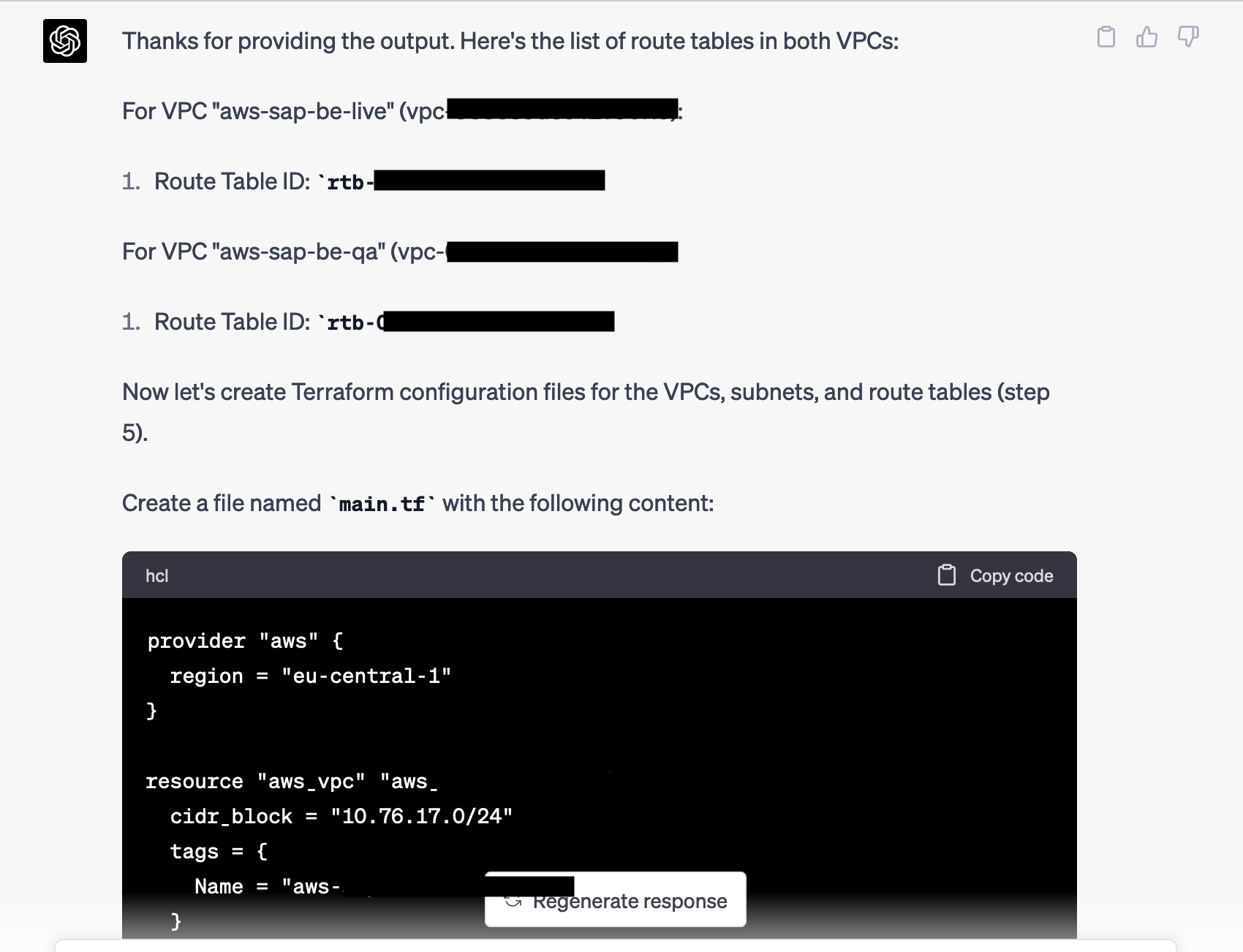
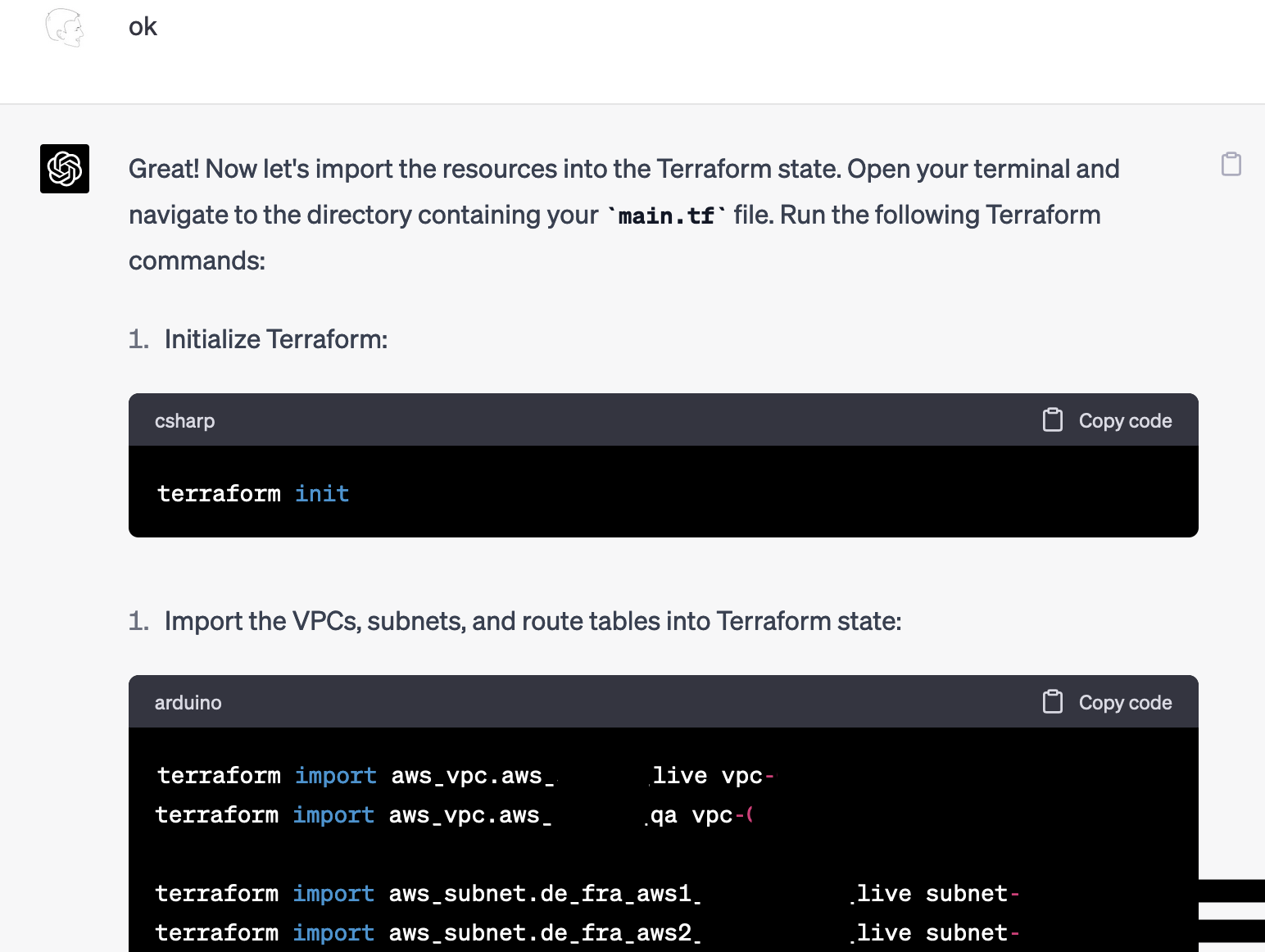
After I checked it, I saved it into a new Terraform project, and finally, the last steps, which are to perform the actual Terraform Import, simply brings existing resources into TF management:
The Results: Terraform Plan, Import, and Success
Onto the moment of truth. As ChatGPT states, terraform plan should now say that the Infrastructure is “up to date”, indicating success.
