Solving Hive Partition Schema Mismatch Errors in Athena
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Working with CSV files and Big Data tools such as AWS Glue and Athena can lead to interesting challenges. In this blog I will explain to you how to solve a particular problem that I encountered in a project - the HIVE_PARTITION_SCHEMA_MISMATCH.
This post assumes some basic understanding of Glue and its components. If you’re not familiar with the service, feel free to check out my introduction to it. It’s also helpful if you’ve worked with Athena before, but it isn’t required knowledge, since this is only one tool that can trigger the issue. First we’re going to start with some set up to explain how this error can occur.
Sample Data
I’ve created a script that creates some sample data, which will eventually trigger this error when working with the data. You can find all of the code on GitHub. This script generates data for a partitioned products table. Each product has a supplier name, product name, price, quantity and weight. The products are partitioned by suppliers, although these have interesting names in my examples. Here are excerpts from two data samples:
Supplier: double_with_weight
"supplier_name";"product_name";"price";"quantity";"weight"
"double_with_weight";"Christopher";4339.26;8622;29
"double_with_weight";"Sean";9068.08;3501;28
"double_with_weight";"Danielle";4285.51;7612;2
"double_with_weight";"Rebecca";9009.99;1358;29
"double_with_weight";"Michelle";8097.9;3382;11
Supplier: int_with_weight
"supplier_name";"product_name";"price";"quantity";"weight"
"int_with_weight";"Kayla";9092;793;50
"int_with_weight";"Danielle";9294;2365;46
"int_with_weight";"Kristy";4058;2989;7
"int_with_weight";"Kelli";2582;2887;14
"int_with_weight";"Rebekah";959;5627;26
If you take a look at the data, you’ll see why the suppliers have such peculiar names. In the first case, all the prices are decimal numbers, which are represented as doubles or floats and in the second example they are integers.
If you follow the instructions in the repository, the data will be uploaded to S3 in a structure like this:
└── products_partitioned
├── supplier=double_with_weight
│ └── data.csv
├── supplier=double_without_weight
│ └── data.csv
├── supplier=int_with_weight
│ └── data.csv
└── supplier=int_without_weight
└── data.csv
Glueing things together
Using these keys allows us to give the system a hint as to how the data is partitioned. We tell it that the partition-column is called supplier and which value the data files have for the respective partitions. If we now start a Glue Crawler, it will create a partitioned table in the Glue Metadata Catalog. These are the columns and data types the crawler has discovered:
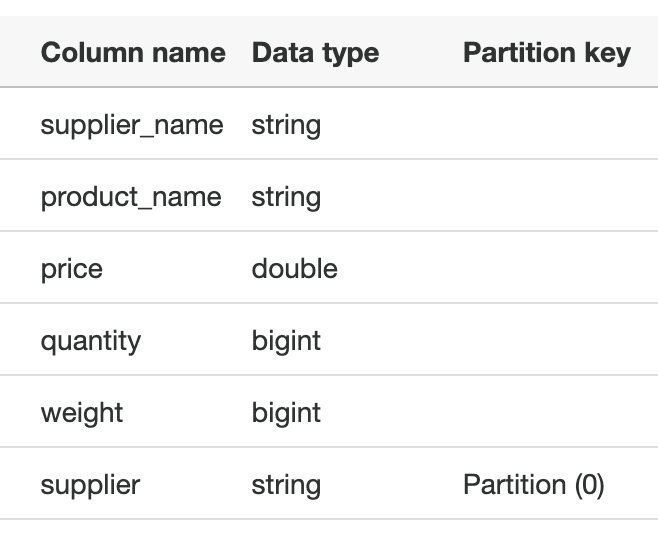
Note that the crawler decided on the data type double for the price column, which should be able to represent both our integer as well as our double values. If we now use Athena to get data from the table, we’d expect it to be able to get all the records without issues. Unfortunately that’s not the case here - we get a HIVE_PARTITION_SCHEMA_MISMATCH.
