What are the folders in the S3 console?
When you start out learning about S3, the experts and documentation will tell you that you should think of S3 as a flat key-value store that doesn’t have any hierarchical structure. Then you go ahead and create your first S3 bucket in the console, and what the interface shows you is a nice big “Create Folder” button.
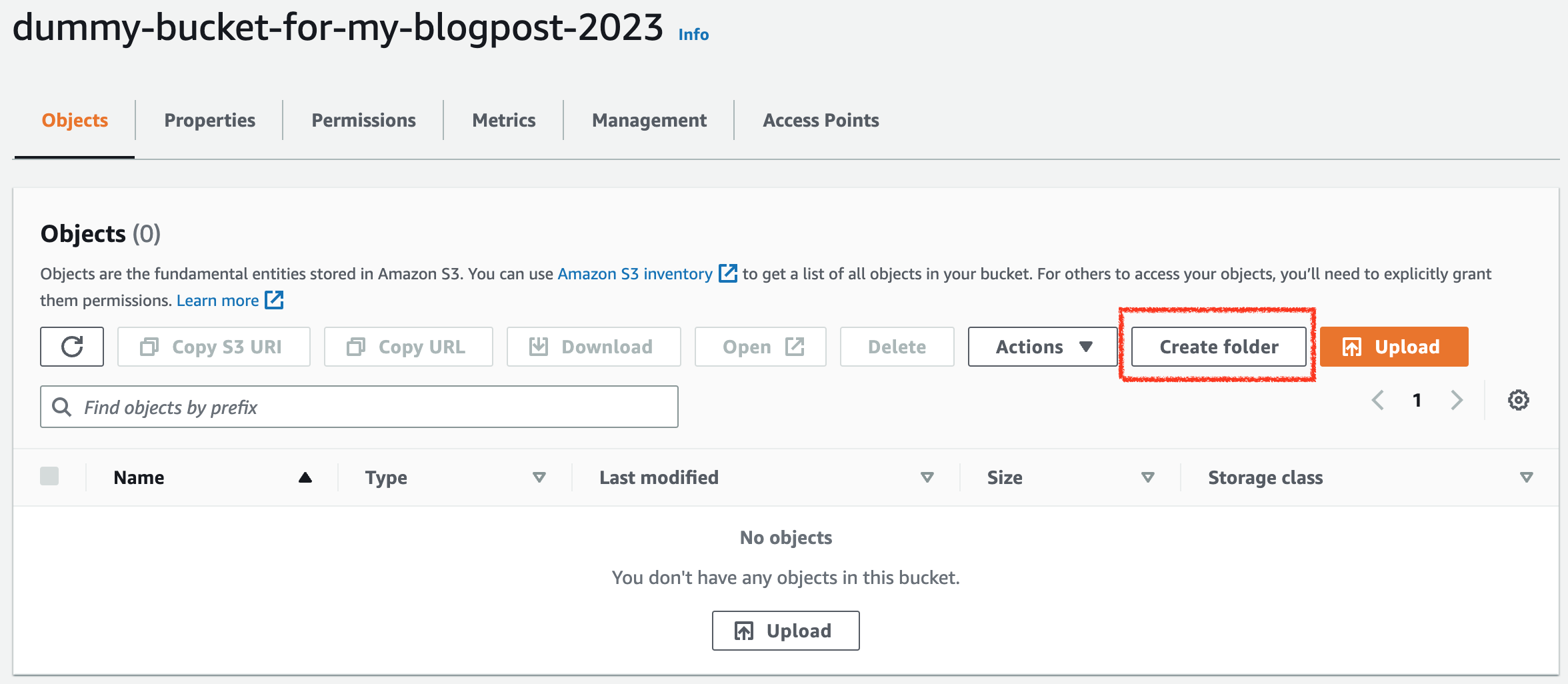
You may be justifiably confused - didn’t I just learn that there are no folders, directories, or hierarchy in S3? The Upload dialog will even allow you to upload folders. If you upload a folder, the console will display that as a directory structure.
