What I wish somebody had explained to me before I started to use AWS Glue
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Introduction
AWS Glue is a service I’ve been using in multiple projects for different purposes. It’s not really a single service, but more like an umbrella encompassing multiple capabilities. In the beginning, I struggled to build a mental model of the different components, what they do and how they interact. I thought I’d write up what I wish I had known when I began; maybe it will help others.
We’ll start with an introduction of the core components and then take a closer look at some aspects: the developer experience, fundamental PySpark concepts and how to orchestrate complex processes. This is not a deep dive into any specific topic, just an overview of the service, it’s components and things I consider useful information.
Core Components
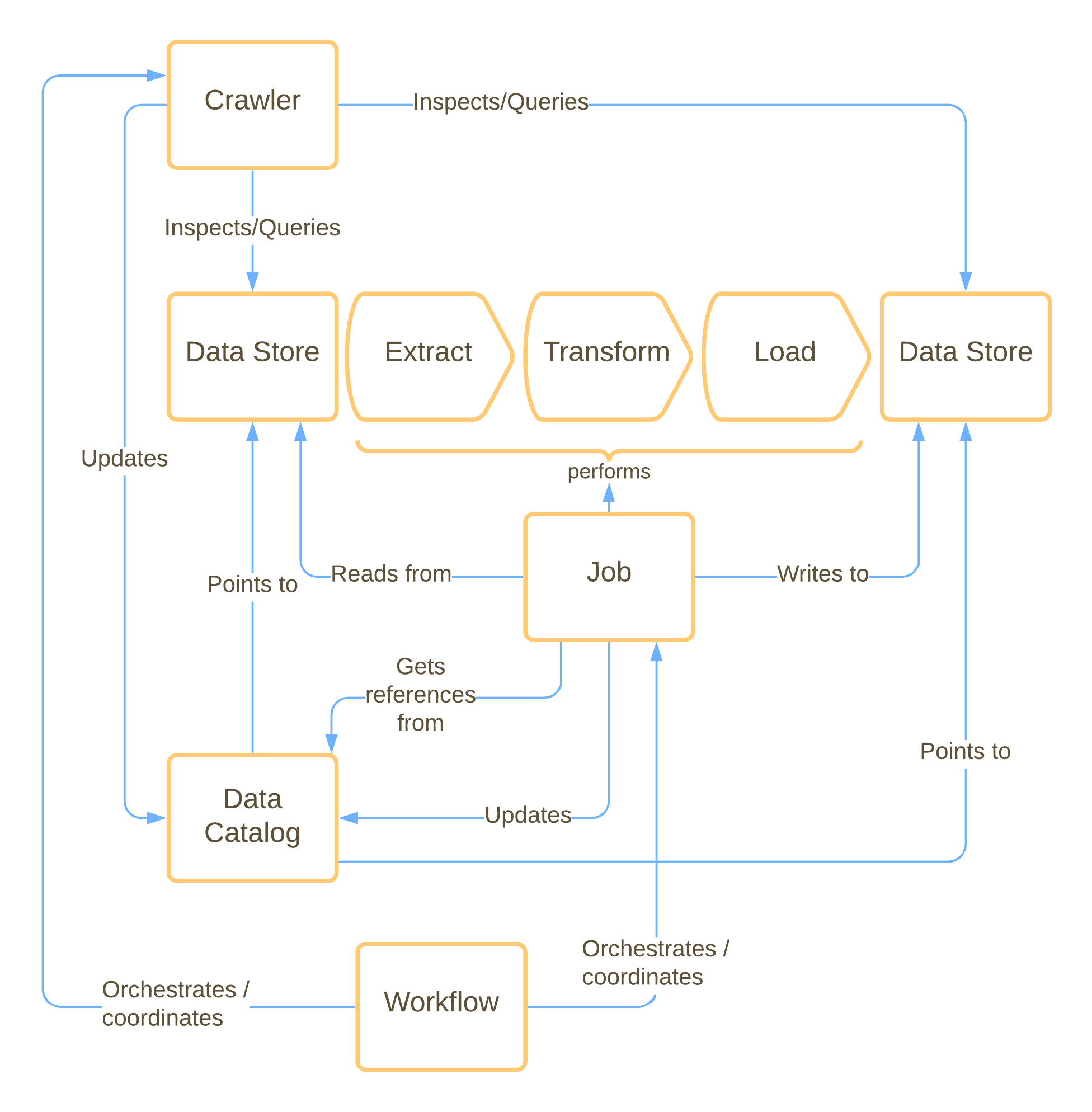
The idea of Glue is to help you move data from point A to point B while also giving you the option to change the data in the process. This process starts with extracting data from one or more data stores, transforming it in some way and then loading it into one or more different data stores. This is the origin of the ETL-acronym: extract-transform-load.
