Streamline Security Group Maintenance in Terraform with Markdown Tables
Managing security groups and their rules in AWS infrastructure can become cumbersome and error-prone as your environment grows. In this blog post, I introduce a Terraform solution that simplifies this process by using a Markdown table to define security group rules.
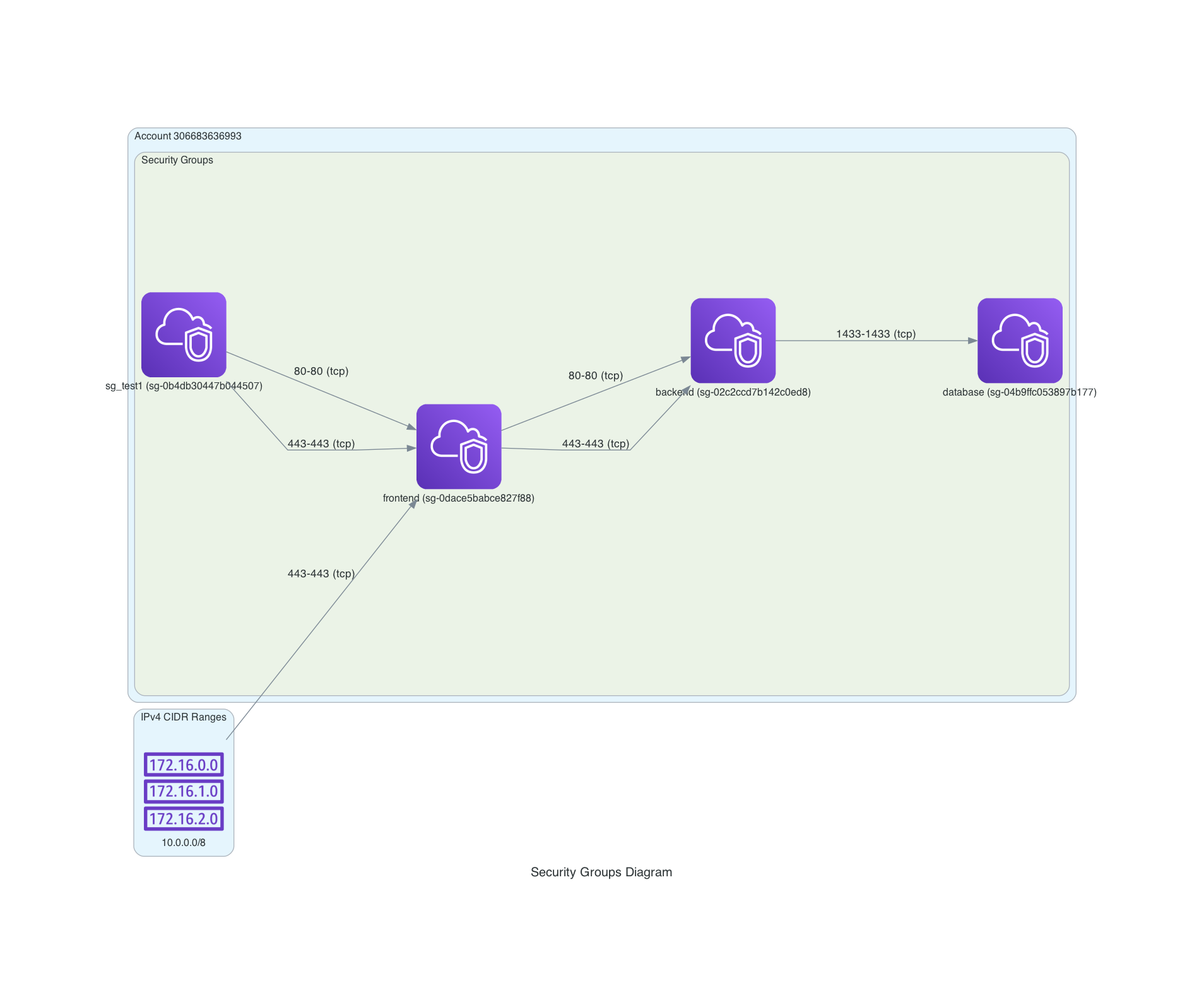
In a previous blog post, I presented a Python tool that automates the creation of AWS architecture diagrams using the Terraform State File. These tools can work together, allowing you to generate both the code and a diagram using a communication matrix defined in Markdown.
Security groups in AWS are crucial for managing access to resources within a VPC. As the number of security groups and their associated rules increase, maintaining them can be challenging. Manual updates can lead to human errors, resulting in misconfigurations, security vulnerabilities, or broken services. Moreover, I personally like working with communication matrices during the design phase, and this tool can efficiently translate that design into code.
The Solution
You can find the code here. Although the code is surprisingly concise, parsing the file is quite complex. It is essential to pay close attention to maintaining the file correctly, as errors can easily occur. Terraform provides limited options for validating the content of the file.
Example
Consider the following example of a Markdown table that defines security group rules:
| Security Groups / inbound from => | frontend | backend | database | ssm(/security_groups/external_server) | cidr(10.0.0.0/8) |
|-----------------------------------|-----------------------------------------------------------------------------------------------|--------------------------------------------------------|----------|---------------------------------------------------------------------------------------------------------|------------------------------------------|
| frontend | | | | [{"port": 80, "description": "external server"}, {"port": 443, "description": "external server https"}] | [{"port": 443, "description": "public"}] |
| backend | [{"port": 80, "description": "from frontend"}, {"port": 443, "description": "from frontend"}] | | | | |
| database | | [{"port": 1433, "description": "database connection"}] | | | |
Each row represents a new security group, while the columns denote source security groups or CIDR ranges. The rules are defined within the cell intersecting the respective sources and targets. To allow for greater flexibility, the rules are defined as JSON lists.
Notice how security group IDs can be read from the SSM Parameter Store, which is useful when chaining together security groups not defined in the same Terraform project.
Terraform Module Call
To use this specific solution as a Terraform module, follow these simple steps:
- Add the following code snippet to your Terraform configuration file:
module "security_group_matrix" {
source = "/path/to/module"
vpc_id = "vpc-xxxxxxxx"
markdown_file_path = "./path/to/your/markdown_file.md"
}
-
Replace the vpc_id value with your VPC ID and markdown_file_path with the path to your Markdown file containing the communication matrix.
-
Run
terraform initto initialize the module, followed byterraform applyto create the security groups and rules based on the Markdown table. -
To visualize the result, run the tool mentioned here. Remember to run
terraform refreshbeforehand to ensure all needed data is in the state file.
Conclusion
I hope you like it, and it proves useful to you! I am looking forward to hearing about it.