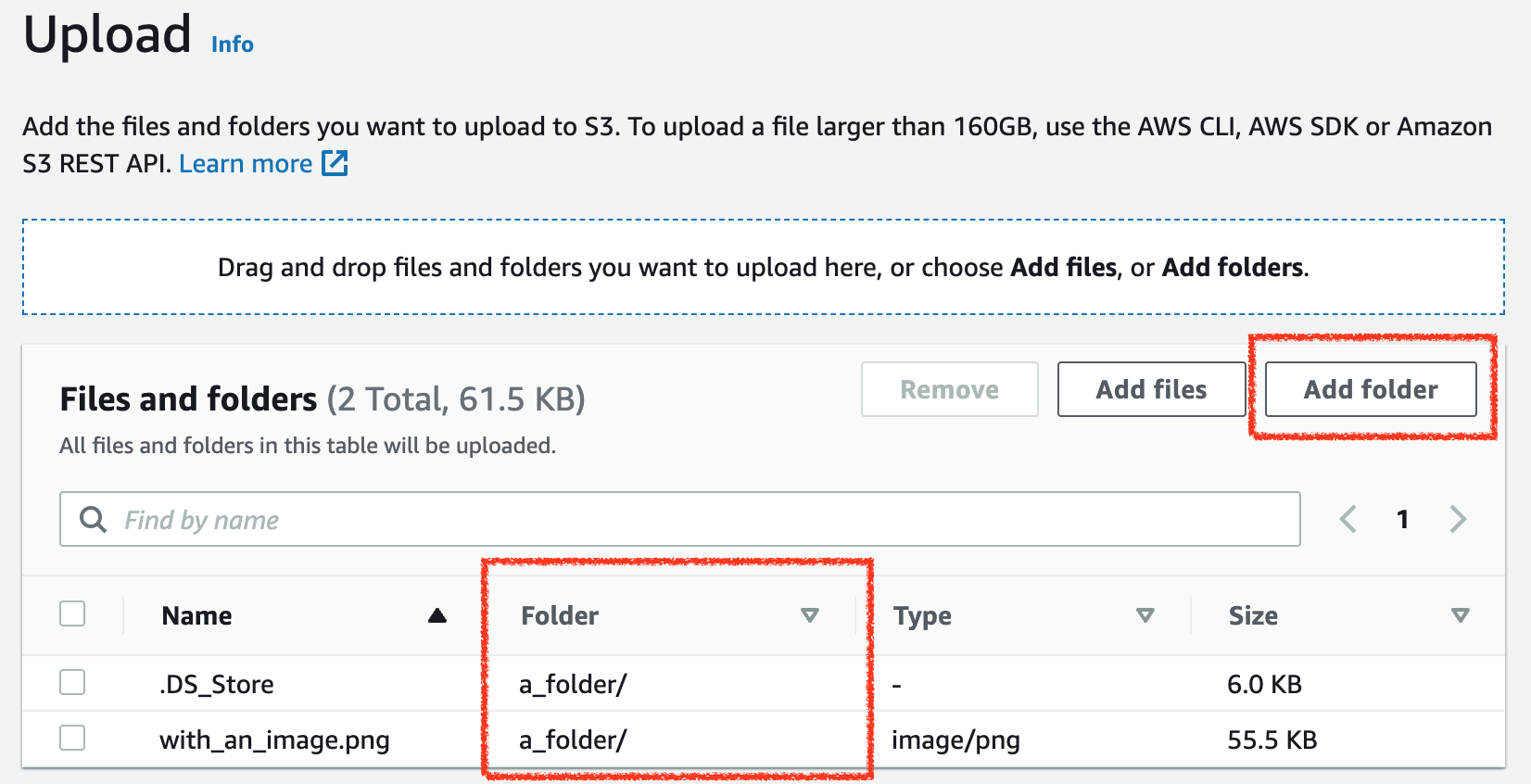
So… have you been lied to? Are there actually folders in S3? The answer is: it depends. If we’re talking about the S3 API that we use to programmatically interface with the service, the only terminology you will see are buckets, objects, and sometimes prefixes. On the API level, there’s no such thing as a folder.
