Jump off the @Edge - CloudFront Functions
Have you ever heard about CloudFront Functions as an alternative to Lambda@Edge when doing redirects within CloudFront? In this post I will give you an example of the different steps for an implementation of both variants with the same result.
What does a Lambda@Edge do for CloudFront?
To give you an answer to this question, I’d like to give you an example in advance:
Let’s assume you have a blog, and all static files are located on S3, created by Hugo through a CI/CD Pipeline, and delivered to the readers through CloudFront.
So it looks something like this:
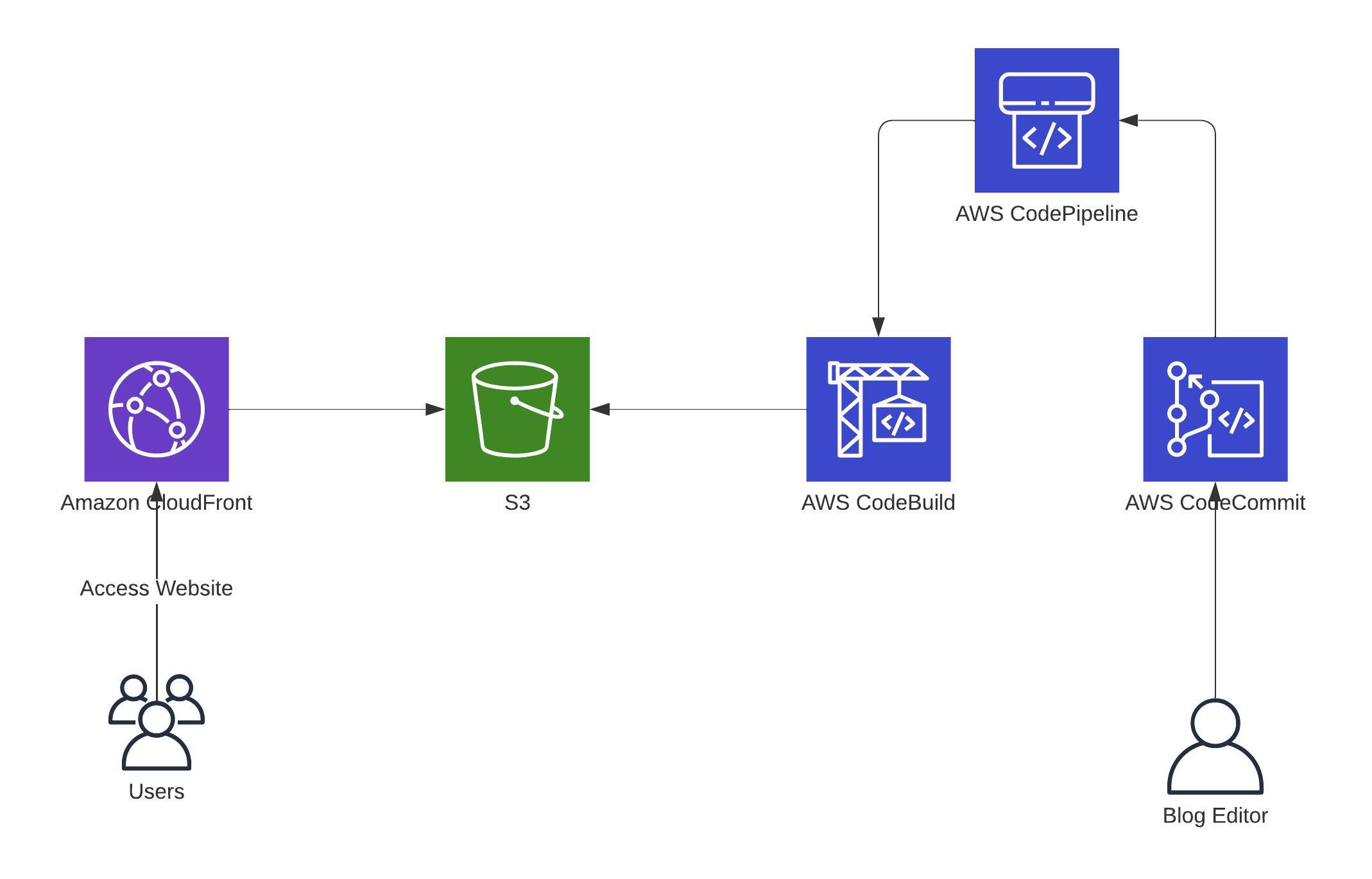
Until now, everything looks fine. When a user now opens the blog that is behind a CloudFront, the problem starts: a typical web server defaults to an index.html file. But as you know, CloudFront is not a web server and isn’t aware of that kind of file.
