Livestreaming with Amazon IVS
When thinking about live streaming, most of us will think about streaming providers like Netflix. Thus we are just consuming their media content like series or films. But what about offering live video streams internally, for your customers or others?
In the past, there were tools like the (Wowza Streaming Engine)[https://www.wowza.com/]. Those tools must be installed on an EC2 instance with the necessary bandwidth and pricing. But what if there is a much easier solution that does not need any maintenance and to deliver a video stream ad-hoc within minutes? Here we go: Amazon Interactive Video Service.
What is Amazon IVS?
Amazon Interactive Video Service (IVS) is a managed, live-video streaming service with ultra-low latency. It handles everything from video ingesting and transcoding to global distribution for playback, so you can focus on building your own interactive application and audience experience. With Amazon IVS, you can stream without needing to manage or develop components on your own.
These are the words mentioned in the first sentences within the official documentation. It reflects everything and nothing. So let’s focus on the first half of the information: the live video streaming with video ingesting and transcoding.
I will guide you through the steps to establish your first live stream with AWS and your laptop/computer/smartphone with a webcam integrated or attached.
Guide
To start the first stream, we must create a Channel for that in Amazon IVS.
- Login yourself to the AWS Management Console.
- Go to the Service named
Amazon Interactive Video Service - On the left side, open the menu and click on
Channels - Click on
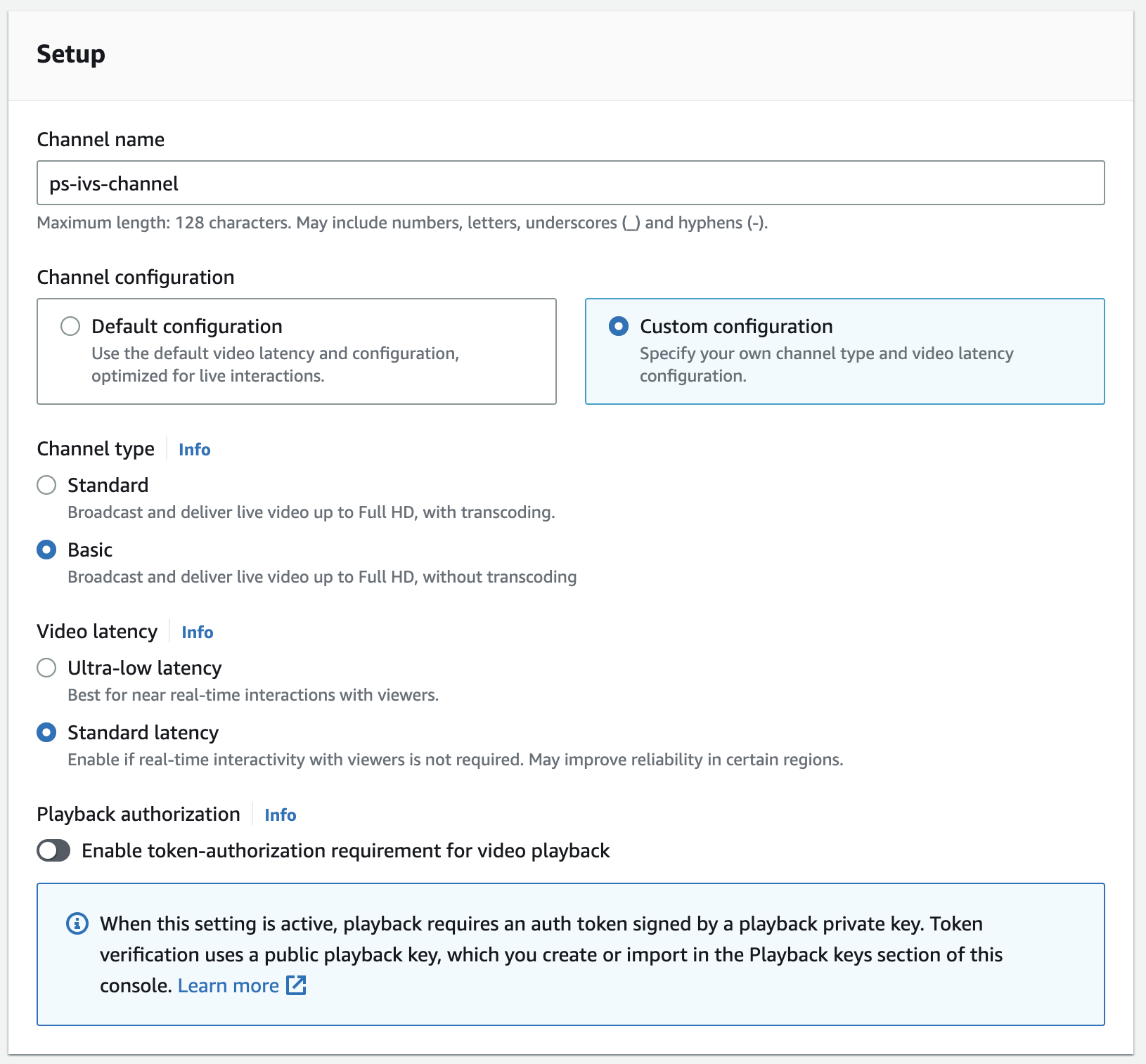
Create channeland fill out the basic information- Channel name:
ps-ivs-channel - Channel configuration:
Custom configuration- Channel type:
Basic - Video latency:
Standard latency
- Channel type:
- Channel name:
You could leave all settings pre-defined, but for my channel, I am choosing the free tier settings that allow me to deliver 5 hours of live video input to IVS each month.
