Sneaky Injections - CloudFormation
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
During one of our recent AWS Security Reviews, I ran across an interesting technique that attackers can use to create a backdoor in AWS accounts. It works by using three S3 IAM actions, CloudFormation, and an administrator who is not careful enough.
This vector is not new but still scary - and today, I will show you how to check your account for this risk and any previous compromises.
Intro
I became aware of this attack vector on RhinoSec’s blog post a while ago but just remembered its significance during an in-depth IAM check for a customer. As the original blog entry goes into all requirements and even includes a demo video, I will only summarize the attack here and go into how to detect or prevent it:
The core idea is pretty simple - if a user or role has permissions to replace CloudFormation templates right before deploying, they can insert something like a cross-account IAM role without detection.
This vector will only require three specific permissions on an exploitable role:
s3:PutBucketNotificationto detect a new template uploads3:GetObjectto get the documents3:PutObjectto overwrite it with a modified version
If the exploited AWS account does not have S3 Data Event logging in CloudTrail or S3 versioning enabled, chances are hight that the compromise will be unknown for a while.
Detecting Compromise
Luckily it is easy to check if your CloudFormation template buckets have notifications enabled, as AWS Config now has Advanced Queries.
Assuming you have an organization-wide, multi-region Config Aggregator configured (now might be a good time to do this, if you have not already), you can use the following query:
-- Config Query: CloudFormation Template Buckets with Notifications
SELECT
accountId,
resourceId,
awsRegion,
supplementaryConfiguration.BucketNotificationConfiguration.configurations
WHERE
resourceType = 'AWS::S3::Bucket'
AND resourceId LIKE 'cf-templates-%'
Usually, none of your buckets should have a notification configuration. So, if your output looks like the screenshot shown, you might have an issue. In that case, check the details of this notification and verify the use case and account ID.
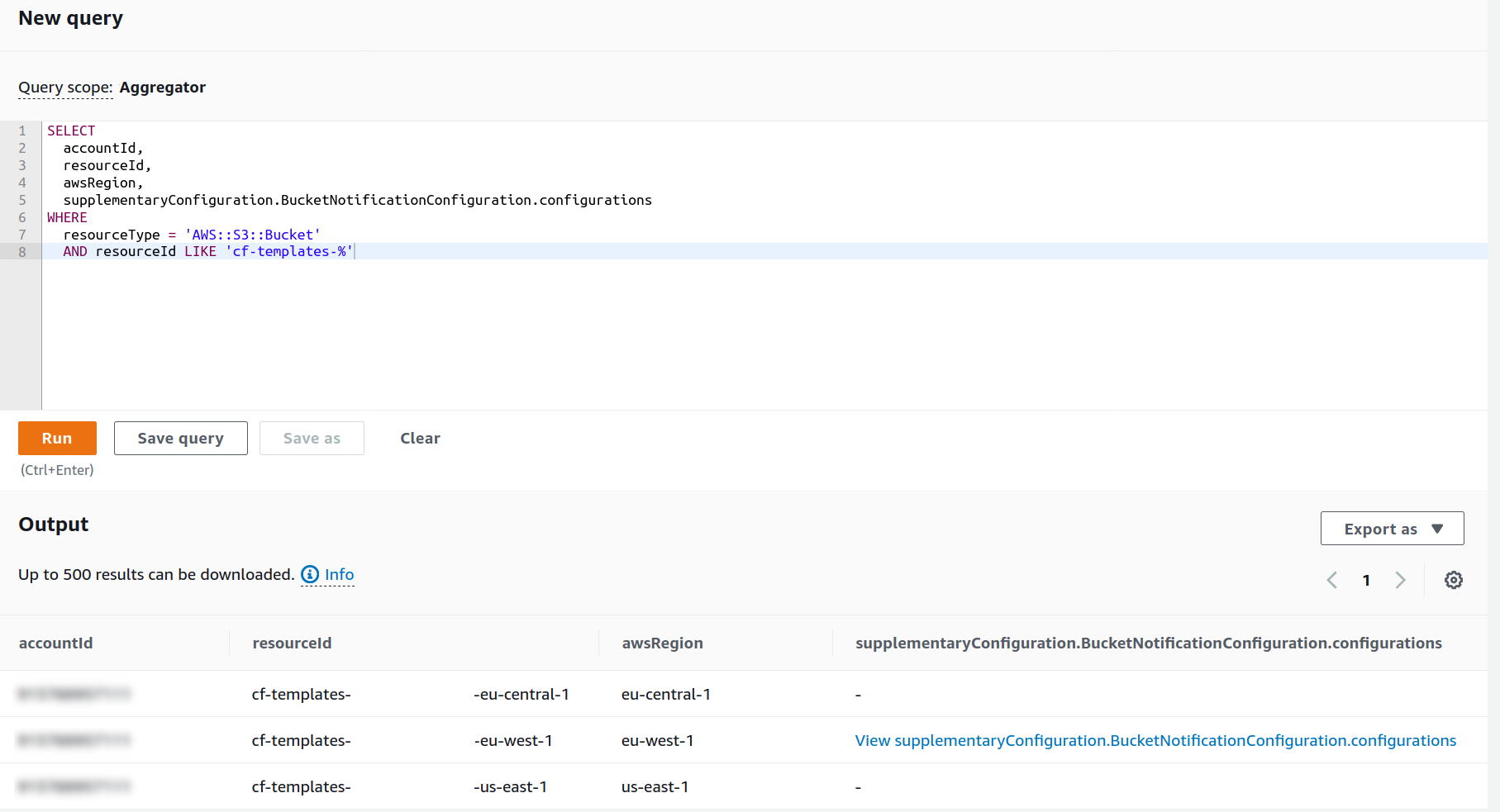