So whenever you are opening an URL, even when it’s the root of your domain, it will print out an XML error from S3. Adding the /index.html to your browser’s address will show the correct site.
People now might think: Okay, then don’t use CloudFront.
A typical reply is: No, just use Lambda@Edge for that. It helps you with that problem.
It sounds like a good answer right now, but let’s look a bit deeper into it.
There are several sources (e.g., in the official AWS Blogs) for developing a redirect for that with Lambda@Edge. You can add the Lambda@Edge function as the Origin request in your CloudFront when created.
I’m not going into too much detail here about what a Lambda@Edge function is and how it exactly works. Still, you can think about it as a Lambda function that is deployed into one of the Regional Edge Caches of CloudFront and can be executed there.
When your Lambda@Edge is deployed the right way and it works, you can open the blog without adding an index.html to your browser’s address.
Why am I telling you something about Lambda@Edge?
Well, I always liked the idea of running a Lambda function within CloudFront, and it felt good. A Lambda function can access a VPC, file systems, and I know what it does because I’ve already used it for years and also wrote them in different programming languages like Python, Node.js and Ruby.
Beside the integration into your infrastructure, Lambda@Edge does not require management of virtual machines that would include provisioning, patching, hardening and multi-location setups. You only have to keep your codebase up2date to prevent running code in a deprecated runtime.
For such an upwards compatability check you only need a small Continuous Integration pipeline that checks your code to see if your Lambda@Edge function still works in future runtimes.
In other words: it is generally easy to handle and I am still happy with it.
Lambda@Edge is a great way of solving the problem stated above. But as initially said, there is another not-so-well-known solution for this: CloudFront Functions.
What are CloudFront Functions?
A CloudFront Function has, in this case, the same abilities as a Lambda@Edge Function but costs 1/6 of a Lambda@Edge function. Plus: It runs much faster within all 218+ CloudFront Edge locations. This means it is nearer to every user than a Lambda@Edge function.
So, for example, the maximum execution time is less than 1 millisecond, and it can easily handle 10,000,000 requests per second. And this is not everything: it can give you additional benefits, which you can see in the table under the headline What should I choose for my own problem? below.
The whole code for an URL-rewrite is just some lines long and has more or less the same code as a Lambda@Edge Function would have.
Of course there are also some disadvantages in here, which I have to mention: the code needs to be in JavaScript (ECMAScript 5.1 compliant) and the resources it can use are very limited.
The limitation in regards to the code is huge, at least for me. I am not one of the best Node.js programmer, nor I know what Javascript (ECMAScript 5.1 compliant) exactyly means. For this you need a lot of experience and knowledge about older versions and the changes during versions. So in my case I added an internal developer to my problem who coded nearly his whole lifetime with Node.js / Javascript and knows how to write the code accordingly.
Give me the solution for the redirect in real-life, step by step!
Let’s start with the code. This time with CloudFront Functions.
The code uses the event and sets two variables. From there on it checks and updates the original request and returns the final request, if everything is fine.
function handler(event) {
var request = event.request;
var uri = request.uri;
// Check whether the URI is missing a file name.
if (uri.endsWith('/')) {
request.uri += 'index.html';
}
// Check whether the URI is missing a file extension.
else if (!uri.includes('.')) {
request.uri += '/index.html';
}
else if (!uri.includes('')) {
request.uri += '/index.html';
}
return request;
}
To add this now as a CloudFront function, you have to go to CloudFront and within that to Functions.
