EKS Backup with Velero
Velero is a tool to backup the kubernetes cluster state and its persistent volumes. It can be used for disaster recovery or cluster migration. Please refer to the official documentation for a more comprehensive description of use cases. This article describes the baseline setup for the backup to ease the start of backing up your EKS clusters.
Reference Architecture
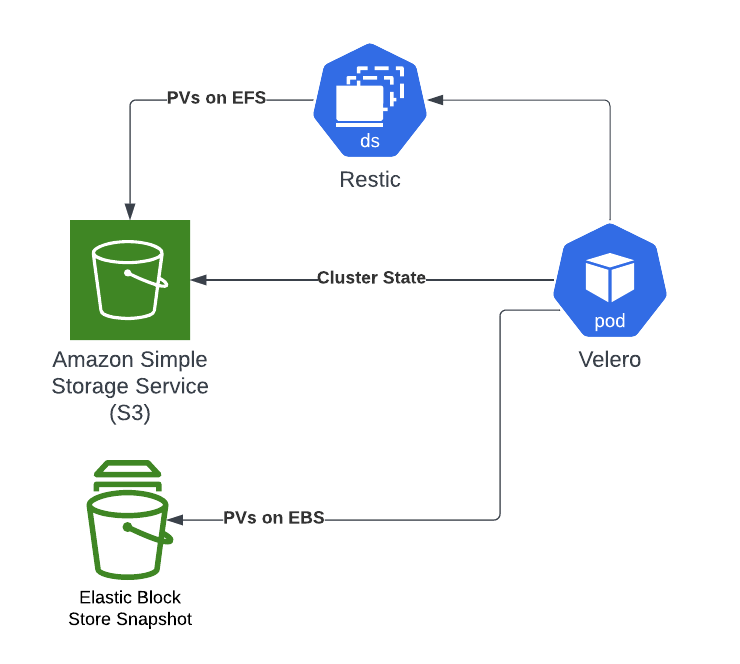
Velero uses a number of CRDs for backup configuration. Most important for backups are the Backup resource for on-demand backups and the Schedule resource for regular backups. Restores can be performed using the Restore CRD. Backups are stored in BackupStorageLocations (etcd backups for all API objects) and VolumeSnapshotLocations (for cloud-native persistent volume snapshot), and there is one default for each.
The kubernetes cluster state is backed up in S3 (the BackupStorageLocation). That S3 bucket should be properly secured as it contains files with everything, including secret values for example. EBS volumes can only be backed-up as EBS snapshots (the VolumeSnapshotLocation). For persistent volumes that are not on EBS (e.g. EFS), Velero uses the integrated file backup tool Restic to perform the backups. If enabled, Restic runs as a pod on each node (managed by a DaemonSet). Volume backups performed by Restic are stored in the BackupStorageLocation.
A Backup or a Schedule that includes all resources and volumes will also include emptyDir volumes. It should be carefully considered if that really makes sense. Usually, it makes for sense to disable automatic backups of volumes and only enabling them for specific volumes using annotations (also refer to Velero Docs - Restic Integration).
Installing Velero
We recommend using the official helm chart for installing velero, for example by using the command below:
helm install velero vmware-tanzu/velero \
--namespace <YOUR NAMESPACE> \
--create-namespace \
--set-file credentials.secretContents.cloud=<FULL PATH TO FILE> \
--set configuration.backupStorageLocation[0].name=<BACKUP STORAGE LOCATION NAME> \
--set configuration.backupStorageLocation[0].provider=<PROVIDER NAME> \
--set configuration.backupStorageLocation[0].bucket=<BUCKET NAME> \
--set configuration.backupStorageLocation[0].config.region=<REGION> \
--set configuration.volumeSnapshotLocation[0].name=<VOLUME SNAPSHOT LOCATION NAME> \
--set configuration.volumeSnapshotLocation[0].provider=<PROVIDER NAME> \
--set configuration.volumeSnapshotLocation[0].config.region=<REGION> \
--set initContainers[0].name=velero-plugin-for-<PROVIDER NAME> \
--set initContainers[0].image=velero/velero-plugin-for-<PROVIDER NAME>:<PROVIDER PLUGIN TAG> \
--set initContainers[0].volumeMounts[0].mountPath=/target \
--set initContainers[0].volumeMounts[0].name=plugins
Aside velero running inside the EKS cluster, a few more things are required:
- An S3 bucket to be used at as the BackupStorageLocation (etcd and Restic backups)
- An AWS IAM role that velero uses to access AWS services (S3, plus EBS for volume snapshots). EKS IRSA (IAM Roles for Service Accounts) is the easiest and safest way to grant access to AWS services to appliations running in EKS. The permissions that velero requires are documented here.
To integrate these resources properly with the helm chart and avoid copy-pasting identifiers between the helm charts and the AWS resources, we recommend using terraform for scripting all kubernetes (including helm) and AWS resources or another IaC tool that is compatible with both “worlds”.
Examples
The following resources creates a backup Schedule that will perform backups on all resources in the velero-test-environment namespace every 5 seconds. The backups have a retention of 30 minutes. For more details, refer to the docs.
apiVersion: velero.io/v1
kind: Schedule
metadata:
name: velero-test-environment
namespace: velero # must be namespace of velero server
spec:
schedule: '*/5 * * * *'
template:
includedNamespaces:
- "velero-test-environment"
includedResources:
- "*"
ttl: 30m
The following resource will restore the latest backup from above schedule into a new namespace called velero-test-environment-restored. Again, check the docs for detailed information.
apiVersion: velero.io/v1
kind: Restore
metadata:
name: velero-test-environment
namespace: velero # must be namespace of velero server
spec:
includedNamespaces:
- "velero-test-environment"
includedResources:
- "*"
namespaceMapping:
velero-test-environment: velero-test-environment-restored
restorePVs: true
backupName: ""
scheduleName: velero-test-environment
existingResourcePolicy: update
Testing
- Create the namespace velero-test-environment namespace in an EKS cluster and some kubernetes resources (e.g. deployments, configmaps, secrets) inside it.
- Create the Schedule from the examples above.
- Over the next few minutes, make some changes to the resources in the namespace and then wait another 1-2 minutes.
- At some point, create the Restore resource from the example above to trigger a restore.
- Verify that the new namespace velero-test-environment-restored has been created and that it contains the correct state of the restored resources. Also ensure that everything is functional as in the original namespace.
Taking it to production readiness
Just installing velero is clearly not enough. Backup and disaster recovery is a complex topic that goes far beyond what has been described in this article. In a real-life scenario, one should think about the two main drivers for a disaster recovery strategy:
- Recovery Point Objective (RPO): In case of an outage, how much data loss can we afford?
- Recovery Time Objective (RTO): In case of an outage, how fast do we need to restore data and get the system running again?
Both questions impact your system design and also your backup schedules. Backup and recovery must always be tested to ensure that they are actually working. Recovery testing should not be performed on the same infrastructure, but also cover the necessity to move the system to another / a new infrastructure. Consequently, replication of the backups to a second AWS region is worth considering as well in order to faciliate a full restore even in the unlikely event of an AWS region wide outage.