Automating Athena Queries with Python
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
Automating Athena Queries with Python
Introduction
Over the last few weeks I’ve been using Amazon Athena quite heavily. For those of you who haven’t encountered it, Athena basically lets you query data stored in various formats on S3 using SQL (under the hood it’s a managed Presto/Hive Cluster). Pricing for Athena is pretty nice as well, you pay only for the amount of data you process and that’s relatively cheap at $5 per TB when you consider the effort to set up EMR Clusters for one-time or very infrequent queries and transformations.
In this post I’m going to share some code I’m using to automate queries in Athena.
Using Athena
Interactively
If you use Athena interactively, it is very simple - you have your schemas and tables on the left, your editor on the right and a big beautiful Run query button. Once you enter your query, you wait for the result, it shows a pretty loading-animation and afterwards you get your data, which you could then download as CSV.
Inside of your code
Using Athena inside of your code is a little more annoying, at least when you’re using Lambda and/or try to keep things serverless. Running Athena queries from the SDK is pretty straightforward.
If you were to do it using boto3 it would look something like this:
import boto3
query = "Your query"
database = "database_name"
athena_result_bucket = "s3://my-bucket/"
response = client.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': database
},
ResultConfiguration={
'OutputLocation': athena_result_bucket,
}
)
query_execution_id = response["QueryExecutionId"]
Running queries is all fine and dandy, but you usually care about the result of queries as well or at least would like to know, if they succeeded.
Then you encounter the problem, that the order of magnitude for query runtime in Athena is not milliseconds, rather seconds and minutes - up to a limit of 30 minutes. This is a problem, because the Lambda execution limit is currently at 15 minutes and long running Lambdas aren’t cool anyways.
(If you only have short running queries, let’s say up to 5 minutes and you know that beforehand, you can skip the section for short running queries)
Enter: Step Functions. Yes I know, having to use yet another service isn’t ideal, but there are two limitations with Athena:
- There is no Lambda trigger, when the query terminates
- There is no other integration like SNS or SQS for queries that finish
You could summarize it as: Athena lacks integration for the result of queries (if I have overlooked something, please let me know!).
If you haven’t yet encountered Step Functions: step functions help you automate workflows that include several AWS services - you define your workflow as a state machine and AWS takes care of orchestrating your resources in the order and with the constraints you specified.
I usually use this pattern in my step functions:
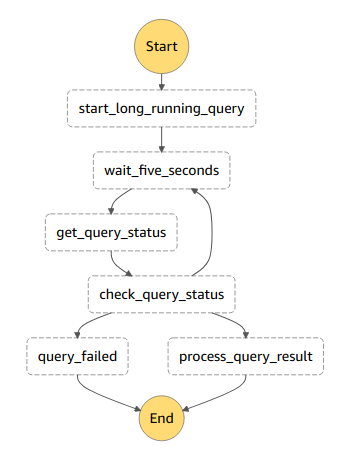
A lambda function starts the long running Athena query, then we enter a kind of loop. First of all, a wait step pauses the execution, then another lambda function queries the state of the query execution. A choice-step (wording?) checks if the query has succeeded, if yes - we continue. If it’s still running, we move back to the waiting step (adding error-handling is trivial here).
You can find a sample project with the code for all of the functions on Github. To make life easier for myself I wrote the athena_helper.py mini-library, which wraps some on the annoying parts of the API.
Now I’m going to show you first of all the code for long running queries and afterwards a simplified version for short queries.
Automating Athena
Long running queries
As mentioned above, there are 3 Lambda functions involved in this. We’re going to start with the function that executes the query:
def start_long_running_query(event, context):
# This is the default table
query = "select * from elb_logs limit 1"
database_name = "sampledb"
# Build the name of the default Athena bucket
account_id = BOTO_SESSION.client('sts').get_caller_identity().get('Account')
region = BOTO_SESSION.region_name
result_bucket = "s3://aws-athena-query-results-{}-{}/".format(account_id, region)
my_query = AthenaQuery(query, database_name, result_bucket)
query_execution_id = my_query.execute()
# This will be processed by our waiting-step
event = {
"MyQueryExecutionId": query_execution_id,
"WaitTask": {
"QueryExecutionId": query_execution_id,
"ResultPrefix": "Sample"
}
}
return event
This functions sets up the relevant parameters for the query:
query- the query itselfdatabase_name- the name of the schema the query is executed inresult_bucket- this builds the name of the result bucket that gets created by default
The actual code for executing the query is just two lines, we build the AthenaQuery object and call execute() on it and receive the execution id of the query:
my_query = AthenaQuery(query, database_name, result_bucket)
query_execution_id = my_query.execute()
Afterwards we build the object that gets passed to the next step. Passing down the Query Execution Id would be sufficient, but I like stats.
The next Lambda function is considerably simpler, it takes the QueryExecutionId out of the input event, builds an AthenaQuery object from it and retrieves the current status of the query.
def get_long_running_query_status(event, context):
query_execution_id = event["WaitTask"]["QueryExecutionId"]
aq = AthenaQuery.from_execution_id(query_execution_id)
status_information = aq.get_status_information()
event["WaitTask"]["QueryState"] = status_information["QueryState"]
status_key = "{}StatusInformation".format(event["WaitTask"]["ResultPrefix"])
event[status_key] = status_information
return event
A choice-step in the step function processes this - you can find the full definition in the serverless.yml of the project, but here is an excerpt of it:
check_query_status:
Type: Choice
Choices:
- Or:
- Variable: "$.WaitTask.QueryState"
StringEquals: FAILED
- Variable: "$.WaitTask.QueryState"
StringEquals: CANCELED
Next: query_failed
This basically tells the state machine to go to the error state query_failed when the query FAILED or is in status CANCELED.
We only get to the next step, if the query has succeeded. This Lambda again builds the AthenaQuery object from the QueryExecutionId and retrieves the result:
def get_long_running_result(event, context):
query_execution_id = event["MyQueryExecutionId"]
# Build the query object from the execution id
aq = AthenaQuery.from_execution_id(query_execution_id)
# Fetch the result
result_data = aq.get_result()
# Do whatever you want with the result
event["GotResult"] = True
return event
Inside of this function you can process the results the way you want. This is how you can deal with long running Athena-queries in Lambda.
Let’s have a look at the much simpler case now: short running queries:
Short running queries
I’d recommend this for queries that run for up to 5 minutes - otherwise it’s probably worth setting up the state machine as described above.
The code for this one relies on the athena_helper.py as well:
import boto3
from athena_helper import AthenaQuery
BOTO_SESSION = boto3.Session()
def short_running_query(event, context):
# Build the name of the default Athena bucket
account_id = BOTO_SESSION.client('sts').get_caller_identity().get('Account')
region = BOTO_SESSION.region_name
result_bucket = "s3://aws-athena-query-results-{}-{}/".format(account_id, region)
my_query = AthenaQuery(
"select elb_name from elb_logs limit 1",
"sampledb",
result_bucket
)
my_query.execute()
result_data = my_query.get_result()
# Process the result
return result_data
This uses the same functions that have been described above, only without the waiting step in between - the get_result() function will actually wait for the query to finish - up to a timeout that’s by default set to 60 seconds.
Conclusion
In this post I’ve shown you how to use the athena_helper mini-library to work with long-running and short-running Athena queries in python.
If you have any questions, feedback or suggestions, feel free to reach out to me on Twitter (@Maurice_Brg)
Photo by Hitesh Choudhary on Unsplash