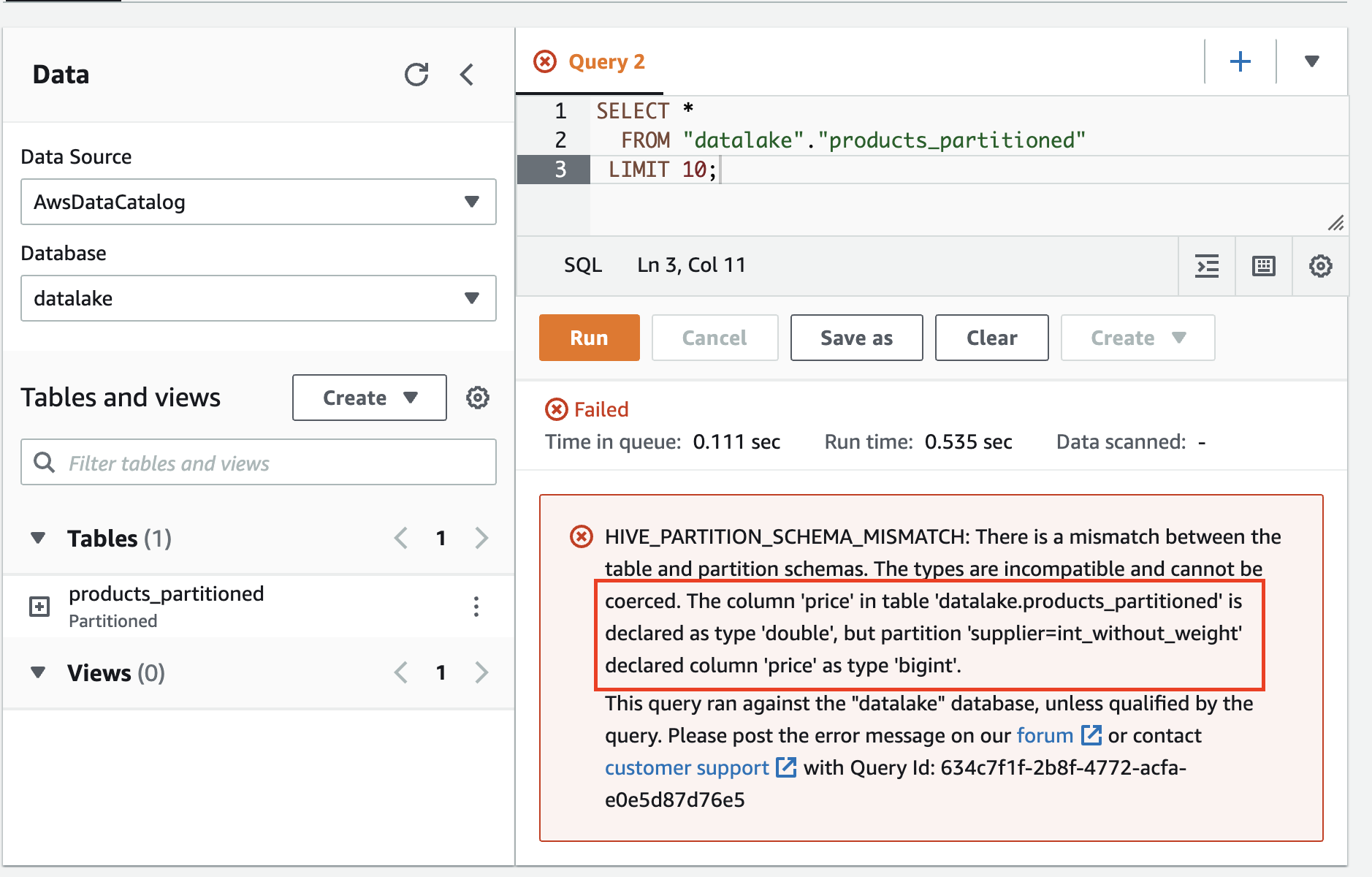
The error is:
HIVE_PARTITION_SCHEMA_MISMATCH: There is a mismatch between the table and partition schemas. The types are incompatible and cannot be coerced. The column ‘price’ in table ‘datalake.products_partitioned’ is declared as type ‘double’, but partition ‘supplier=int_without_weight’ declared column ‘price’ as type ‘bigint’.
It tells us, that it couldn’t read the partition with the name int_without_weight, because the partition considers the column price to be of type bigint whereas the table says it should be double. If we take a look at the partitions in the Glue Metadata Catalog, we can see that this is indeed the case.