- Click on
Create functionand add a name for it (no spaces; letters, numbers, hyphens, and underscores are allowed) andCreate - Paste the code from above into the
Function codefield andSave changes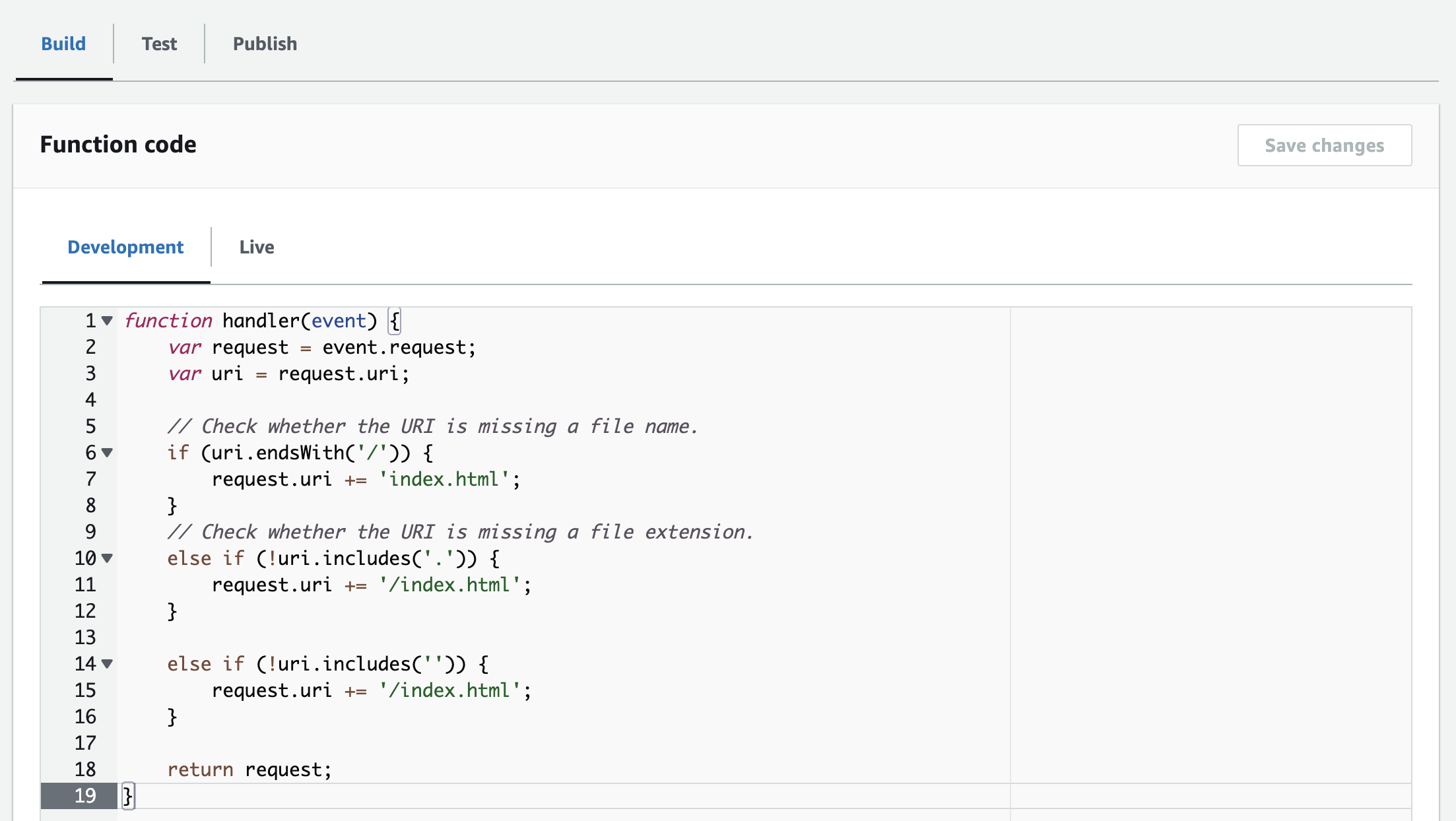
- Go to the
Publishtab and click onPublish function(this is required to allow an