The S3 console is another matter. It’s an abstraction of the underlying API. It tries to simplify the service by making it behave like something that users are already familiar with: filesystems and hierarchical directory structures. The console will render keys that contain slashes as directories that you can navigate. This can be pretty convenient if you’re looking for something in the console because navigating a flat structure with lots of objects isn’t that fun.
So what happens when you create a new empty folder in the console?
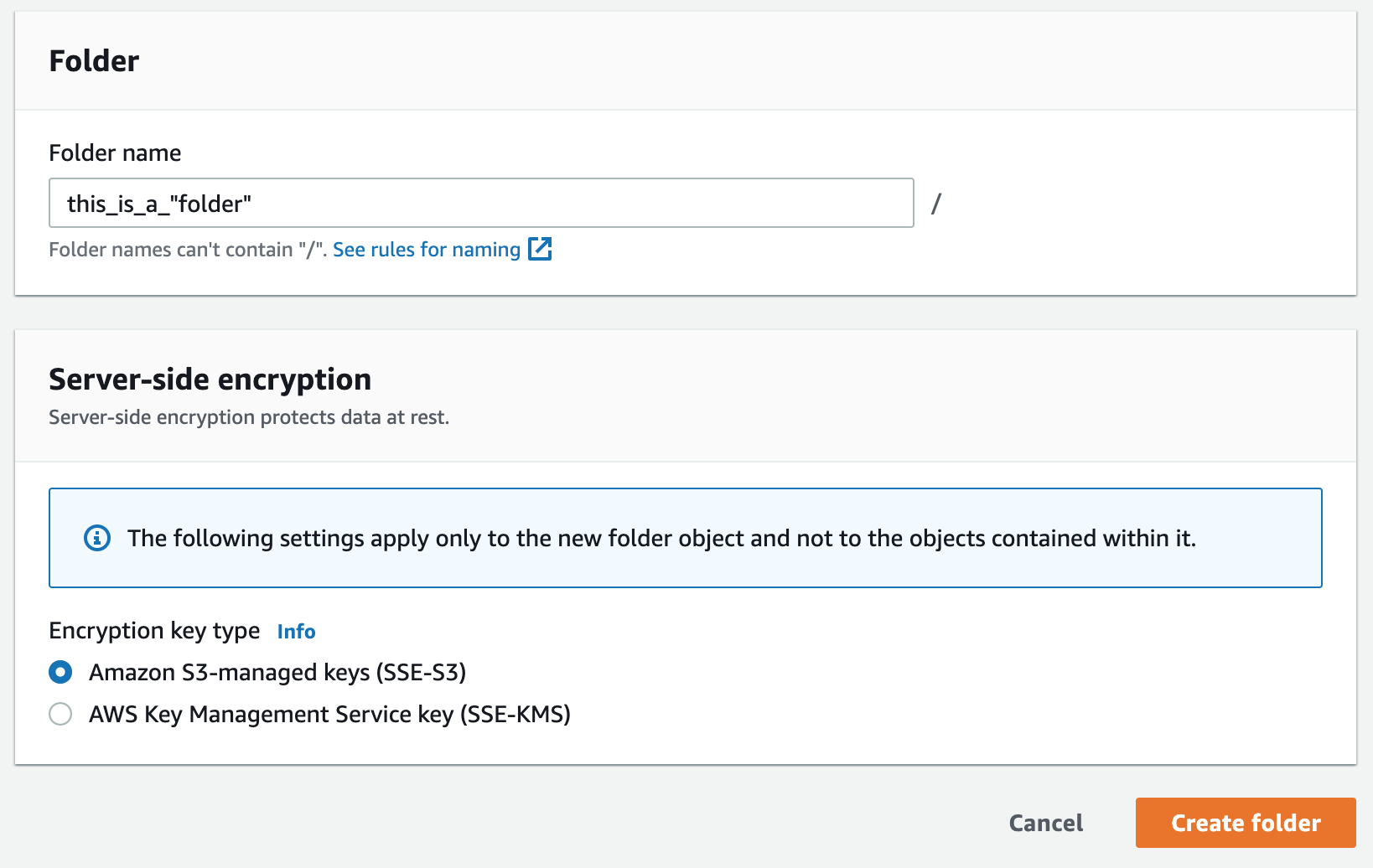
Well, the S3 console can only do what the API allows it to do, so it creates an Object to represent that folder. It has the special rule that it must end with a / and can’t contain slashes. This rule is enforced by the console. We can find out what kind of object it created using the HeadObject API through the AWS CLI:
$ aws s3api head-object --bucket dummy-bucket-for-my-blogpost-2023 --key 'this_is_a_"folder"/' --no-cli-pager
{
"AcceptRanges": "bytes",
"LastModified": "2023-01-13T10:46:24+00:00",
"ContentLength": 0,
"ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
"ContentType": "application/x-directory; charset=UTF-8",
"ServerSideEncryption": "AES256",
"Metadata": {}
}
As you can see, it’s a 0-byte object with the special content type application/x-directory that the console uses to identify this object’s purpose.