If you want to, you can also record your stream to S3 (not covered in this post)
When you create your channel, you are automatically redirected to the channel information; go to the “Stream configuration” section and see your stream key and ingest server. Both are important for your live stream in the next step.
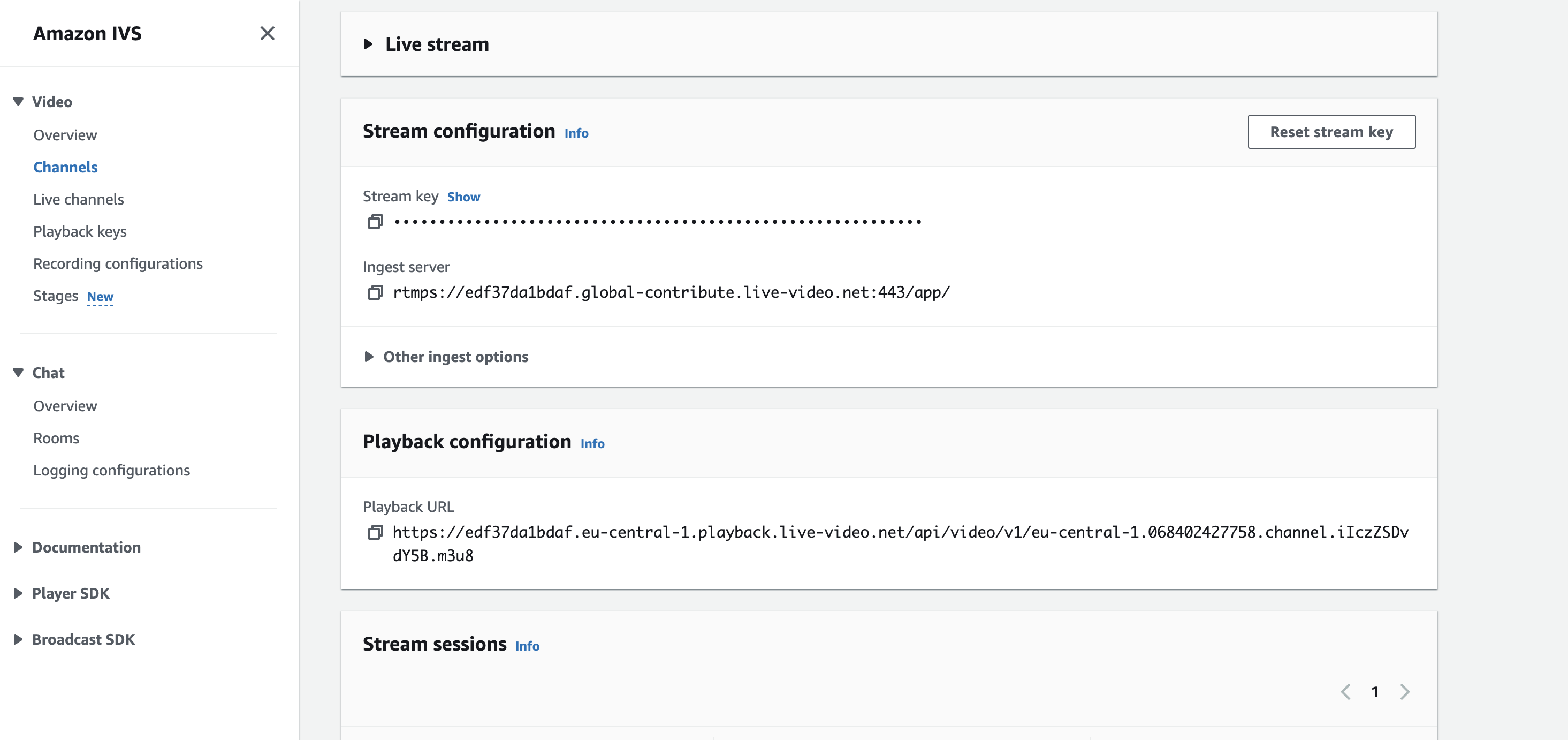
We now have our own streaming channel available, and it waits for you to start your stream.