association within CloudFront)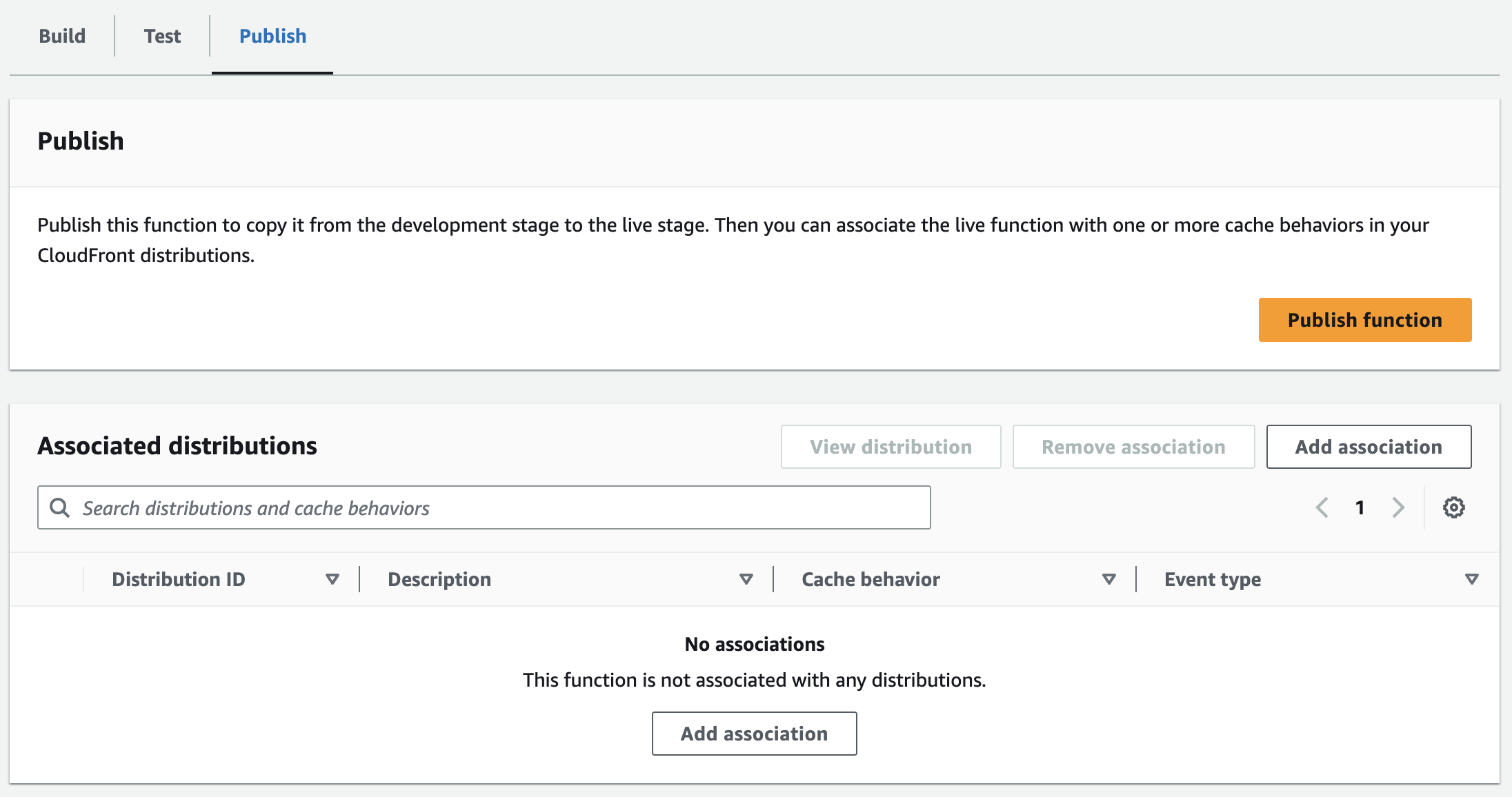
- Click on
Add association- choose your CloudFront Distribution
- Add
Viewer Requestas Event Type - Choose your desired Cache Behavior
- Click again on
Add association
- Now, the CloudFront Distribution redeploys itself until it has the status
Deployedagain.