In real life there are usually more than one of these processes or jobs as they’re called in Glue. Sometimes different jobs extract from or write to the same data stores. That’s why it makes sense to have a central system to keep track of these data stores and the data they hold. This central system is the data catalog. It’s organized in databases and tables, just like a relational database, which most of you might be familiar with. One of the main differences between data catalogs and relational databases is that the data catalog doesn’t store any of your data. It only contains metadata and points to the underlying data stores. If you come from a networking background, you can think of it like a router that redirects you to the target destination.
Updating this data catalog could be a tedious and time-consuming manual process and that’s why there is another component of Glue that aims to initialize and update the data catalog. This component is a crawler. You can direct it at different data stores and it tries to find out which data it holds, how it’s organized and how it can be accessed. An alternative to the crawler would be updating the data catalog through a Glue job.
This data catalog is arguably the heart of Glue. It integrates with many different services such as Redshift, Athena, Lake Formation, QuickSight or EMR. Integration in this context usually means that it provides information to these services about where external data stores are located and how they’re organized.
Orchestrating the different components to get a functional data processing pipeline can be done through Glue workflows. Workflows enable you to define and visualize the order in which crawlers and jobs are supposed to be started to facilitate the data transformation.
I have visualized the components and their interaction in the following diagram.
Developer Experience and PySpark
From a developer’s perspective there are different entrypoints when using Glue. The core components I described above are usually created through infrastructure as code frameworks such as CloudFormation, the Cloud Development Kit (CDK) or Terraform. Some people prefer creating them through the console, but infrastructure as code is considered as best practice here in order to have a reproducible environment and reduce the chance of accidental misconfigurations.
To create the transformation logic inside of the Glue jobs themselves, we typically take a different approach. These transformation jobs come in three varieties: Spark, Spark Streaming and Python shell. Spark is usually used to perform the heavy lifting in terms of data transformation. Spark Streaming is an extension of Spark with the niche use case of streaming data. Python shell jobs allow you to run arbitrary Python Scripts in a Glue job without access to a Spark cluster.
Spark Primer
Apache Spark™ is a unified analytics engine for large-scale data processing.
Before we continue, maybe a quick primer on Spark. Spark is a distributed system that you can use to perform In-Memory data transformation of large datasets. The in-memory aspect is crucial here, because it’s part of what makes the system very fast. It’s written in Scala and runs on top of the JVM, but don’t worry - there are frontends for it in different languages such as Python, Java, R or SQL. You can think of Glue Spark jobs as a serverless Spark cluster on which you can run your code either through Python or Scala. Since I’m a Python developer (and don’t know any Scala developers), we’ll focus on the Python part here. The Python frontend to Spark is aptly named PySpark and the interfaces and data structures are fairly similar to what you may know from frameworks such as pandas.
When you’re developing your PySpark job, you’ll primarily deal with three kinds of data structures. These operate at different levels of abstraction. I have added a small diagram to try to illustrate this.