To start your first stream, go to the Web Broadcast Website that AWS Samples offers. The website contains all the necessary parts to start your stream.
Let’s configure our stream. To do so, click on the gear icon ⚙ which is located in the bottom area next to the Start streaming button.

We have to add the same settings as we did within the AWS Management Console:
- Webcam and Mic: This is already set and can be adjusted, if necessary
- Channel type:
Basic - Ingest endpoint:
rtmps://edf37da1bdaf.global-contribute.live-video.net:443/app/ - Stream key:
sk_eu-central-1_3TF0zPIjqGXU_EfMv4JKjomPqfF08V0hT9hrRshJ8t4
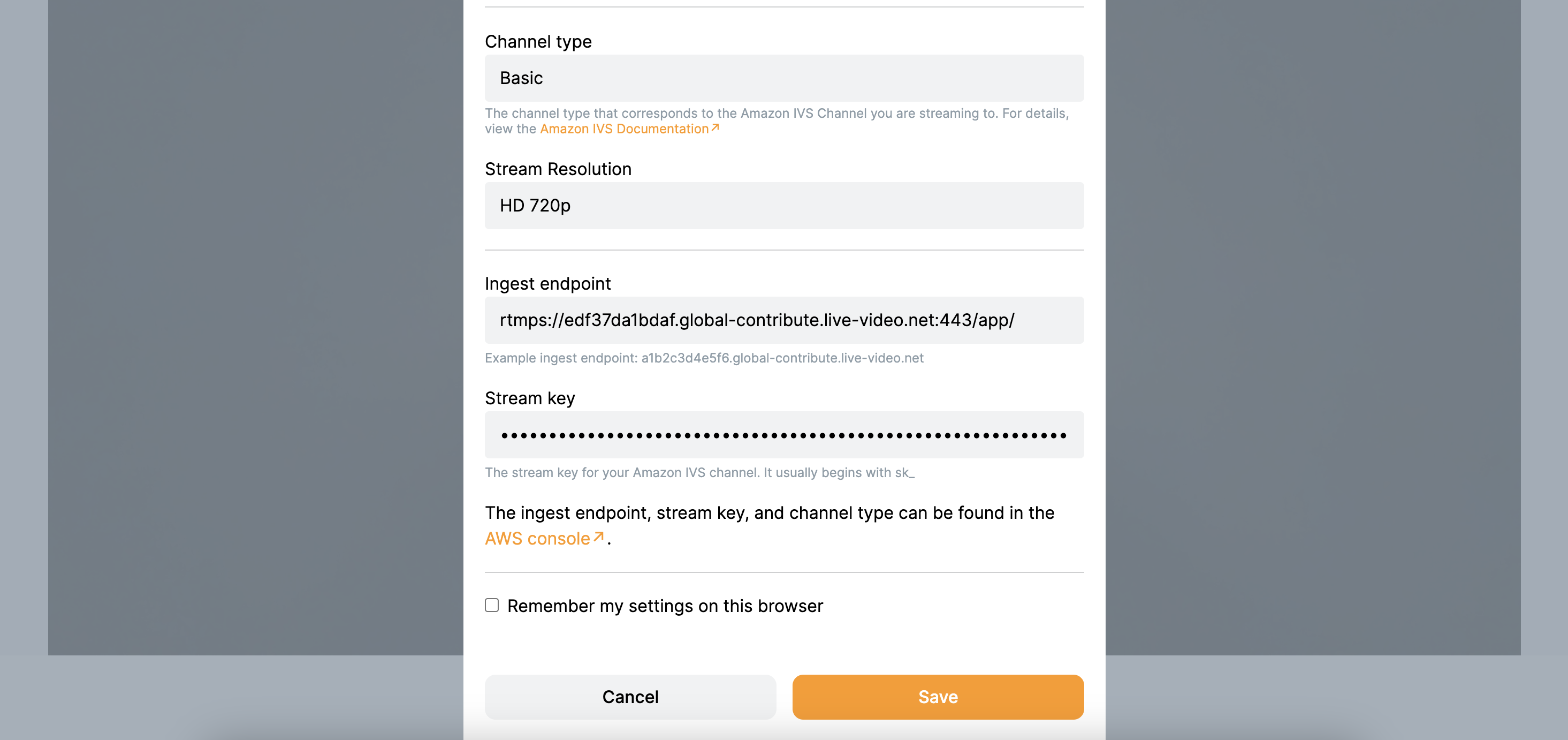
Save the settings and click on Start stream
We are live!!!
To check if it works, go back to your last opened browser tab with your AWS Management Console with the channel information and do a reload, if necessary.
You can now actually see the live stream and get more information about the current live stream like
- How many users are streaming?
