The declarative vs imperative Infrastructure as Code discussion is flawed
This content is more than 4 years old and the cloud moves fast so some information may be slightly out of date.
“Infrastructure definition has to be declarative”. Let’s see where this presumption gets us.
My guess why some ops guys prefer pure terraform or CloudFormation is that these languages seem to be easier to understand. There is precisely one way of creating a specific resource in the language. If you use a programming language, there are many ways to solve one specific problem.
The problem which could occur later in the project is that both declarative languages have boundaries in what they can do, with a programming language you do not have these boundaries. One approach to solve this problem is to define a preferred way of doing things in the programming language.
If you have code snippets, e.g. for the vpc in the project an do not add interface layers, dependency injection, redirection etc, then the programming language can be read nearly as easy as a declarative language.
That terraform and cloudformation both have some aspects of the programming languages included like variables, if statements and loops (terraform only) makes them stripped down programming languages.
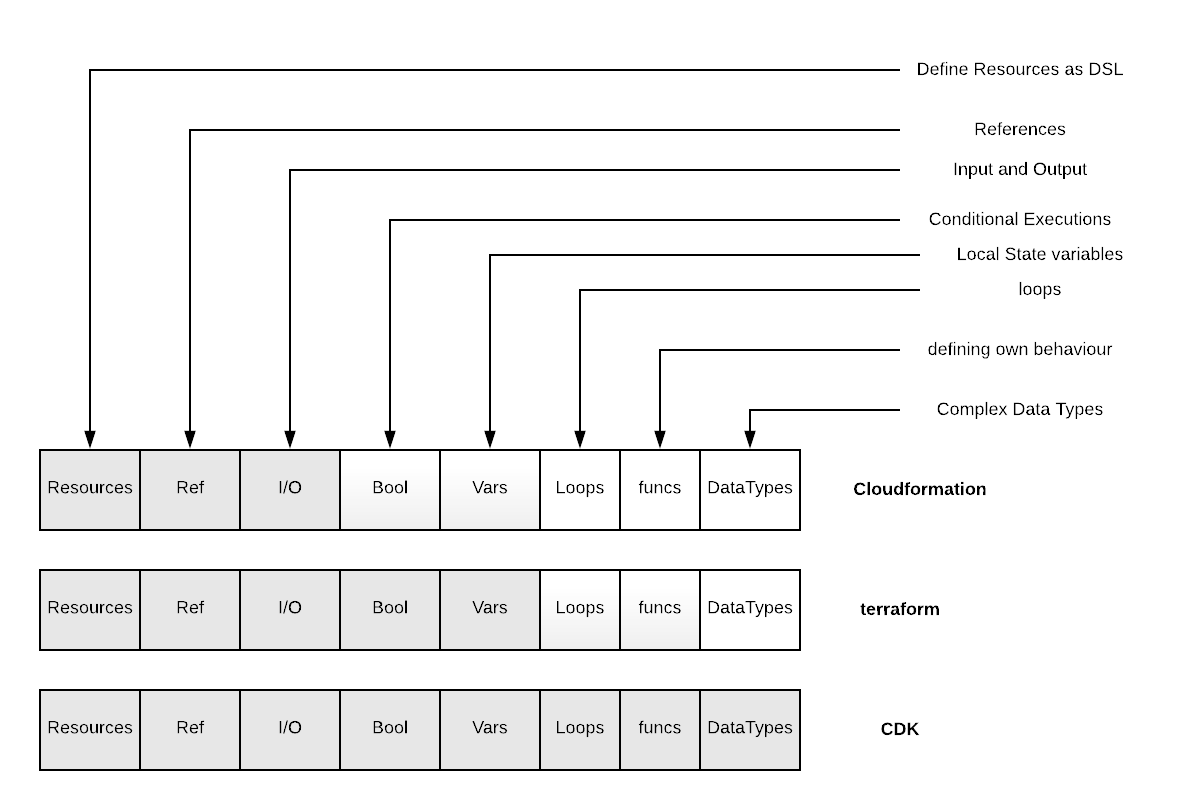
When we look at the features of the two “declarative” frameworks, CloudFormation and terraform, we see that both are evolving towards an programming language. (Terraform with more speed) But they both only implement a small fraction of the programming features, so it seems that they are easier to learn. These restrictions lead to implementing additional features as plugins or external scripting.
