S3 Cross Account Adventures
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Update October 2020
AWS has finally added a feature to solve our problem, now all that’s missing is CloudFormation support :-)
In the process of building a data lake in a multi-account environment, we encountered a problem that didn’t fit into our existing mental model of how S3 and S3 cross account permissions work. Chances are that the behavior might surprise you as well.
We had planned to build a data storage platform that’s similar to a data lake in a multi-account environment. Essentially, this means that we were separating the data from the transformation and input/output logic. The reason for this being that we wanted to provide different permissions for the different accounts. Furthermore the components in each of the accounts have a different lifecycle and we wanted to reduce the chance of inadvertantly breaking something.
Our setup looks roughly like this:
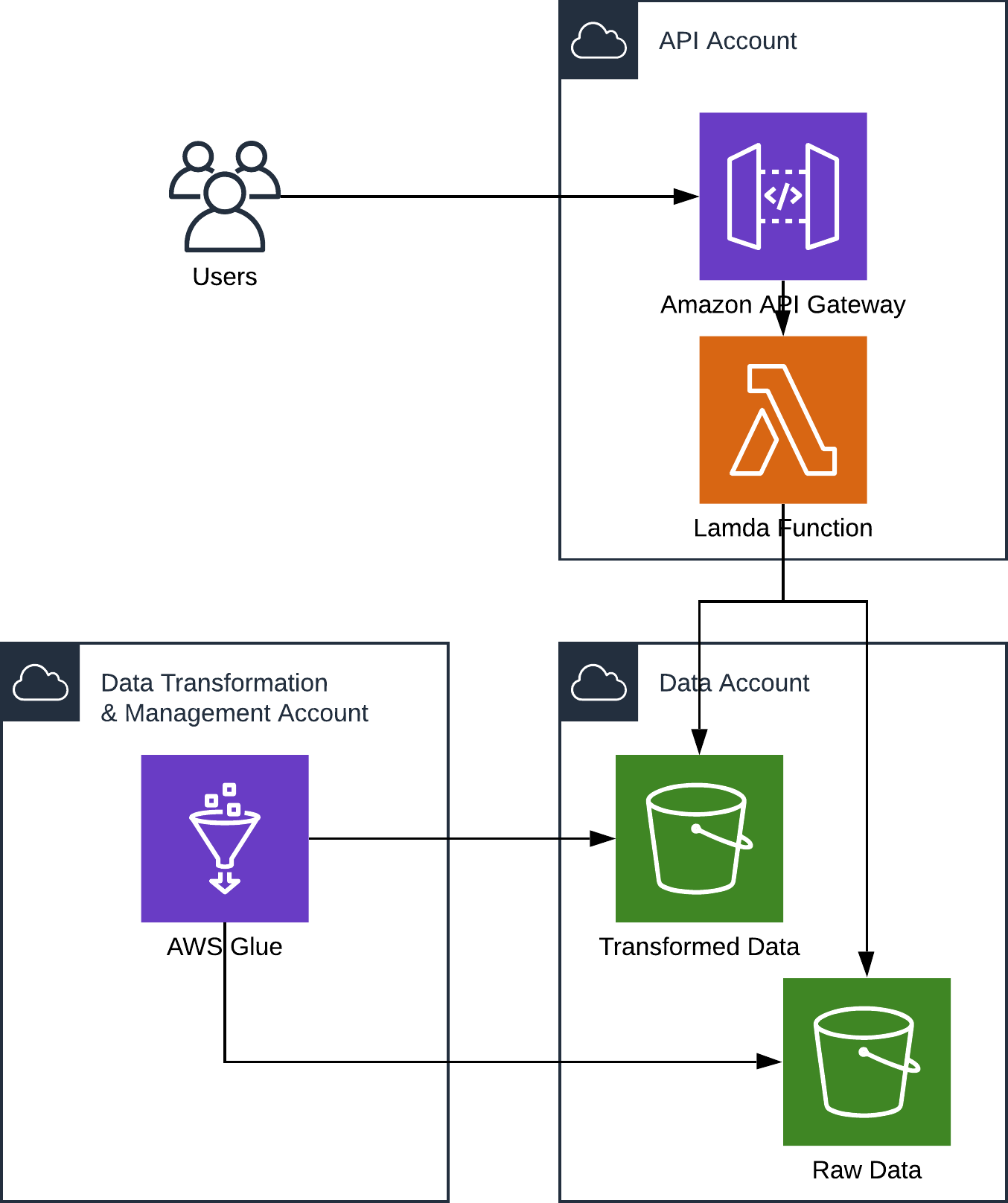
The users interact with an API Gateway in the API account to store and retrieve pieces of data. The data account holds mostly S3 buckets that either store raw data or some transformed version of that data. The transformation is done by processes in a data transformation and management account, examples for tools here include Glue, Athena and Lambda.
In order to make this work, we had to set up cross account data access permissions for our S3 buckets. Initially we thought this was going to be very simple. Just slap a bucket policy on the data buckets that allows access from the respective lambdas and/or data transformation processes in the transformation and API accounts and be done with it.
Sounds reasonable? We thought so too…
You wouldn’t be reading this if it was that easy. In our initial tests we encountered a problem. Writing data from the API account to the data buckets in the data account worked as intended through the bucket policy. Trying to access the data from the data account resulted in us getting Access Denied errors.