How did we get here?
It seems like the crawler took a look at all the files and created a partition definition based on each individual file. Somehow it then decided that the table itself should get the double data type for the price column - possibly, because it can also accommodate integers, but that’s speculation at this point. When Athena reads the table, it seems unable to handle this disparity, because it’s possible that columns of type bigint hold values that are too large for a double data type to represent.
If we read data from only those partitions that have the right data type, we’re fine - the following query runs without issues.
-- Query that doesn't touch the int partitions
SELECT *
FROM "datalake"."products_partitioned"
WHERE supplier = 'double_without_weight'
OR supplier = 'double_with_weight'
LIMIT 10;
Where do we go from here?
Only being able to work with one half of the data is not really an option, so we need to come up with a different solution. In this case we know our data and we also know that the double data type would be able to fit all the integer prices we might have in our product catalog. This means, we can update all the price columns in the partitions to have the same data type as the base table. This will only change the metadata of the table, since the actual data is only coerced into the data types when it is read. The solution looks something like this:
def main():
database_name = "datalake"
table_name = "products_partitioned"
make_partitions_inherit_datatypes_of_table(
database_name=database_name,
table_name=table_name
)
if __name__ == "__main__":
main()
Problem solved, thank you and goodbye.
Wait… make_partitions_inherit_datatypes_of_table - it can’t be as easy as that, right? Right. We need to actually implement that function. You can see the implementation below. It’s divided into four parts. First, we describe the base table and its data types. Second, we list all the partitions of that table and afterwards figure out, which ones we need to update because the data types don’t match. Fourth we update all the partitions where changes are necessary.
import boto3
def make_partitions_inherit_datatypes_of_table(database_name, table_name):
glue_client = boto3.client("glue")
# Get the data types of the base table
table_response = glue_client.get_table(
DatabaseName=database_name,
Name=table_name
)
column_to_datatype = {
item["Name"]: item["Type"] for item in table_response["Table"]["StorageDescriptor"]["Columns"]
}
# List partitions and datatypes
partition_params = {
"DatabaseName": database_name,
"TableName": table_name,
}
response = glue_client.get_partitions(**partition_params)
partitions = response["Partitions"]
while "NextToken" in response:
partition_params["NextToken"] = response["NextToken"]
response = glue_client.get_partitions(**partition_params)
partitions += response["Partitions"]
print("Got", len(partitions), "partitions")
partitions_to_update = []
for partition in partitions:
changed = False
columns = partition["StorageDescriptor"]["Columns"]
new_columns = []
for column in columns:
if column["Name"] in column_to_datatype and column["Type"] != column_to_datatype[column["Name"]]:
changed = True
# print(f"Changing type of {column['Name']} from {column['Type']} to {column_to_datatype[column['Name']]}")
column["Type"] = column_to_datatype[column["Name"]]
new_columns.append(column)
partition["StorageDescriptor"]["Columns"] = new_columns
if changed:
partitions_to_update.append(partition)
print(f"{len(partitions_to_update)} partitions of table {table_name} will be updated.")
# Update partitions if necessary
for partition in partitions_to_update:
print(f"Updating {', '.join(partition['Values'])}")
partition.pop("CatalogId")
partition.pop("CreationTime")
glue_client.update_partition(
DatabaseName=partition.pop("DatabaseName"),
TableName=partition.pop("TableName"),
PartitionValueList=partition['Values'],
PartitionInput=partition
)
If we now run the code, we’ll see an output like this:
$ python data_type_inheritance.py
Got 4 partitions
2 partitions of table products_partitioned will be updated.
Updating int_with_weight
Updating int_without_weight
Having done that, we can finally query our table in Athena and the error is gone.