This is everything you need to do and you are ready to take a look into Lambda@Edge.
How would a Lambda@Edge function look like?
The Lambda@Edge function would look similar, just written in your preferred coding language (Node.js or Python) in Lambda.
In my case we relied in the past on a Node.js function and the source code from a GitHub project.
const config = {
suffix: '.html',
appendToDirs: 'index.html',
removeTrailingSlash: false,
};
const regexSuffixless = /\/[^/.]+$/; // e.g. "/some/page" but not "/", "/some/" or "/some.jpg"
const regexTrailingSlash = /.+\/$/; // e.g. "/some/" or "/some/page/" but not root "/"
exports.handler = function handler(event, context, callback) {
const { request } = event.Records[0].cf;
const { uri } = request;
const { suffix, appendToDirs, removeTrailingSlash } = config;
// Append ".html" to origin request
if (suffix && uri.match(regexSuffixless)) {
request.uri = uri + suffix;
callback(null, request);
return;
}
// Append "index.html" to origin request
if (appendToDirs && uri.match(regexTrailingSlash)) {
request.uri = uri + appendToDirs;
callback(null, request);
return;
}
// Redirect (301) non-root requests ending in "/" to URI without trailing slash
if (removeTrailingSlash && uri.match(/.+\/$/)) {
const response = {
headers: {
'location': [{
key: 'Location',
value: uri.slice(0, -1)
}]
},
status: '301',
statusDescription: 'Moved Permanently'
};
callback(null, response);
return;
}
// If nothing matches, return request unchanged
callback(null, request);
};
This is a total of 36 lines of real code (comments and empty lines are not counted). The same functionality just as a CloudFront function contains 14 lines of real code.
To add this now to your CloudFront, you have to go to the us-east-1 region and within that to Lambda into the Functions.
- Click on
Create function, selectAuthor from Scratchand add a name for it, choose Node.js 12.x as the runtime and click onCreate function - Paste the code from above into the
Code sourceinput andDeploy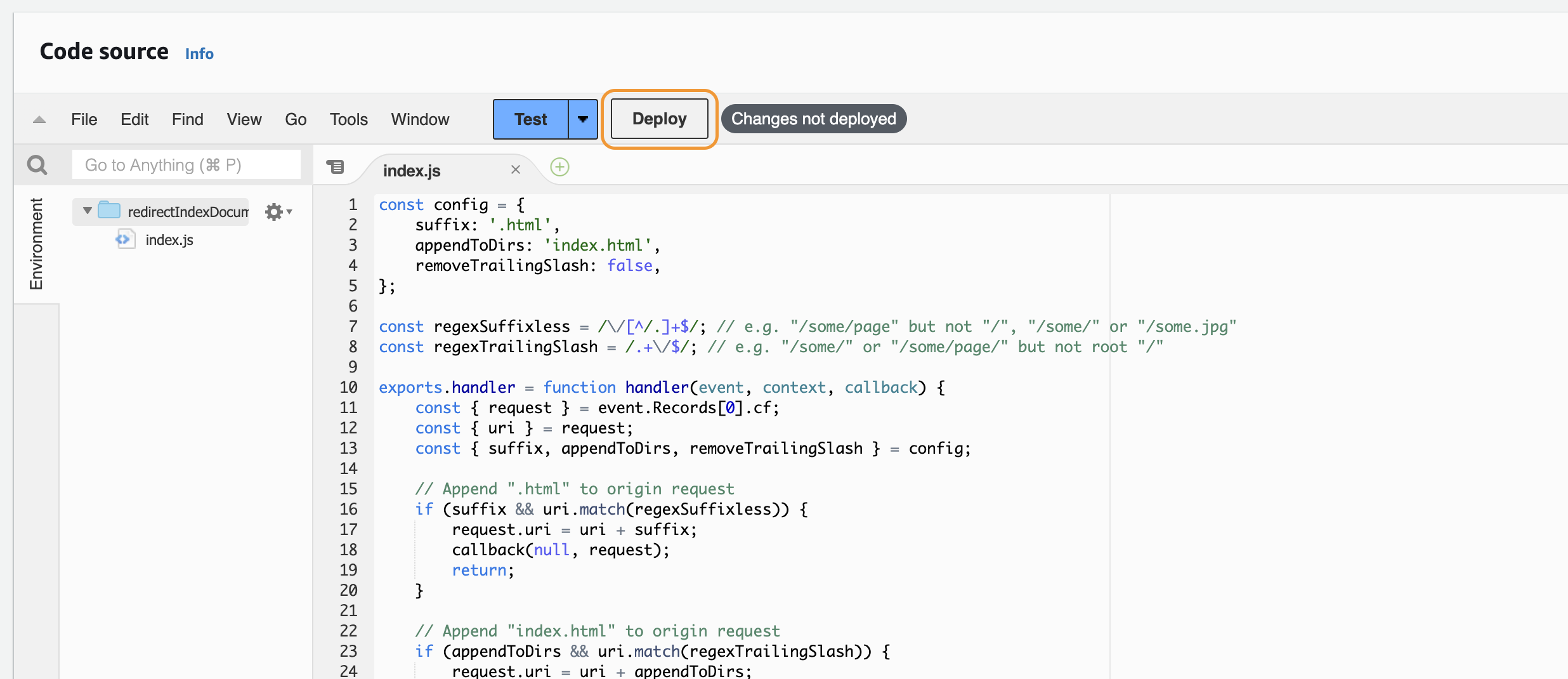
- Scroll up and select Actions > Deploy to Lambda@Edge
- Configure your Distribution, Cache behavior, the CloudFront event, enable the checkbox for