Naturally, this leads to the question: can we break it? Let’s try to create an object with the application/x-directory content type that doesn’t end with a slash:
$ aws s3api put-object --bucket dummy-bucket-for-my-blogpost-2023 --key fake-bucket --content-type 'application/x-directory; charset=UTF-8' --no-cli-pager
{
"ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
"ServerSideEncryption": "AES256"
}
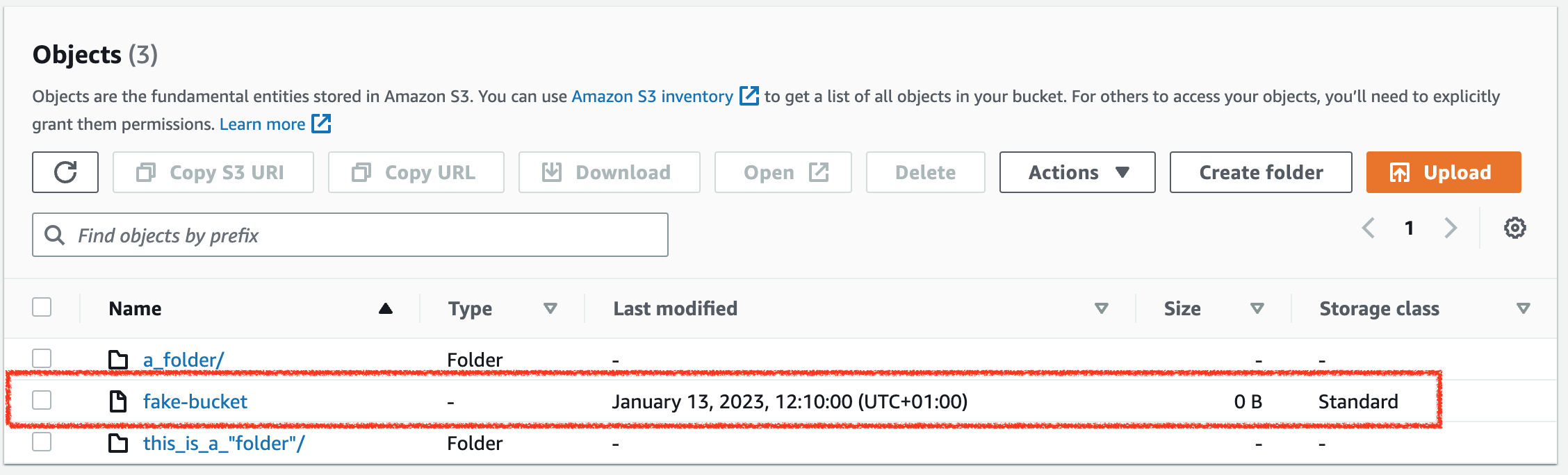
It turns out that setting the content type is not enough for the console to be confused - it sees an ordinary object(Yes, it should have been fake-folder, but I was too lazy to fix it).