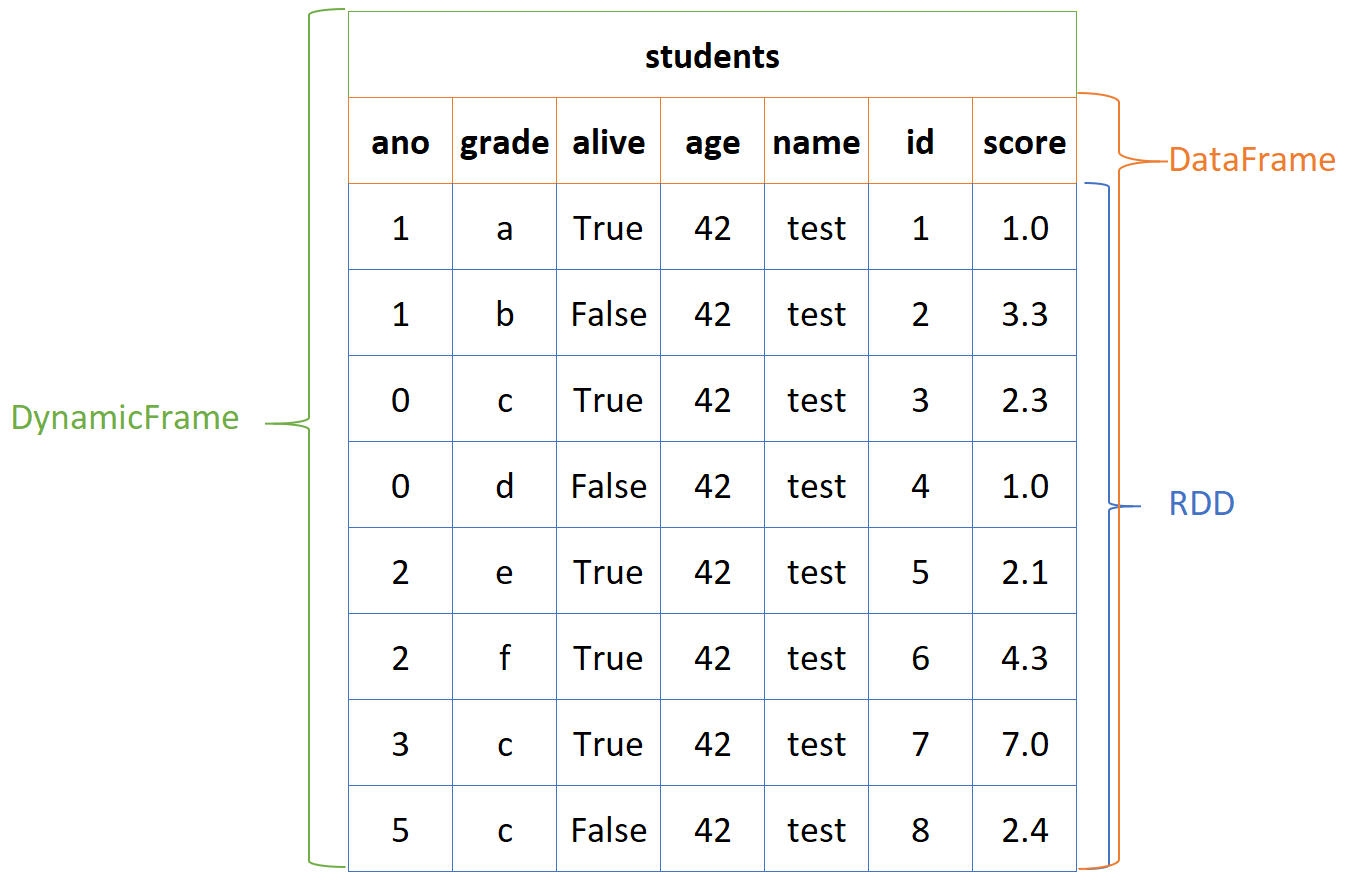
Here we can see what looks like a “students” table that has multiple columns and even more rows with data in them. At the core of the table is an RDD - a resilient distributed dataset. You can think of this as a distributed list of lists. An RDD is distributed across the different cluster nodes in what is known as partitions. Partitions are a set of rows that are stored together and are replicated in such a way that the cluster can tolerate node failure(s). Since it’s annoying to work with this kind of unlabeled data, we usually work with a layer on top of that, which adds column labels. This layer on top is called a data frame - it offers a variety of data access mechanisms and manipulation options.