With a programming language first approach you do not need some of these plugins or external scripts, because you can script inside the same language.
Definition “Is declarative” could mean the opposite…
What framework is declarative, which is imperative?
That’s an easy question: CloudFormation and Terraform are declarative, CDK is imperative. But only at first glance!
If you provide a lambda resource in terraform, what will happen?
terraform is imperative restricted by declarative HCL
A hcl lambda function like:
resource "aws_lambda_function" "this" {
...
runtime = var.runtime
handler = var.handler
...
}
Will be interpreted by this code:
func resourceAwsLambdaFunction() *schema.Resource {
return &schema.Resource{
Create: resourceAwsLambdaFunctionCreate,
Read: resourceAwsLambdaFunctionRead,
Update: resourceAwsLambdaFunctionUpdate,
Delete: resourceAwsLambdaFunctionDelete,
Aha, terraform is purely imperative… :)
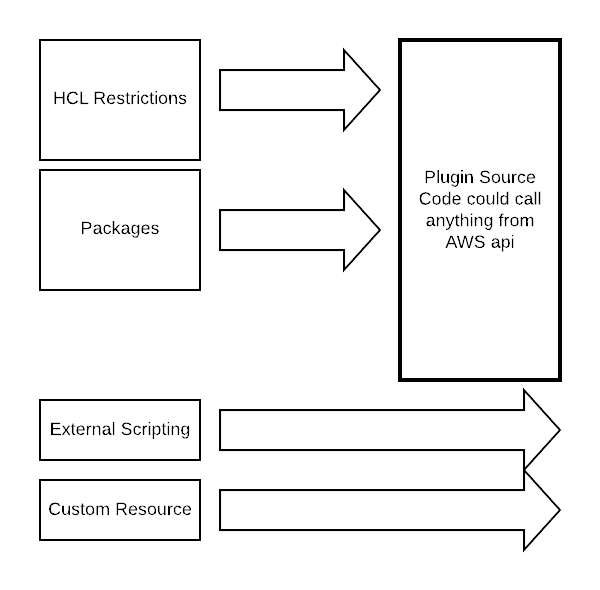
If you want to extend functionality beyond the boundaries of the terraform aAWSws provider, you have to “leave” the terraform domain and add external scripting.
So you could see terraform as an imperative language restricted by a declarative language (hcl).
CDK is declarative broadened by imperative Typescript
In the CDK we define a Lambda function :
new lambda.Function(this, 'HelloHandler', {
...
handler: 'hello.handler',
runtime: lambda.Runtime.NODEJS_10_X,
...
});
which will be translated to something like:
"Type": "AWS::Lambda::Function",
"Properties": {
...
"Handler": "hello.handler",
"Runtime": "nodejs10.x",
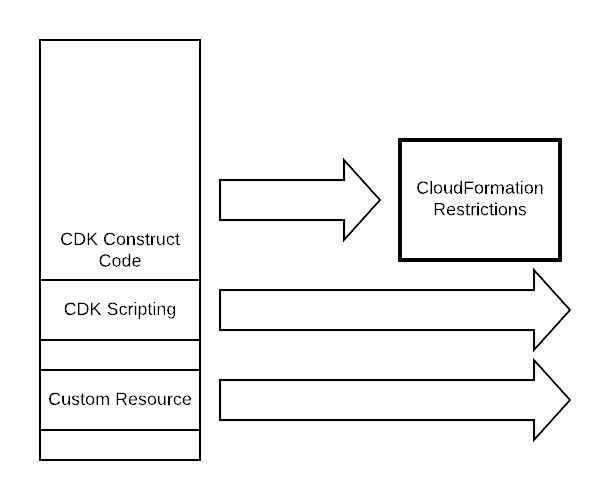
If you have to add some functionality which is not included in CloudFormation, you may implement it directly into the CDK construct source. Jsii could not translate this from typescript with jsii, so you cant use this in your modules But you can have an embedded approach for extended functionality.
Conclusion
So neither is terraform declarative nor is CDK imparative.
So we can move the discussion about which framework fits better to the project more to the point whether the needs of the project are implementable by the framework, which approach would be more agile or just what do you just like more.
Thank you
Image Credits
Photo by Hermes Rivera on Unsplash