That was unexpected, but we quickly figured out that we needed to use the bucket-owner-full-control ACL setting when putting objects into the bucket, because by default only the owner of the object is allowed to access it.
This way, as the name suggests, the owner of the bucket has full control of the object as well - in this case that meant we could finally access the data inside the data account.
So that’s it, you just add the bucket-owner-full-control ACL during an upload and the rest is handled via the aforementioned bucket policy, right?
Wrong. Unfortunately, this is where things get slightly annoying, to say the least. The data transformation processes in the data transformation and management account were getting Access Denied errors when attempting to access objects in the data account that had been created by the API account. It took us a while to figure out the cause of this error. We also reached out to the AWS Support to get help (thanks Venkat, you’re awesome!).
Turns out, that S3 ACLs are kinda important. S3 ACLs are a subject we had not paid too much attention to in the past, as we had understood that they were basically superseded by bucket policies and things like S3 Access Points for basically all use cases. After we identified the cause we knew where to look in the documentation and recognized that this was one of the few exceptions to that rule, that had served us so well in the past.
ACLs are suitable for specific scenarios. For example, if a bucket owner allows other AWS accounts to upload objects, permissions to these objects can only be managed using object ACL by the AWS account that owns the object. - Source (emphasis ours)
What’s going on here? Well, we learned that each object has an owner and if the owner is different from the bucket owner (i.e. it was put there by another account) the object ACL governs, which permissions apply to that object. The idea here appears to be, that the owner of the object is the only entity that controls what happens to their object, which is fair. It is important to note, that the owner of an object can’t be changed!
We suspect, that we’re not the only ones that sort of glanced over the topic of S3 ACLs in the past, so let’s do a quick summary.
There’s a variety of access control mechanisms for S3 - there’s IAM Policies, Bucket Policies, Access Points with their Policies and last, and quite often the least, Access Control Lists. Access Control Lists can be applied at the bucket and object level. Access Control Lists are a rather blunt instrument - while IAM is a scalpel, an ACL is the proverbial sledge hammer. ACLs work based on a grantee, which is either an AWS account as defined by its canonical id or a group. Note that these are not IAM groups but predefined groups by AWS such as “All authenticated users” or “All users”. If you grant access to an account you can only grant access to the whole account - there’s no conditions or anything like it.
Now that you know who you can grant access to, let’s talk about the different levels of access that can be granted. According to the documentation there’s five different kinds of controls you can apply to buckets and objects using ACLs.
READ- fairly self-explanatoryWRITE- this as wellREAD_ACP- read the ACL configuration of an object/bucketWRITE_ACP- change the ACL configuration of an object/bucketFULL_CONTROL- all of the above
So for each grantee you can specify the level of control for each object. The documentation we linked above has more details on how this maps to API-calls.
Why is all of this a problem? Well, if the object belongs to the entity that uploaded it and we can only use our ACL sledgehammer to control access to it, we’re going to have a bad time trying to explain to security people how this is least-privilege in any way, shape or form.
What can we do about it? Brainstorming led us to the following options:
- All entities that write to the data account assume a role in the data account to write to it when they do that. By assuming a role and then writing, they become the owner of the objects. As the roles live in the data account this means the data account will be the owner of the objects. This has the benefit that we can once again use the bucket policy to control access to our resources. A drawback is that you’re going to have problems when you use services that can’t assume a role in another account (such as the API-Gateway AWS Service integration).
- Add a Lambda function in the data account that is invoked by S3 on PUTs of new events and overwrites the new object with itself. Similar to the solution above, this means that the data account writes the data and becomes the owner of the object. Since the owner is now the data account the bucket policy would apply again. This could work, although you need to make sure not to create an infinite loop. Additionally, this being an asynchronous process could lead to conflicts.
- Add the data and API accounts with full control permissions in the ACL. This would grant access to our main accounts, but isn’t scalable as you can only have up to 100 grantees and it’s also cumbersome to manage if you want to extend the list of accounts.
- Set the permissions of the ACL to Public Read and add an explicit Deny with the bucket policy. This could work in principle, but seems like a horrible pattern to us.
The order of the items in the list is not random. We think that these are the best solutions in the order that they’re presented, although none of them are ideal. Using the assume role solution results in additional complexity for entities that want to write to the data store. While assuming a role is trivial if you control the code such as in Lambda, it’s a lot more challenging and in some cases not possible when using other services. In the case where this is not possible, it would mean that the writer gets permissions to write to the S3 bucket using the bucket policy and the reader would have to assume a role in the data account in order to be able to read it.
Conclusion
Cross-Account-Access with S3 can get quite weird quite fast. As long as you want to read data from a bucket in an account that also produces it, you can do that via a bucket policy. If that’s not the case you need to really think about the least terrible solution for this problem.
All of this could be avoided if S3 would allow you to transfer ownership of an object to the bucket owner while creating it.
A flag/header along the lines of transfer-ownership would be terrific.
To us this doesn’t seem to break any of the existing S3 functionality so maybe this is something for #awswishlist.
Thanks for reading this - if you have additional questions or feedback, feel free to reach out to us via any of the social media channels in our profiles.
References / Further Reading
- Guidelines for using the available access policy options (thanks for pointing this out, Uwe!)
- Managing Access with ACLs