- Is the stream still live?

Everyone loves statistics. So let’s take a look into this as well.
We are still on the same page and scroll to the section named Stream sessions and click on the only open session.
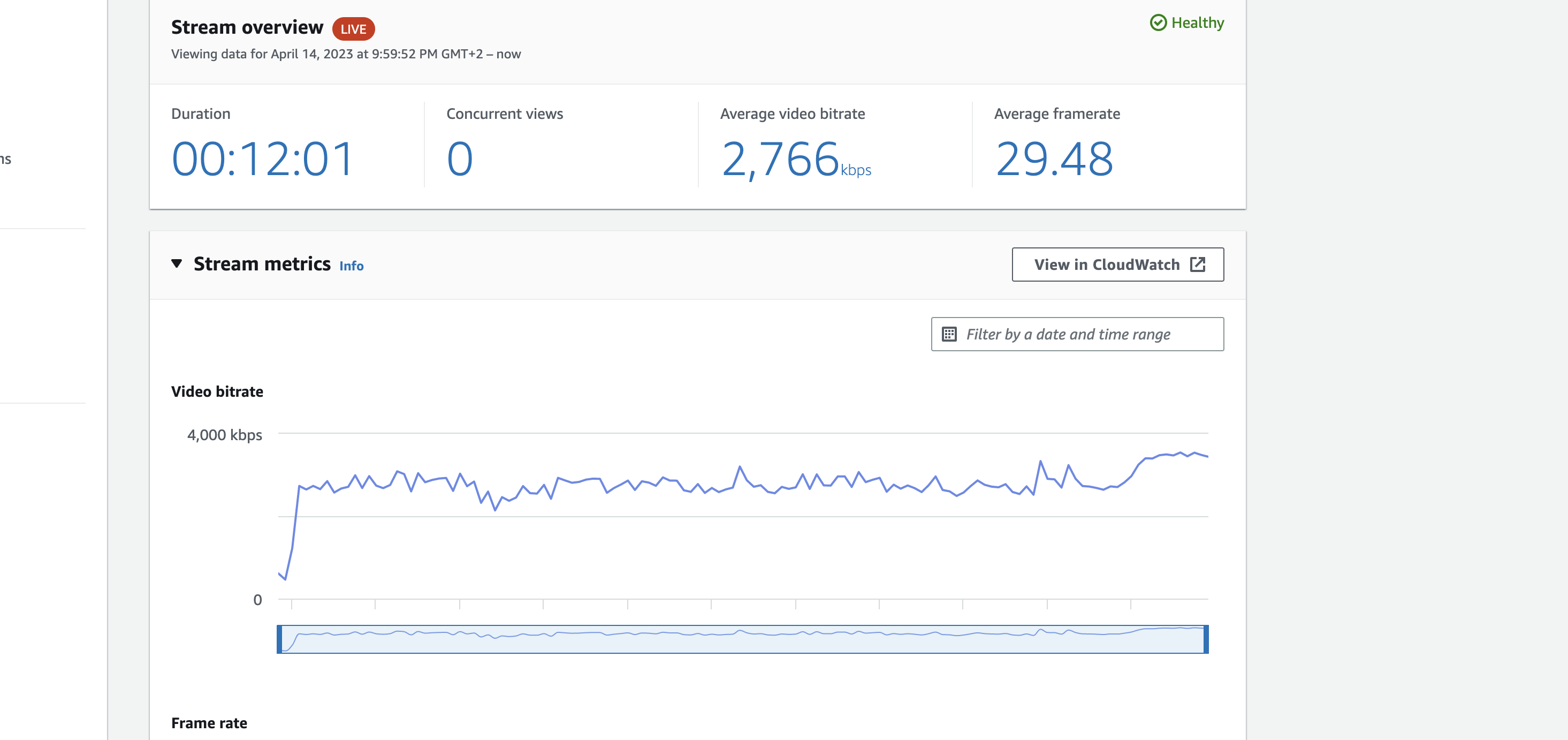
It opens a new site, and we will get a lot of nice stream information like:
- video bitrate
- frame rate
- audio bitrate
- min and max value for them
- events like start and stop
- the encoder settings from your software or tool you are using or the IVS Web Broadcast Website
As initially said, this is just a small piece of live streaming you can do with AWS. With IVS, you can extend your stream with “Stages”, Chat functionality, and more.
More info
- https://docs.aws.amazon.com/ivs/latest/userguide/broadcast-web.html
- https://ivs.rocks/
- during the test (standard latency) there was a 7 seconds delay in the stream
- during the test (ultra-low latency) there was a maximum of 2 seconds delay in the stream
- the stream can be stopped in the AWS Management Console (this is more like a killswitch for the stream as the streamers side does not recognize this)
— Patrick