The third layer on top is the DynamicFrame. This is not a Spark construct, but something that is Glue specific. It allows you to perform advanced transformations on the data in a dynamic frame and to give it a name. Furthermore this integrates with components such as the data catalog to make it easier to load data from known data stores.
There are a few more nuances to the different data structures, but for a mental model to get started this should be sufficient. Moving on to the code.
Let’s take a look at an example of a simple PySpark transformation script to get an idea of the kind of code we might write.
First we initialize a connection to our Spark cluster and get a GlueContext object.
We can then use this GlueContext to read data from our data stores.
The create_dynamic_frame.from_catalog uses the Glue data catalog to figure out where the actual data is stored and reads it from there.
Next we rename a column from “GivenName” to “Name”.
I’m doing this in two ways.
The first way uses the lower-level DataFrame that comes with Spark and is later converted into a DynamicFrame.
This is how you could perform any native Spark transformation on your data.
The second uses the rename_field transformation of the DynamicFrame, which is easier - but also Glue-specific, so you can’t use it outside of the service.
Here you can also see a convention we follow - the variable names are prefixed by dy_ (dynamic frame) or df_ (data frame) to indicate on which layer of abstraction we operate.
The underlying RDDs are immutable, this means that the data inside it can’t be changed. Because of this, each transformation we perform, results in a new data structure we can use. That’s why I can safely perform the same transformation on the original dynamic frame twice.
After the rename operation, I use the glue context to write it to an S3 bucket in the parquet format. There are also other ways to do these transformations. I chose to do it this way to illustrate the dy/df naming convention.
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
# Initialize the connection to the cluster
glueContext = GlueContext(SparkContext.getOrCreate())
# S3 location for output
output_dir = "s3://sample-bucket/output-dir/medicare_parquet"
# Read data into a DynamicFrame using the Data Catalog metadata
dy_medicare = glueContext.create_dynamic_frame.from_catalog(
database="datalake",
table_name="medicare"
)
# We can use the lower-level DataFrame to rename a column:
# Convert to data frame and rename a column
df_renamed = dy_medicare.toDF().withColumnRenamed("GivenName", "Name")
# Convert back to a dynamic frame
dy_output = DynamicFrame.fromDF(df_renamed, glueContext, "MedicareData")
# Or we rename a column through the higher-level DynamicFrame APIs
dy_output = dy_medicare.rename_field("GivenName", "Name")
# Write it out in Parquet
glueContext.write_dynamic_frame.from_options(
frame=dy_output,
connection_type="s3",
connection_options={
"path": output_dir
},
format = "parquet"
)
We could now upload this script to an S3 bucket and point a Glue Job to it, which would then happily execute it. In real life, we typically don’t write these scripts in one go, it’s a more iterative approach. Fortunately there are some tools to support this. One of them are Jupyter Notebooks. A notebook consists of cells and each cell can either be code or documentation. You can execute these cells and get feedback from them - it also keeps track of the execution state. This is a common way to develop your ETL scripts interactively.
Glue notebooks are another component of the Glue service that offer a managed Jupyter notebook server to perform your development work. Glue notebooks are built upon Sagemaker Notebooks but come with a few cool additions. The most important one is an integration with Glue Dev Endpoints. A Glue Dev Endpoint is a Spark Cluster you can provision at your leisure and connect to the notebook instance, which allows you to write your PySpark code interactively. You should be careful though, because the Dev Endpoints are billed for as long as they run and that can get expensive quickly if you forget to delete them at the end of the day. The notebook instances themselves can be stopped though and will retain the scripts stored on them.
