Calculating AWS DocumentDB Storage I/Os
Amazon DocumentDB is a fully managed native JSON document database that is mostly compatible with MongoDB. Why mostly? Because it it has a few functional differences from MongoDB and some MongoDB features are not supported. Despite from these limitation, customers benefit from a managed database service that has built-in security, backup integration, scalability and fault-tolerance. This rids customers from many operational burdens. AWS DMS (Database Migration Service) supports the migration from MongoDB to DocumentDB.
Apart from the functional evaluation, pricing should of course be taken into consideration before migrating to DocumentDB as well.
DocumentDB’s pricing is based on four factors:
- Instance type and number of instances: This is similar to other services such as EC2 or RDS.
- Database storage: $0,119 per GB-month (region eu-central-1)
- Backup storage: $0,023 per GB-month (region eu-central-1)
- I/Os on the cluster’s storage volume: $0,22 per 1 million requests (region eu-central-1)
While number 1-3 are fairly simple to estimate especially when migrating from an existing MongoDB, cost factor number 4 can be a tricky one. How to we get down to the number of I/Os that we will presumably consume, before actually consuming and paying for them? Let’s look into the details.
How DocumentDB calculates I/Os
I/Os are billed when pushing transaction logs to the storage layer. What is the storage layer? Looking at DocumentDB’s architecture, we can see that compute resources are detached from the storage resources. No matter how many instances you have in your DocumentDB cluster, all data will always we stored in six copies across three availability zones. This architecture is similar to Amazon Aurora databases and a big advantage compared to other database solutions. In the context of I/O calculation, this is important to know because it means that I/Os are not counted multiple times for multiple instances inside a cluster.
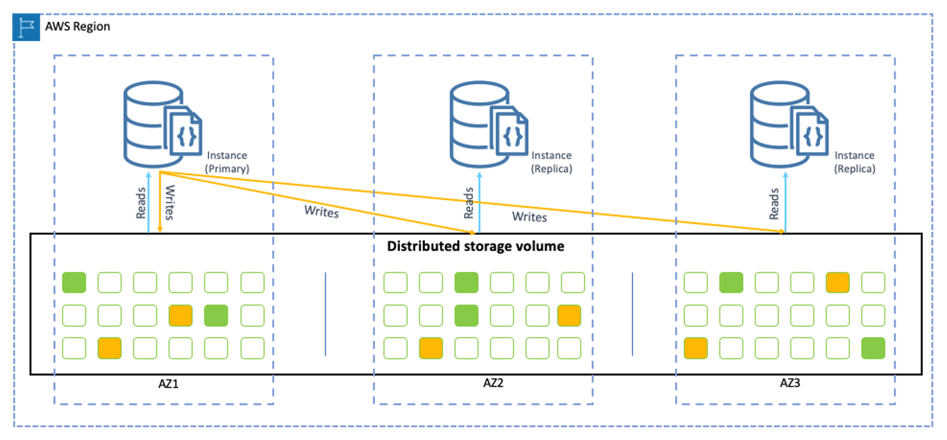
The second important thing to note is that I/Os are calculated in 4KB chunks for write operations and 8KB chunks for read operations. That means, if we write 1KB, we will be charged 1 I/O, if we write 4 KB, we will also be charged 1 I/O, and if we write 5 KB, we will be charged 2 I/Os. The same principle applies to the read operations.
Hence, there is a couple of things that we need to measure or estimate in average or by data category:
- Size: How large is the data written per operation?
- Frequency: How often do we write it (e.g. per second)
The monthly I/O consumption for write operation can then be calculated as:
ceil(Size/4) x Frequency per Second x 2628000 (<- one month has this many seconds)
- Size: How large is the data read per operation?
- Frequency: How often do we read it (e.g. per second)
The monthly I/O consumption for read operation can then be calculated as:
ceil(Size/8) x Frequency per Second * 2628000
However, for read operations, there is another thing to factor in: The cache hit ratio. DocumentDB has a built-in cache. The cache utilisation depends on the number of repeated transactions, but also on the memory that is available on the instance, and hence on the instance type selection. To simplify, we will assume that the instance type is large enough to keep the entire database in memory. The third question to answer for read operations is then;
- Cache Hit Ratio: What proportion of read operations are repetitions of previous read operations (e.g. 80%)
Consequently, we need to adjust above formula for the read operations:
ceil(Size/8) x Frequency per Second x 2628000 x (1 - Cache Hit Ratio)
Another particularity of write operations is that they can be batched together when they run concurrently, thus reducing the overall amount of I/Os consumed. We will ignore that fact for the I/O estimate as the potential savings of this are very dependent on the usage pattern of the DocumentDB. However, when executing lots of small write operations, this can have a significant savings effect.
Example
Let’s make an example with the following figures:
Write:
- Size: 2 KB
- Frequency: 3 per second
The number of monthly I/Os for write operations is:
1 x 3 x 2628000 = 7.884.000
Read:
- Size 6KB
- Frequency: 5 per second
- Cache Hit Ratio: 75%
The number of monthly I/Os for read operations is:
2 x 5 x 2628000 x (100% - 75%) = 6.570.000
The sum is roughly 15 Mio. of monthly I/Os, multiplied by the price per Mio. of 0,22$, the result is 3,30$.
15 x 0,22 = 3,30$
Title Photo by Towfiqu Barbhuiya on Unsplash