On-Prem Airflow to MWAA
Introduction
Transforming large amounts of data into formats that help solve business problems is what data engineers excel at. A combination of Serverless tools such as Athena, StepFunctions, Lambda, or Glue can get the job done in many projects. However, some customers prefer to rely on Open-Source projects and tools to access more talent in the job market and be less reliant on a single cloud provider. Today, we’ll share a story of a modernization project that we did for a customer in the online marketing industry.
The customer was looking to modernize the existing data analytics pipeline because they had some pain points they wanted to resolve. The primary purpose of the solution is to process event data and enable timely reporting. They had an EMR cluster that was provisioned through a script and then manually customized, which resulted in stability and reproducibility issues. Not all best practices regarding access control and isolation of production environments were followed because the system had grown organically over the years without clear ownership of the whole architecture.
Moreover, a license for an Oracle database in their On-Prem environment was expiring, and they didn’t want to renew it. Modernizing the ETL jobs that rely on that database was within this project’s scope. They were using an On-Prem installation of Apache Airflow to orchestrate these jobs. They considered replacing that with a managed service because having a strong dependency on an On-Prem resource was risky.
Let’s look at the architecture we came up with to address the customer’s needs. We began by setting up a Landing Zone with a multi-account structure and centralized access management based on AWS SSO. We created three different environments: SANDBOX, TEST, and PRODUCTION. Each environment has its own VPC, a requirement for using Managed Workflows for Apache Airflow (MWAA) as it doesn’t support deployments in a shared subnet setup. SSO was used to create different permissions for different roles and environments. That enables much simpler and more granular control about who is allowed to access which resources than the previous setup.
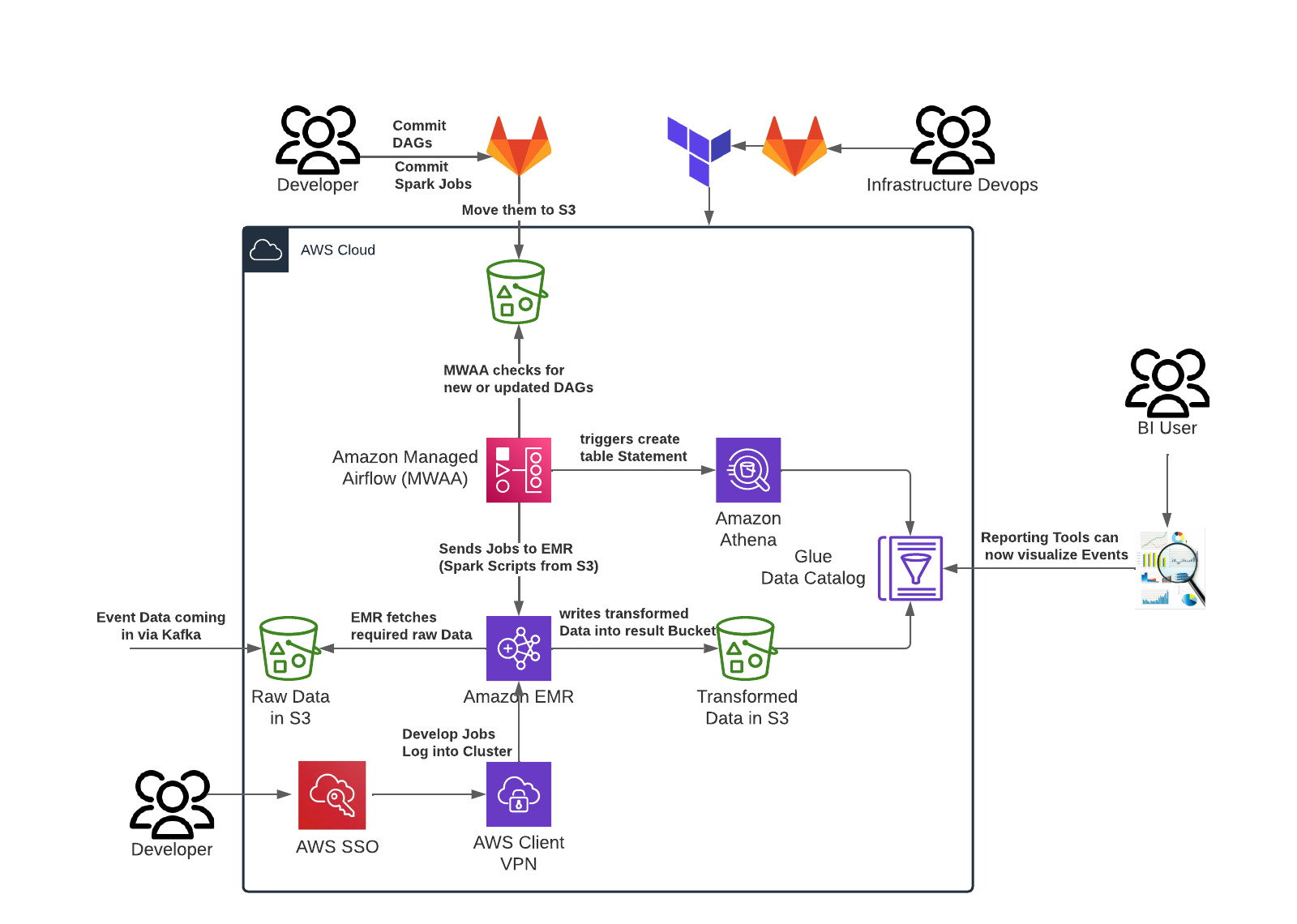
Above, you can see the infrastructure in one of the project accounts. The only differences between production and the other stages are instance count and sizing. As mentioned earlier, this architecture enables event processing and timely reporting. Event data arrives in the S3 bucket on the bottom left side from Kafka. MWAA is used to orchestrate Jobs that leverage EMR and Athena to process and transform data and store it in a different bucket. Developers can log in to the EMR via ClientVPN to debug jobs. Their access to the system is controlled via SSO. This readily available option makes developing Spark Jobs much more efficient because you don’t have to wait for the complete CICD pipeline to finish uploading your changes every time.