Confirm deploy to Lambda@Edge, and click on Deploy - Now, the Lambda@Edge is deployed and the CloudFront Distribution is updated until it has the status
Deployedagain.
What should I choose for my own problem?
In general we can say: Using Lambda@Edge or CloudFront Functions is always based on your requirement and problem statement. No one can say: use this.
In my case using a CloudFront Function is the easiest and fastest way of a redirect implementation. It brings me all the necessary benefits I need without any runtime updates. So the sentence never touch a running code is true.
When the maximum execution time or the resources of a CloudFront Function are exceeded, I would rely on Lambda@Edge.
Based on your problem statement, your choice could be one or the other. Requirements that might come up are also a good indicator if it disqualifies one. Below is a good overview about the differences from the AWS documentation.
| CloudFront Functions | Lambda@Edge | |
|---|---|---|
| Programming languages | JavaScript (ECMAScript 5.1 compliant) | Node.js and Python |
| Event sources | - Viewer request - Viewer response |
- Viewer request - Viewer response - Origin request - Origin response |
| Scale | 10,000,000 requests per second or more | Up to 10,000 requests per second per Region |
| Function duration | Submillisecond | - Up to 5 seconds (viewer request and viewer response) - Up to 30 seconds (origin request and origin response) |
| Maximum memory | 2 MB | 128 – 3,008 MB |
| Maximum size of the function code and included libraries | 10 KB | - 1 MB (viewer request and viewer response) - 50 MB (origin request and origin response) |
| Network access | No | Yes |
| File system access | No | Yes |
| Access to the request body | No | Yes |
| Access to geolocation and device data | Yes | - No (viewer request) - Yes (origin request, origin response, and viewer response) |
| Can build and test entirely within CloudFront | Yes | No |
| Function logging and metrics | Yes | Yes |
| Pricing | Free tier available; charged per request | No free tier; charged per request and function duration |
Thank you for reading!
— Patrick