Run Shell Scripts as Lambda
Sometimes, developing a fully-fledged Lambda is not feasible, is too much work, or is simply outside of the knowledge domain of the people involved. But what if we could run plain Bash scripts instead?
For this to work, we will have to create a custom Lambda runtime, which takes ordinary Bash code instead of Python/Ruby/Java/…, executes it and returns it in the format that Lambda expects.
Lambda Custom Runtimes
The functionality of Custom Runtimes has been introduced long ago and formally announced at AWS re:Invent 2018. It makes use of the Lambda Layers feature which has been sparking innovations ever since: using Docker images as the base for Lambda, prepackaging often-used libraries, and adding Lambda extensions, …
While it is geared towards creating runtimes for new or uncommon languages like Rust, Perl, PHP it potentially also could be used to support YAML-based instructions to an entirely different, short-running process.
Formally, they are based on a few components
- Lambda Layers for prepackaging runtime environments
- a
bootstrapfile as the entry point - the Lambda Runtime API for retrieving Event data and posting Responses
Then, they combine a generic runtime like provided.al2 with the Lambda Layer and execute the bootstrap for every incoming request.
Implementing
You can get a good example of a bootstrap file from Amazon’s documentation on the topic. You can see that there is a defined Lambda Runtime API, which returns the event data as a string (internally a JSON) as well as the Request ID.
For our intended use with Shell scripts, we want to use that passed event data and make it available as environment variables. This can be achieved with jq:
HEADERS="$(mktemp)"
EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next")
eval $(jq -r 'to_entries[] | .key + "=\"" + (.value|tostring) + "\""' <<< "$EVENT_DATA")
This will split the incoming JSON data up into individual entries and convert them to executable key="value" pairs which we can just execute in bash to get the variables set.
We could skip this entire step and rely only on the environment variables that get passed to Lambda, but that would seriously limit the versatility of our scripts. This way, you can just recycle an existing Lambda with multiple events to execute different commands.
After setting the variables, we execute our code. In the AWS walk-through, this means we are sourcing the code passed to the lambda and executing the function inside:
# File "function.sh":
function handler() {
echo "Hallo"
}
Executing this and capturing its output and exit code, we can return the result to Lambda again. Depending on the script, you can either expect strings or a nested JSON as a response. So adequate quoting is important
Infrastructure as Code
Implementing this as code is relatively straightforward. First, create a Lambda layer and base it on the native provided.al2 runtime.
data "archive_file" "runtime" {
type = "zip"
source_dir = "src/custom_runtime/"
output_path = "builds/runtime.zip"
}
resource "aws_lambda_layer_version" "shell" {
filename = "builds/runtime.zip"
layer_name = "shell_runtime"
compatible_runtimes = ["provided.al2"]
source_code_hash = data.archive_file.runtime.output_base64sha256
}
Secondly, you need to add the related bootstrap file to your src/custom_runtime directory. And then also get jq binary downloaded there before packaging, because we need to process JSON.
This is, where we hit a problem with Custom Lambda Runtimes - as we cannot simply use the packaging tool yum for installing tools into it.
As we do not want to download this every time we call the Lambda (out of performance and ultimately cost considerations), we should bake this in. With some OS-Detection tricks and OS-dependent local downloads, this is solved quickly.
And to make this quick, I provided you with a reusable Terraform module for shell-runtimes on my GitHub page.
Example
Let’s execute some Bash script as Lambda on AWS. In this case, I decided to use a weather report API and let a site pick a random city: Accra, the capital of Ghana.
Our Bash code for the API is very easy - it only passes the city as an environment variable and requests the j1 format (JSON):
# File "src/lambda/function.sh":
function handler() {
curl --silent http://wttr.in/$CITY?format=j1
}
Now, all we need to do is to use the shell-runtime module and combine it with the ubiquitous Lambda module
module "shell_runtime" {
source = "tecracer-theinen/terraform-aws-shell-runtime"
version = "0.1.0"
}
module "lambda_function" {
source = "terraform-aws-modules/lambda/aws"
version = "4.18.0"
function_name = "get-weather"
handler = "function.handler"
publish = true
timeout = 10
# Use the shell runtime
layers = [module.shell_runtime.runtime_arn]
runtime = "provided.al2"
source_path = [{
path = "src/lambda/"
}]
}
And this creates our whole function and allows us to play around with it in the AWS Web Console:
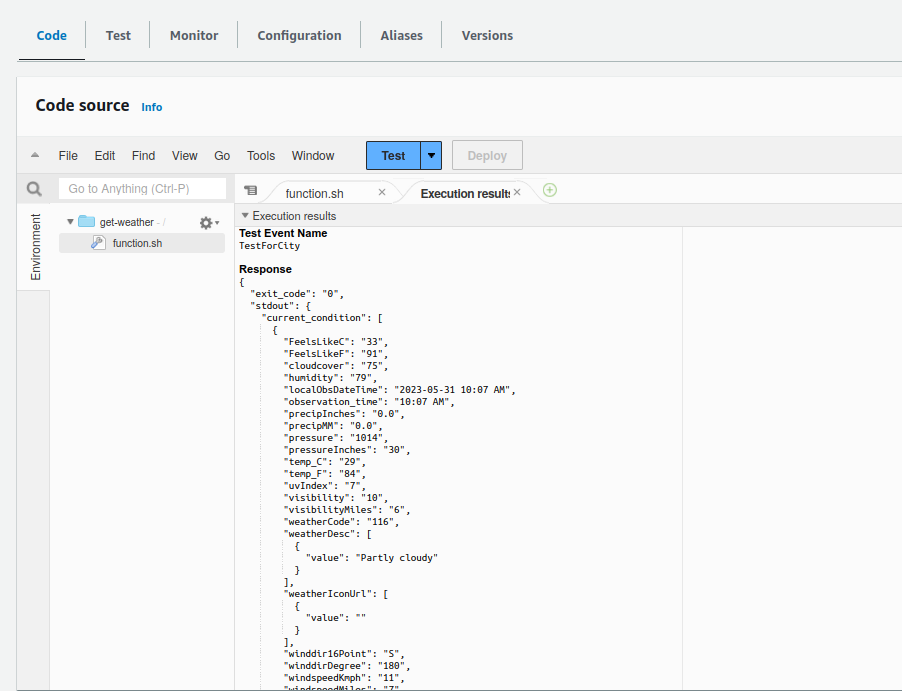
In this case, I passed a small test event
{
"CITY": "Accra",
"JSON_RETURN": true
}
But you can also directly execute it with AWS CLI:
aws lambda invoke --function-name get-weather --cli-binary-format raw-in-base64-out --payload '{ "CITY": "Chicago" }' output.json
jq . output.json
Summary
With this solution, you can easily execute one-off commands in your projects. Additionally, VPC-enabled Lambda functions enable you to access in-VPC resources and APIs - like Amazon FSx for NetApp ONTAP, CloudHSM clusters, or databases in private subnets.
You can combine this will all other Lambda functions like function URLs, wire it up to API Gateway, or use them inside of Step Functions. Have fun!