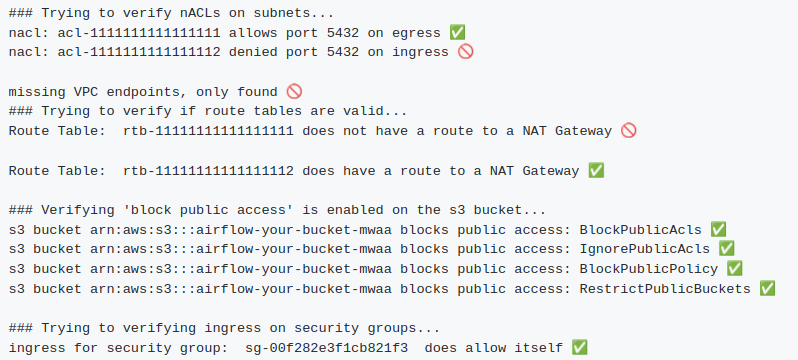
The Infrastructure DevOps Team manages the infrastructure in Hashicorp Terraform. Infrastructure as code was a crucial step for the company because, in their old setup, it wasn’t clear what was currently deployed in AWS and with which configuration, making it challenging to replicate setups or restore infrastructure after something failed. It also made the infrastructure easier to understand and manage, for example, if changes are necessary. BI Users can see the reports in their tool, which fetches the data from Athena and the metainformation from the Glue Data Catalog. The advantages for them are mainly a faster and more stable environment. Now that we had a look at the final architecture, let’s talk a little bit about the challenges we faced getting there and what you could learn from them, so you don’t have to go through the same pain. Migrating an Airflow Cluster can be difficult, especially one with many plugins and dependencies. The first thing we did, which you should do as well, is to ensure that the infrastructure is configured correctly. There is a great tool to help you verify your setup. This program checks all the reasons MWAA doesn’t behave as you want it to and gives you a neat report. The only thing it can’t check is the content of your plugins and dependencies.
At the time, MWAA was a little behind in available versions of Airflow, which left us no choice but to downgrade the on-premise Airflow to 2.0.2 while migrating it to MWAA. A month after the project was finished, 2.2.2 was released, and everything would have been much easier. Anyway, the main problem with downgrading is that some operators and packages are no longer available, at least not in the version that was used on-premises. Imagine you have a requirements.txt with 40 packages, each pinned to the exact version that works with Airflow 2.1.2 and not 2.0.2. There are two ways to tackle this problem. One is to remove everything, start re-adding packages, and see if the MWAA is still starting. That is very time-consuming because an MWAA launch can take up to 20 minutes. The second and better way to do this is to use mwaa-local-runner, a helpful tool that allows you to test your dependencies locally, which is faster, and logs are easier to access. Now we could get a stable Airflow environment, but while fixing packages and versions, we noticed that in MWAA, there is actually a lot already built-in. In the end, we nearly eliminated all entries from the requirements.txt, which is great because now we no longer have to check if everything fits together. Another important switch was to go from submitting EMR jobs via Livy to just using EMR Spark Steps. This meant we had to rewrite the code a little, but it was well worth it because now AWS takes care of our connection, and if the IAM roles are set up correctly, we don’t have to worry about managing credentials. EMR Spark Steps is also the more native AWS solution. It performed better for debugging, retrying, and parallelization. Ultimately, we could also eliminate the need for custom plugins, which was another huge step towards a stable environment and less operational overhead.
Conclusion
In this blog post, I explained how one of our customers migrated to Amazon Managed Workflows for Apache Airflow (MWAA), the steps we took as part of that migration, and the lessons we learned along the way.
The Key Takeaways regarding this migration are:
- Check your dependencies and reduce them as much as possible.
- Don’t be afraid to rewrite code if it benefits you long-term.
- AWS Troubleshooting and Documentation are helpful and up-to-date tools you should use.
— Peter Reitz