It is worth noticing that a savvy attacker might use this only once to deploy their backdoor and then remove the notification to evade detection.
For this case, you can use CloudTrail Lake and an SQL query to determine all PutBucketNotification actions:
-- CloudTrail Lake: S3 PutBucketNotification on CloudFormation Template Buckets
SELECT
eventTime,
element_at(requestParameters, 'bucketName') as bucketName,
awsRegion,
userAgent,
sourceIPAddress
FROM
d4c16b8b-6705-481b-b731-ee1d90e1edd1
WHERE
eventName = 'PutBucketNotification'
AND element_at(requestParameters, 'bucketName') LIKE 'cf-templates-%'
ORDER BY eventTime DESC
Detecting Risky Privileges
As stated previously, the critical combination of privileges is s3:PutBucketNotification, s3:GetObject and s3:PutObject on buckets starting with cf-templates-. Currently, there is no AWS built-in way to query who has this combination - but there is a tool called PMapper which I introduced in an earlier blogpost.
If you have the tool installed, you can download all your IAM data (even multi-account) and run interactive queries. For our use case, the following commands show all roles and users with the critical privileges:
# Download IAM data and create a graph database
pmapper graph create
pmapper query "who can do s3:PutBucketNotification,s3:GetObject,s3:PutObject with cf-templates-*"
Preventing this Attack
As creating such notifications on CloudFormation template buckets is a very unusual pattern, I would recommend preventing it via IAM or even with a Service Control Policy:
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "PreventCfnBucketNotifications",
"Effect": "Deny",
"Action": "s3:PutBucketNotification",
"Resource": "arn:aws:s3:::cf-templates-*"
}]
}
Please check if you have valid use cases of notifications like these before deploying this document as an organization-wide policy.
Summary
This technique has been around for a while and is even part of popular penetration testing tools like PACU (see its cfn__resource_injection module).
With the recent introduction of SQL statements on AWS Config and CloudTrail, its detection has become much more accessible, and SCPs can even prevent it entirely.
As always, check your accounts and keep current on AWS news - the creativity of attackers is considerable, and there are probably plenty of variations to backdoor an AWS account if you are not careful enough.