 I can already hear your next question: What happens if we upload an object with a slash at the end and the
I can already hear your next question: What happens if we upload an object with a slash at the end and the application/x-directory content type? I’m glad you asked.
$ echo "Hello World" > hello_world.txt
$ aws s3api put-object --bucket dummy-bucket-for-my-blogpost-2023 --key 'fake-folder/' --content-type 'application/x-directory; charset=UTF-8' --body hello_world.txt --no-cli-pager
{
"ETag": "\"e59ff97941044f85df5297e1c302d260\"",
"ServerSideEncryption": "AES256"
}
The upload worked, and in the console, we can now see a fake-folder/ that acts like a “regular” console folder. The console doesn’t even allow me to download the object directly.
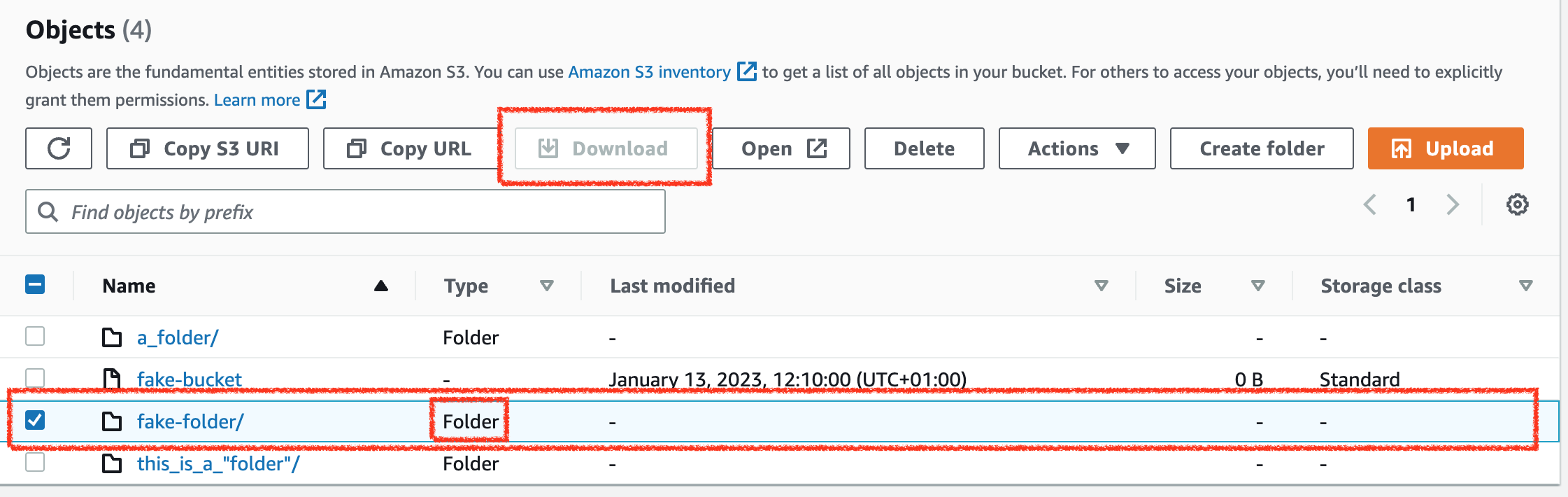
It doesn’t even display the object size, although Head-Object tells us it should be 12 bytes. Only if we navigate into the folder can we see a /-object with a size of 12 bytes which we could then download. If we say a file in a regular filesystem that had the name /, eyebrows would be raised.
This is what’s commonly referred to as a leaky abstraction. The S3 console tries to visualize something as a directory structure that isn’t one. Is this a problem? I’d argue that it isn’t that big of a deal because, in most cases, it’s a useful abstraction that makes your life easier, and that’s what counts.
(I also tested uploading an object with a slash-suffix without the content type, the behavior was identical to the one with the content type.)
What do we learn from this? S3 is a flat key-value store even though the console makes some effort to abstract that reality away from us. The documentation also explains how this is achieved.
Hopefully, you’ve learned something from this explanation.
— Maurice