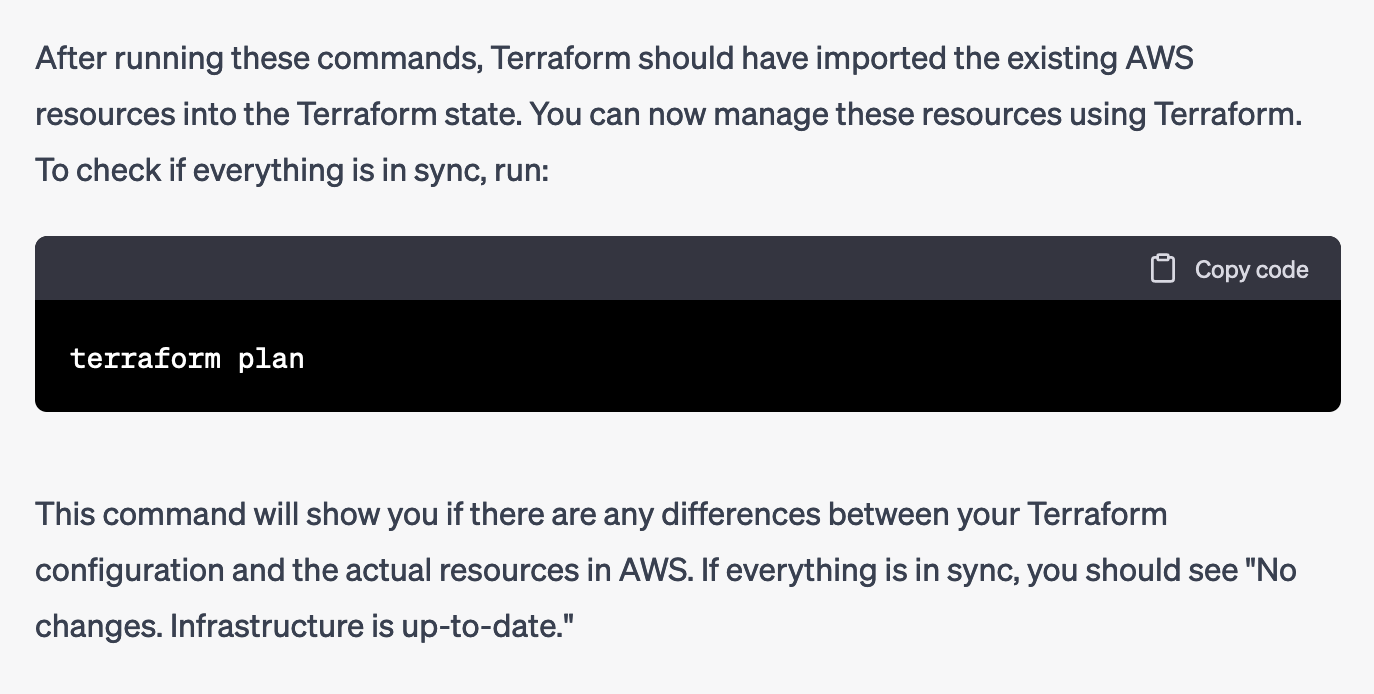
And really, it indeed worked without any errors:

Reflection
Let’s recap my own role in this process. Clearly, ChatGPT controlled the entire process. I was merely the agent and executing the steps.
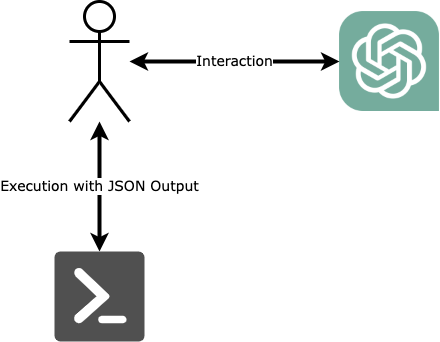
This precision and effectiveness of that approach still amaze me and has again been eye-opening. This does change the way we will approach such clerical tasks in the future, and it got me thinking about my own role as an IT professional. For sure, future tools will be able to execute the steps autonomously without a human in the loop. This opens up a lot of questions about AI safety as it will become more and more difficult to control the actions of the AI.
All this may still seem like “child’s play,” and surely, I’m happy that it doesn’t yet make me expendable. But we should think of GPT-4 as a very early version. Basically, it is still a toddler. Now, imagine what it will do to our jobs once it further evolves, which will happen sooner than we now think. Further iterations of this are just around the corner, and they will change many of our day-to-day tasks, and we better prepare for it.