Orchestration
The last aspect I want to discuss here is the orchestration of jobs and crawlers. Often you have scenarios where a data processing pipeline consists of multiple levels that have to be worked on sequentially or in parallel. In these cases you could build your own orchestration tool that orchestrates the jobs, use step functions or take the easy route and try out Glue workflows.
A workflow in Glue can be used to schedule crawlers and jobs and define in which order they should be run. Workflows consists of a set of triggers, which can trigger one or more jobs or crawlers and also have preconditions/predicates that determine when these run. This allows you to create a complex sequence of steps and gain real-time insights into the state of your pipeline. You can initialize workflows through an API-Call, as well as time or event-based triggers. Here’s an example of such a workflow.
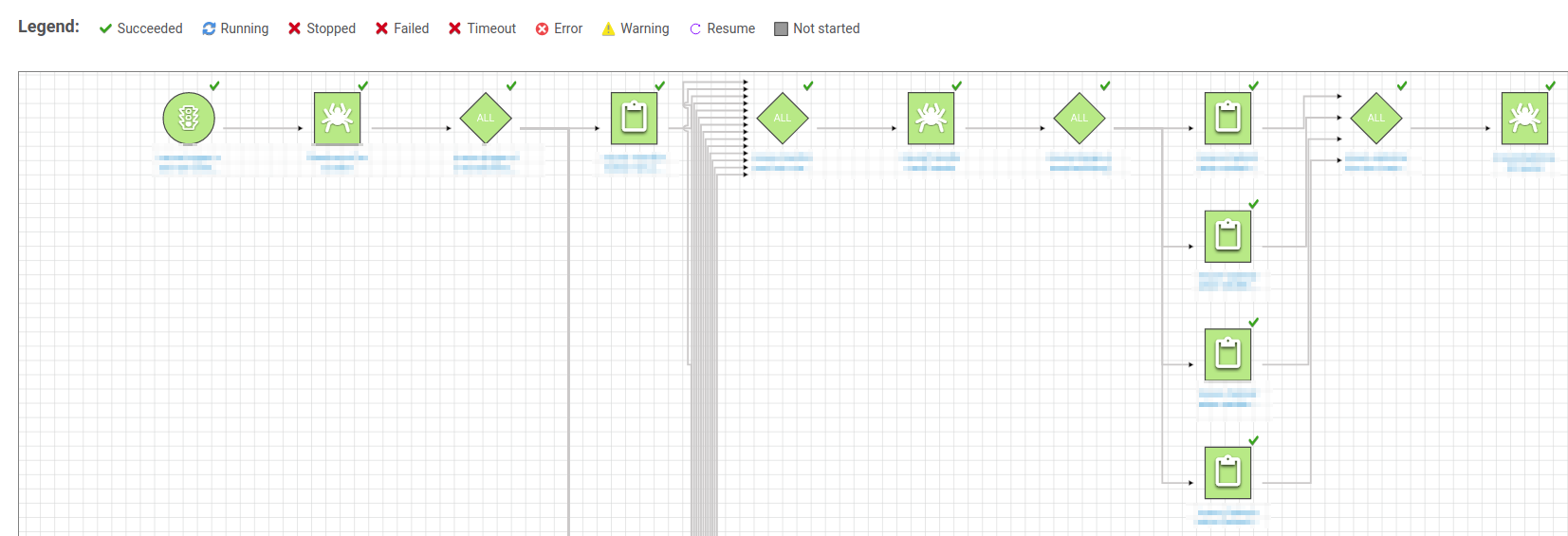
It shows a combination of successive crawler (spider on a square) and job (terminal board on a square) runs with some parallelization as well as the fact that all of these tasks have completed successfully.
Summary
In this post I have introduced the Glue service, its value proposition and its core components. I have also discussed the Developer experience and talked about Spark as well as the main data structures and the general development setup.
If you have feedback, questions or want to get in touch to discuss projects, feel free to reach out to me through the social media channels in my bio.
— Maurice