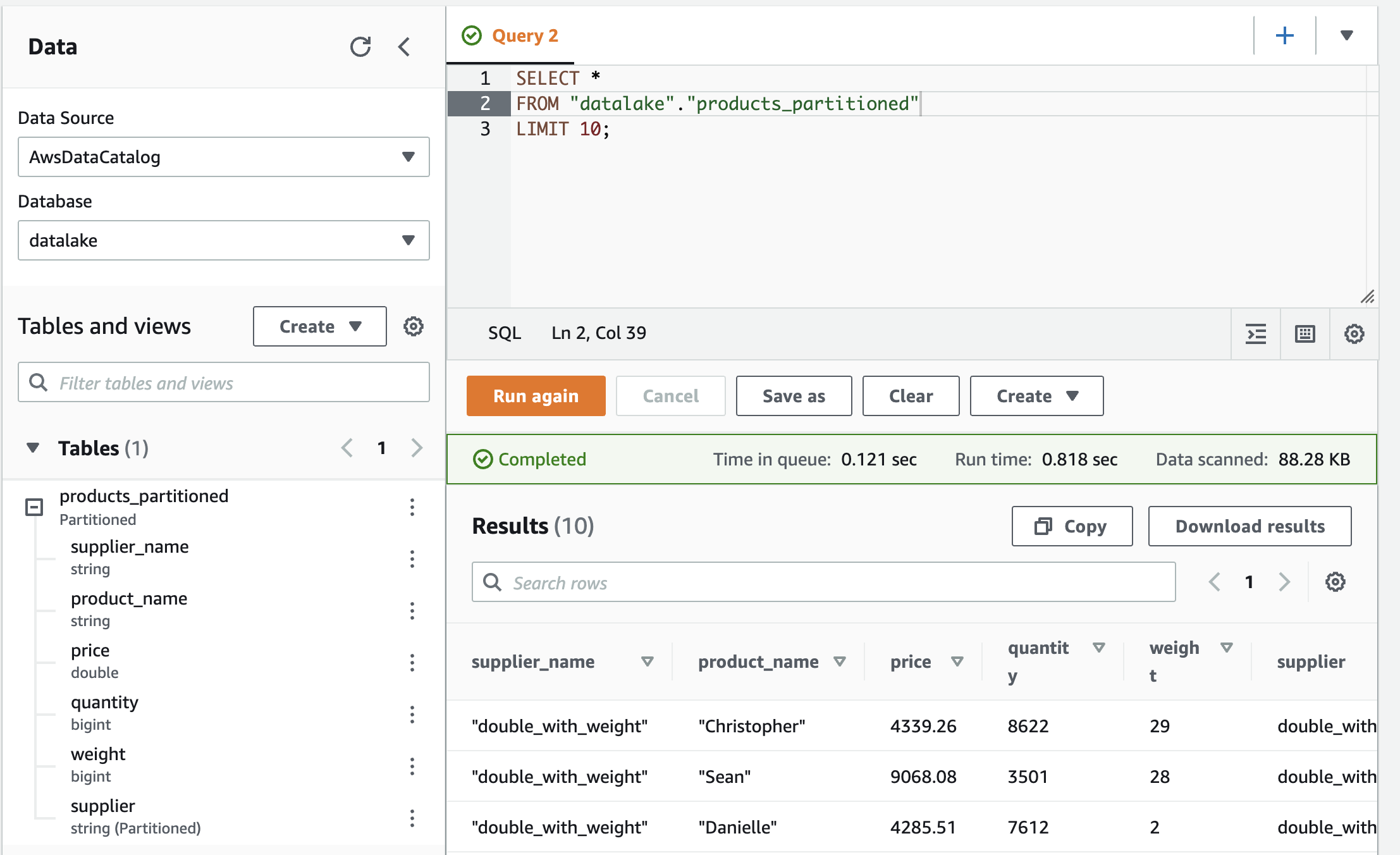
This works whenever Glue picked a data type for the base table that can also accommodate the values in all partitions. From my experience it’s fairly good at that, so this solution should be appropriate there. If that’s not the case, you’ll have to first change the data type in the base table and then run the script.
Summary
In summary, there are situations in which Glue Crawlers will set different data types for the same column in different partitions. In many cases the base table will get a data type that can accommodate all the data points in the partitions. The HIVE_PARTITION_SCHEMA_MISMATCH appears when you try to read from such a table.
The fix outlined here takes the data types from the base table and basically applies inheritance, so all the partitions in the table will have the same data type as the base table.
Thank you for your time and if you have any feedback, questions or concerns, feel free to reach out to me on the social media channels linked in my bio.